 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamMask: A Framework for Fast Online Object Tracking and Segmentation
Jul 05, 2022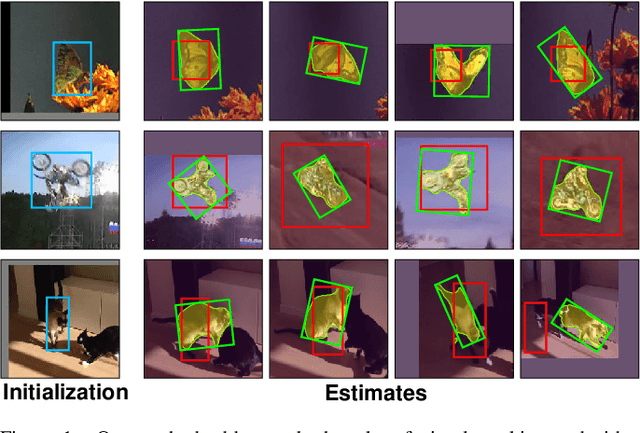
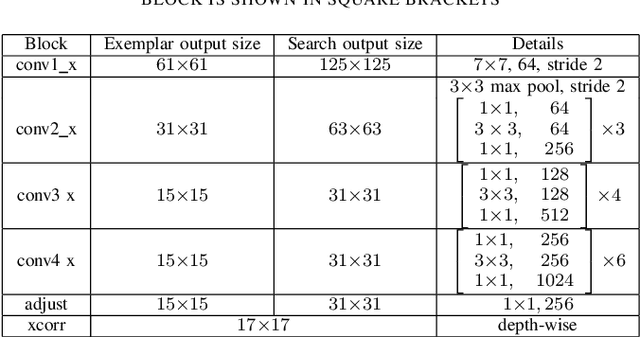

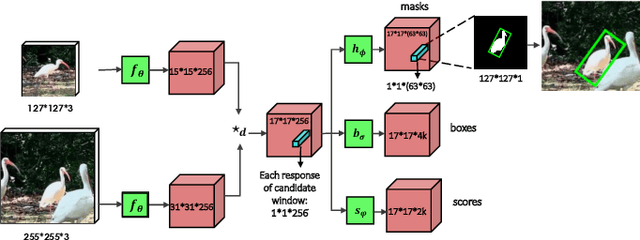
In this paper we introduce SiamMask, a framework to perform both visual object tracking and video object segmentation, in real-time, with the same simple method. We improve the offline training procedure of popular fully-convolutional Siamese approaches by augmenting their losses with a binary segmentation task. Once the offline training is completed, SiamMask only requires a single bounding box for initialization and can simultaneously carry out visual object tracking and segmentation at high frame-rates. Moreover, we show that it is possible to extend the framework to handle multiple object tracking and segmentation by simply re-using the multi-task model in a cascaded fashion. Experimental results show that our approach has high processing efficiency, at around 55 frames per second. It yields real-time state-of-the-art results on visual-object tracking benchmarks, while at the same time demonstrating competitive performance at a high speed for video object segmentation benchmarks.
* 17 pages, Accepted by TPAMI 2022. arXiv admin note: substantial text overlap with arXiv:1812.05050
Attacking deep networks with surrogate-based adversarial black-box methods is easy
Mar 16, 2022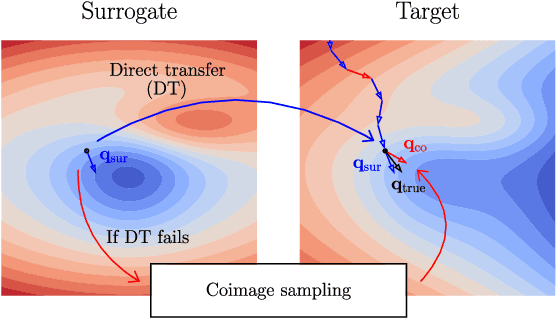
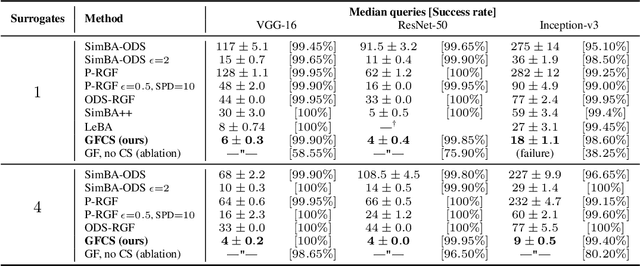
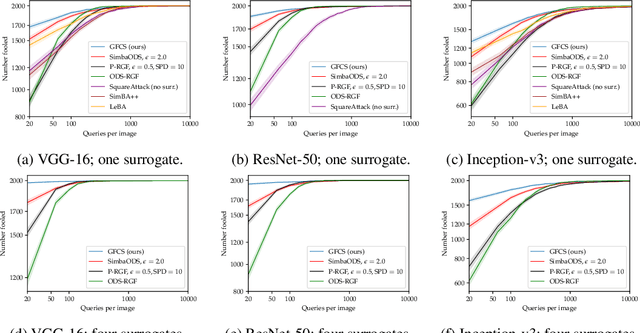
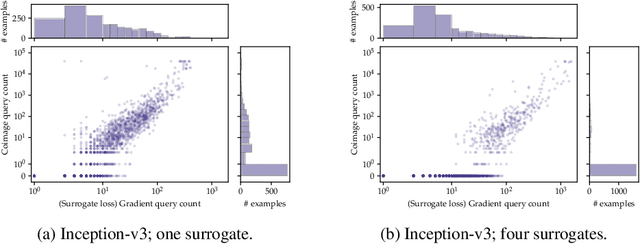
A recent line of work on black-box adversarial attacks has revived the use of transfer from surrogate models by integrating it into query-based search. However, we find that existing approaches of this type underperform their potential, and can be overly complicated besides. Here, we provide a short and simple algorithm which achieves state-of-the-art results through a search which uses the surrogate network's class-score gradients, with no need for other priors or heuristics. The guiding assumption of the algorithm is that the studied networks are in a fundamental sense learning similar functions, and that a transfer attack from one to the other should thus be fairly "easy". This assumption is validated by the extremely low query counts and failure rates achieved: e.g. an untargeted attack on a VGG-16 ImageNet network using a ResNet-152 as the surrogate yields a median query count of 6 at a success rate of 99.9%. Code is available at https://github.com/fiveai/GFCS.
Parameter-free Online Test-time Adaptation
Jan 15, 2022



Training state-of-the-art vision models has become prohibitively expensive for researchers and practitioners. For the sake of accessibility and resource reuse, it is important to focus on adapting these models to a variety of downstream scenarios. An interesting and practical paradigm is online test-time adaptation, according to which training data is inaccessible, no labelled data from the test distribution is available, and adaptation can only happen at test time and on a handful of samples. In this paper, we investigate how test-time adaptation methods fare for a number of pre-trained models on a variety of real-world scenarios, significantly extending the way they have been originally evaluated. We show that they perform well only in narrowly-defined experimental setups and sometimes fail catastrophically when their hyperparameters are not selected for the same scenario in which they are being tested. Motivated by the inherent uncertainty around the conditions that will ultimately be encountered at test time, we propose a particularly "conservative" approach, which addresses the problem with a Laplacian Adjusted Maximum-likelihood Estimation (LAME) objective. By adapting the model's output (not its parameters), and solving our objective with an efficient concave-convex procedure, our approach exhibits a much higher average accuracy across scenarios than existing methods, while being notably faster and have a much lower memory footprint. Code available at https://github.com/fiveai/LAME.
Do Different Tracking Tasks Require Different Appearance Models?
Jul 05, 2021



Tracking objects of interest in a video is one of the most popular and widely applicable problems in computer vision. However, with the years, a Cambrian explosion of use cases and benchmarks has fragmented the problem in a multitude of different experimental setups. As a consequence, the literature has fragmented too, and now the novel approaches proposed by the community are usually specialised to fit only one specific setup. To understand to what extent this specialisation is actually necessary, in this work we present UniTrack, a unified tracking solution to address five different tasks within the same framework. UniTrack consists of a single and task-agnostic appearance model, which can be learned in a supervised or self-supervised fashion, and multiple "heads" to address individual tasks and that do not require training. We show how most tracking tasks can be solved within this framework, and that the same appearance model can be used to obtain performance that is competitive against specialised methods for all the five tasks considered. The framework also allows us to analyse appearance models obtained with the most recent self-supervised methods, thus significantly extending their evaluation and comparison to a larger variety of important problems. Code available at https://github.com/Zhongdao/UniTrack.
On Episodes, Prototypical Networks, and Few-shot Learning
Dec 17, 2020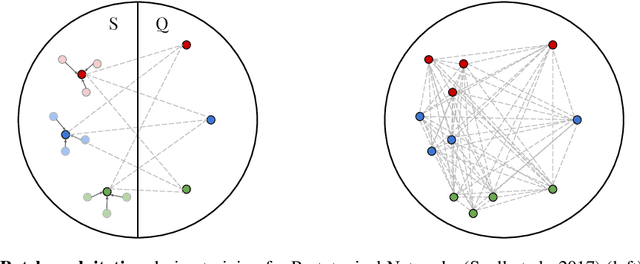
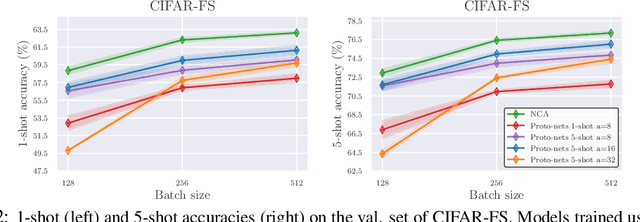
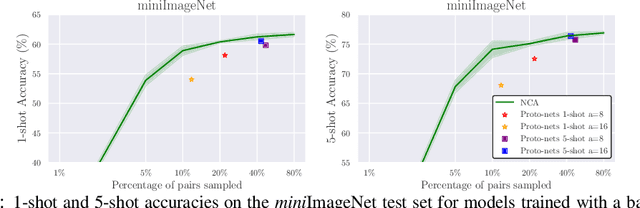
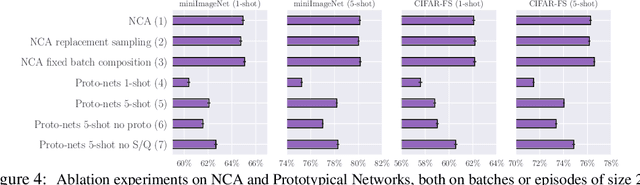
Episodic learning is a popular practice among researchers and practitioners interested in few-shot learning. It consists of organising training in a series of learning problems, each relying on small "support" and "query" sets to mimic the few-shot circumstances encountered during evaluation. In this paper, we investigate the usefulness of episodic learning in Prototypical Networks and Matching Networks, two of the most popular algorithms making use of this practice. Surprisingly, in our experiments we found that, for Prototypical and Matching Networks, it is detrimental to use the episodic learning strategy of separating training samples between support and query set, as it is a data-inefficient way to exploit training batches. These "non-episodic" variants, which are closely related to the classic Neighbourhood Component Analysis, reliably improve over their episodic counterparts in multiple datasets, achieving an accuracy that (in the case of Prototypical Networks) is competitive with the state-of-the-art, despite being extremely simple.
Making Better Mistakes: Leveraging Class Hierarchies with Deep Networks
Dec 19, 2019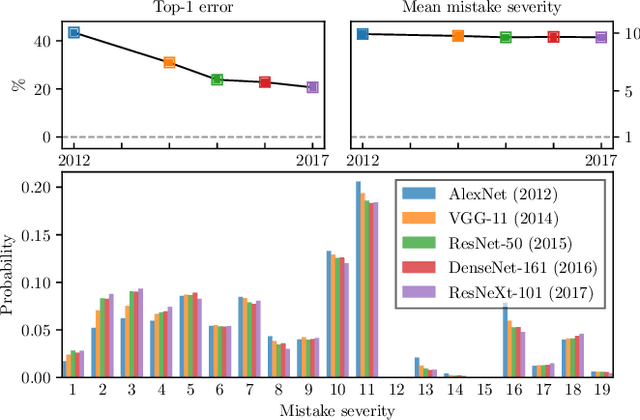
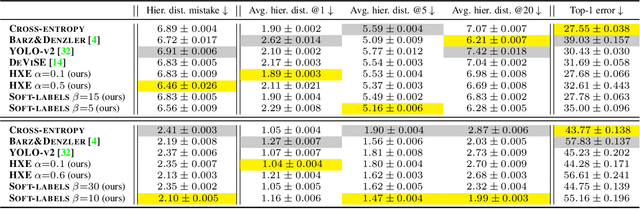
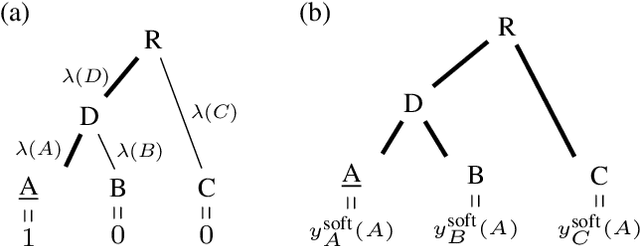
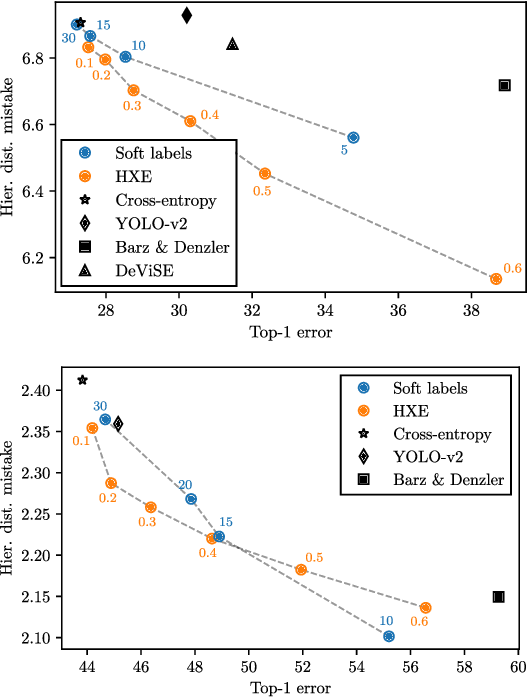
Deep neural networks have improved image classification dramatically over the past decade, but have done so by focusing on performance measures that treat all classes other than the ground truth as equally wrong. This has led to a situation in which mistakes are less likely to be made than before, but are equally likely to be absurd or catastrophic when they do occur. Past works have recognised and tried to address this issue of mistake severity, often by using graph distances in class hierarchies, but this has largely been neglected since the advent of the current deep learning era in computer vision. In this paper, we aim to renew interest in this problem by reviewing past approaches and proposing two simple modifications of the cross-entropy loss which outperform the prior art under several metrics on two large datasets with complex class hierarchies: tieredImageNet and iNaturalist19.
Anchor Diffusion for Unsupervised Video Object Segmentation
Oct 24, 2019


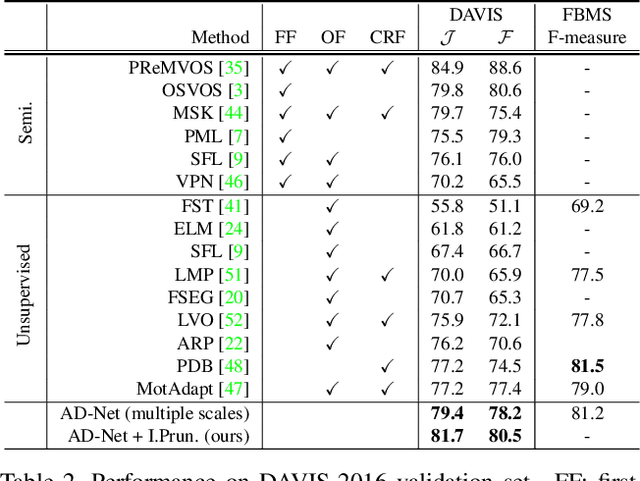
Unsupervised video object segmentation has often been tackled by methods based on recurrent neural networks and optical flow. Despite their complexity, these kinds of approaches tend to favour short-term temporal dependencies and are thus prone to accumulating inaccuracies, which cause drift over time. Moreover, simple (static) image segmentation models, alone, can perform competitively against these methods, which further suggests that the way temporal dependencies are modelled should be reconsidered. Motivated by these observations, in this paper we explore simple yet effective strategies to model long-term temporal dependencies. Inspired by the non-local operators of [70], we introduce a technique to establish dense correspondences between pixel embeddings of a reference "anchor" frame and the current one. This allows the learning of pairwise dependencies at arbitrarily long distances without conditioning on intermediate frames. Without online supervision, our approach can suppress the background and precisely segment the foreground object even in challenging scenarios, while maintaining consistent performance over time. With a mean IoU of $81.7\%$, our method ranks first on the DAVIS-2016 leaderboard of unsupervised methods, while still being competitive against state-of-the-art online semi-supervised approaches. We further evaluate our method on the FBMS dataset and the ViSal video saliency dataset, showing results competitive with the state of the art.
Let's Take This Online: Adapting Scene Coordinate Regression Network Predictions for Online RGB-D Camera Relocalisation
Jun 20, 2019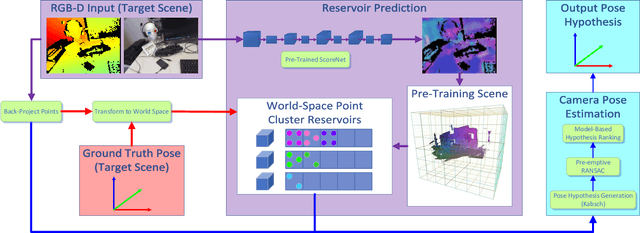
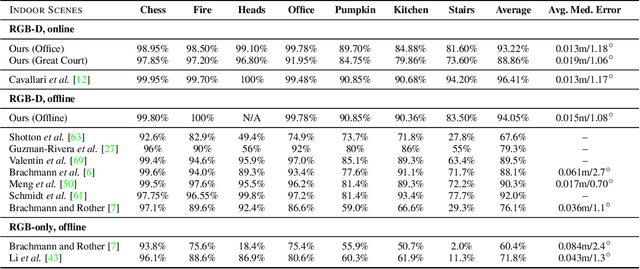
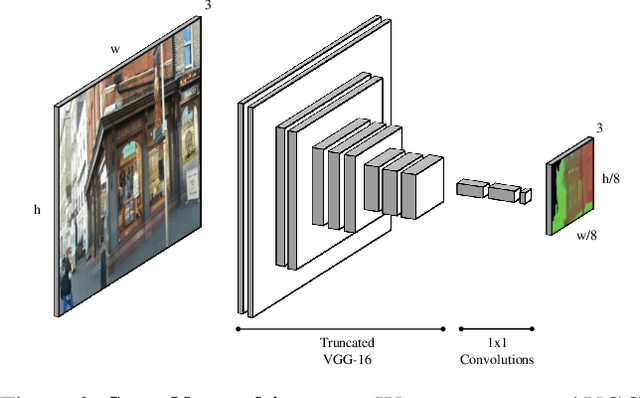
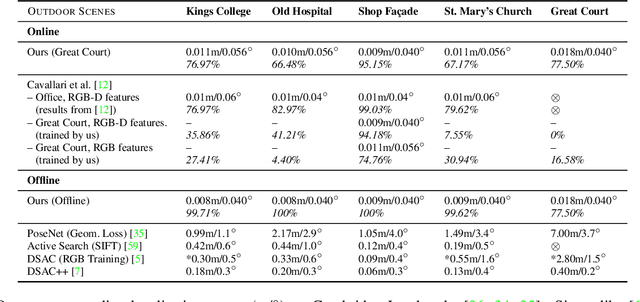
Many applications require a camera to be relocalised online, without expensive offline training on the target scene. Whilst both keyframe and sparse keypoint matching methods can be used online, the former often fail away from the training trajectory, and the latter can struggle in textureless regions. By contrast, scene coordinate regression (SCoRe) methods generalise to novel poses and can leverage dense correspondences to improve robustness, and recent work has shown how to adapt SCoRe forests between scenes, allowing their state-of-the-art performance to be leveraged online. However, because they use features hand-crafted for indoor use, they do not generalise well to harder outdoor scenes. Whilst replacing the forest with a neural network and learning suitable features for outdoor use is possible, the techniques used to adapt forests between scenes are unfortunately harder to transfer to a network context. In this paper, we address this by proposing a novel way of leveraging a network trained on one scene to predict points in another scene. Our approach replaces the appearance clustering performed by the branching structure of a regression forest with a two-step process that first uses the network to predict points in the original scene, and then uses these predicted points to look up clusters of points from the new scene. We show experimentally that our online approach achieves state-of-the-art performance on both the 7-Scenes and Cambridge Landmarks datasets, whilst running in under 300ms, making it highly effective in live scenarios.
Fast Online Object Tracking and Segmentation: A Unifying Approach
Dec 12, 2018



In this paper we illustrate how to perform both visual object tracking and semi-supervised video object segmentation, in real-time, with a single simple approach. Our method, dubbed SiamMask, improves the offline training procedure of popular fully-convolutional Siamese approaches for object tracking by augmenting their loss with a binary segmentation task. Once trained, SiamMask solely relies on a single bounding box initialisation and operates online, producing class-agnostic object segmentation masks and rotated bounding boxes at 35 frames per second. Despite its simplicity, versatility and fast speed, our strategy allows us to establish a new state-of-the-art among real-time trackers on VOT-2018, while at the same time demonstrating competitive performance and the best speed for the semi-supervised video object segmentation task on DAVIS-2016 and DAVIS-2017. The project website is http://www.robots.ox.ac.uk/~qwang/SiamMask.
Long-term Tracking in the Wild: A Benchmark
Aug 10, 2018
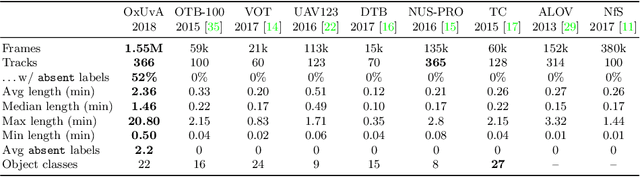
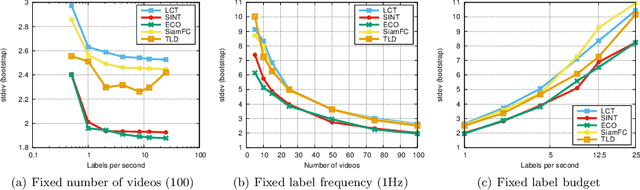
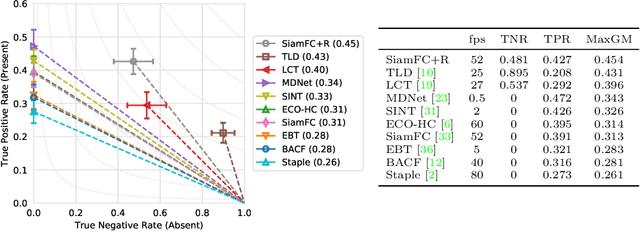
We introduce the OxUvA dataset and benchmark for evaluating single-object tracking algorithms. Benchmarks have enabled great strides in the field of object tracking by defining standardized evaluations on large sets of diverse videos. However, these works have focused exclusively on sequences that are just tens of seconds in length and in which the target is always visible. Consequently, most researchers have designed methods tailored to this "short-term" scenario, which is poorly representative of practitioners' needs. Aiming to address this disparity, we compile a long-term, large-scale tracking dataset of sequences with average length greater than two minutes and with frequent target object disappearance. The OxUvA dataset is much larger than the object tracking datasets of recent years: it comprises 366 sequences spanning 14 hours of video. We assess the performance of several algorithms, considering both the ability to locate the target and to determine whether it is present or absent. Our goal is to offer the community a large and diverse benchmark to enable the design and evaluation of tracking methods ready to be used "in the wild". The project website is http://oxuva.net