 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Object Queries for Transformer-based Incremental Object Detection
Jul 31, 2024



Incremental object detection (IOD) aims to sequentially learn new classes, while maintaining the capability to locate and identify old ones. As the training data arrives with annotations only with new classes, IOD suffers from catastrophic forgetting. Prior methodologies mainly tackle the forgetting issue through knowledge distillation and exemplar replay, ignoring the conflict between limited model capacity and increasing knowledge. In this paper, we explore \textit{dynamic object queries} for incremental object detection built on Transformer architecture. We propose the \textbf{Dy}namic object \textbf{Q}uery-based \textbf{DE}tection \textbf{TR}ansformer (DyQ-DETR), which incrementally expands the model representation ability to achieve stability-plasticity tradeoff. First, a new set of learnable object queries are fed into the decoder to represent new classes. These new object queries are aggregated with those from previous phases to adapt both old and new knowledge well. Second, we propose the isolated bipartite matching for object queries in different phases, based on disentangled self-attention. The interaction among the object queries at different phases is eliminated to reduce inter-class confusion. Thanks to the separate supervision and computation over object queries, we further present the risk-balanced partial calibration for effective exemplar replay. Extensive experiments demonstrate that DyQ-DETR significantly surpasses the state-of-the-art methods, with limited parameter overhead. Code will be made publicly available.
R^2: Randomized Decision Routing for Object Detection
Apr 02, 2022
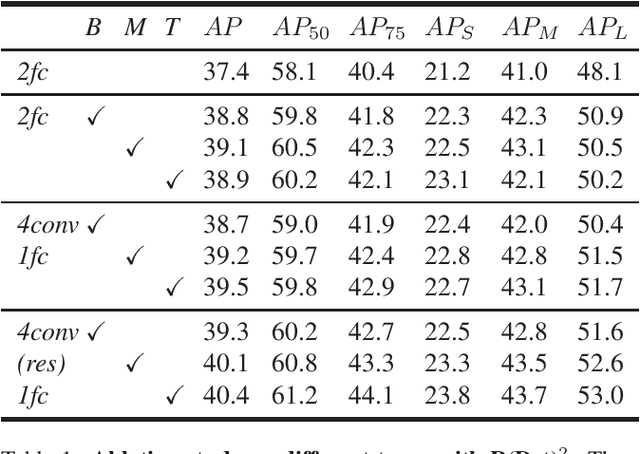


In the paradigm of object detection, the decision head is an important part, which affects detection performance significantly. Yet how to design a high-performance decision head remains to be an open issue. In this paper, we propose a novel approach to combine decision trees and deep neural networks in an end-to-end learning manner for object detection. First, we disentangle the decision choices and prediction values by plugging soft decision trees into neural networks. To facilitate effective learning, we propose randomized decision routing with node selective and associative losses, which can boost the feature representative learning and network decision simultaneously. Second, we develop the decision head for object detection with narrow branches to generate the routing probabilities and masks, for the purpose of obtaining divergent decisions from different nodes. We name this approach as the randomized decision routing for object detection, abbreviated as R(Det)$^2$. Experiments on MS-COCO dataset demonstrate that R(Det)$^2$ is effective to improve the detection performance. Equipped with existing detectors, it achieves $1.4\sim 3.6$\% AP improvement.
Do Different Tracking Tasks Require Different Appearance Models?
Jul 05, 2021



Tracking objects of interest in a video is one of the most popular and widely applicable problems in computer vision. However, with the years, a Cambrian explosion of use cases and benchmarks has fragmented the problem in a multitude of different experimental setups. As a consequence, the literature has fragmented too, and now the novel approaches proposed by the community are usually specialised to fit only one specific setup. To understand to what extent this specialisation is actually necessary, in this work we present UniTrack, a unified tracking solution to address five different tasks within the same framework. UniTrack consists of a single and task-agnostic appearance model, which can be learned in a supervised or self-supervised fashion, and multiple "heads" to address individual tasks and that do not require training. We show how most tracking tasks can be solved within this framework, and that the same appearance model can be used to obtain performance that is competitive against specialised methods for all the five tasks considered. The framework also allows us to analyse appearance models obtained with the most recent self-supervised methods, thus significantly extending their evaluation and comparison to a larger variety of important problems. Code available at https://github.com/Zhongdao/UniTrack.
Video Super-resolution with Temporal Group Attention
Jul 21, 2020
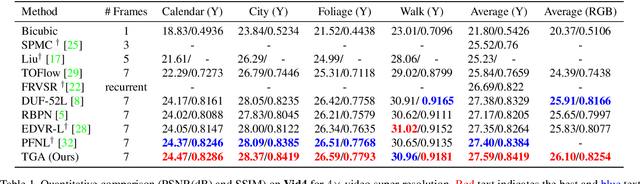


Video super-resolution, which aims at producing a high-resolution video from its corresponding low-resolution version, has recently drawn increasing attention. In this work, we propose a novel method that can effectively incorporate temporal information in a hierarchical way. The input sequence is divided into several groups, with each one corresponding to a kind of frame rate. These groups provide complementary information to recover missing details in the reference frame, which is further integrated with an attention module and a deep intra-group fusion module. In addition, a fast spatial alignment is proposed to handle videos with large motion. Extensive results demonstrate the capability of the proposed model in handling videos with various motion. It achieves favorable performance against state-of-the-art methods on several benchmark datasets.
HAR-Net: Joint Learning of Hybrid Attention for Single-stage Object Detection
Apr 25, 2019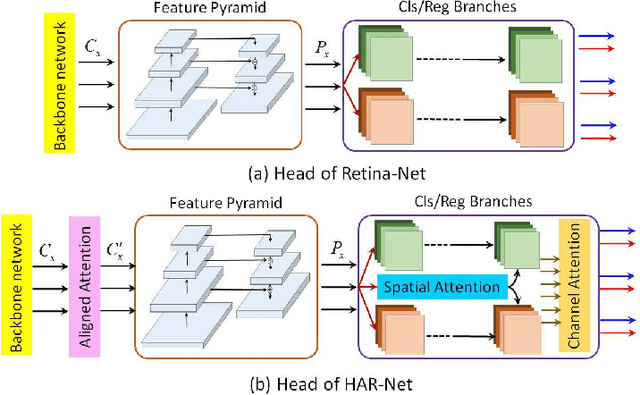
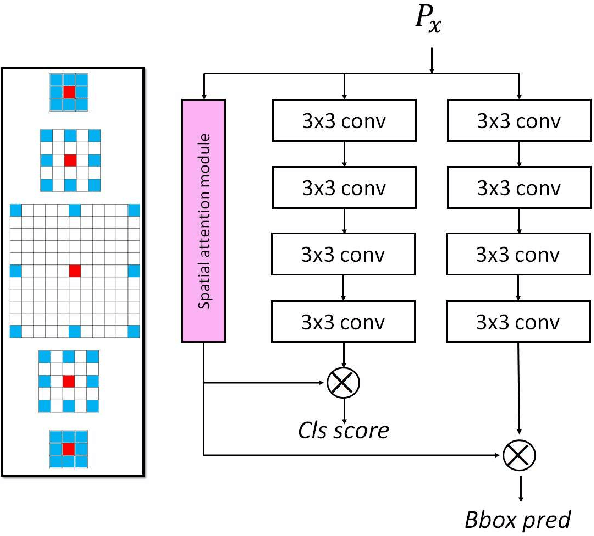


Object detection has been a challenging task in computer vision. Although significant progress has been made in object detection with deep neural networks, the attention mechanism is far from development. In this paper, we propose the hybrid attention mechanism for single-stage object detection. First, we present the modules of spatial attention, channel attention and aligned attention for single-stage object detection. In particular, stacked dilated convolution layers with symmetrically fixed rates are constructed to learn spatial attention. The channel attention is proposed with the cross-level group normalization and squeeze-and-excitation module. Aligned attention is constructed with organized deformable filters. Second, the three kinds of attention are unified to construct the hybrid attention mechanism. We then embed the hybrid attention into Retina-Net and propose the efficient single-stage HAR-Net for object detection. The attention modules and the proposed HAR-Net are evaluated on the COCO detection dataset. Experiments demonstrate that hybrid attention can significantly improve the detection accuracy and the HAR-Net can achieve the state-of-the-art 45.8\% mAP, outperform existing single-stage object detectors.