 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-InBetween: Generating Object State Transitions in Ego-Centric Videos
Apr 20, 2026Understanding physical transformation processes is crucial for both human cognition and artificial intelligence systems, particularly from an egocentric perspective, which serves as a key bridge between humans and machines in action modeling. We define this modeling process as Egocentric Instructed Visual State Transition (EIVST), which involves generating intermediate frames that depict object transformations between initial and target states under a brief action instruction. EIVST poses two challenges for current generative models: (1) understanding the visual scenes of the initial and target states and reasoning about transformation steps from an egocentric view, and (2) generating a consistent intermediate transition that follows the given instruction while preserving object appearance across the two visual states. To address these challenges, we propose the EgoIn framework. It first infers the multi-step transition process between two given states using TransitionVLM, fine-tuned on our curated dataset to better adapt to this task and reduce hallucinated information. It then generates a sequence of frames based on transition conditions produced by the proposed Transition Conditioning module. Additionally, we introduce Object-aware Auxiliary Supervision to preserve consistent object appearance throughout the transition. Extensive experiments on human-object and robot-object interaction datasets demonstrate EgoIn's superior performance in generating semantically meaningful and visually coherent transformation sequences.
Seek-and-Solve: Benchmarking MLLMs for Visual Clue-Driven Reasoning in Daily Scenarios
Apr 16, 2026Daily scenarios are characterized by visual richness, requiring Multimodal Large Language Models (MLLMs) to filter noise and identify decisive visual clues for accurate reasoning. Yet, current benchmarks predominantly aim at evaluating MLLMs' pre-existing knowledge or perceptual understanding, often neglecting the critical capability of reasoning. To bridge this gap, we introduce DailyClue, a benchmark designed for visual clue-driven reasoning in daily scenarios. Our construction is guided by two core principles: (1) strict grounding in authentic daily activities, and (2) challenging query design that necessitates more than surface-level perception. Instead of simple recognition, our questions compel MLLMs to actively explore suitable visual clues and leverage them for subsequent reasoning. To this end, we curate a comprehensive dataset spanning four major daily domains and 16 distinct subtasks. Comprehensive evaluation across MLLMs and agentic models underscores the formidable challenge posed by our benchmark. Our analysis reveals several critical insights, emphasizing that the accurate identification of visual clues is essential for robust reasoning.
Omni-DPO: A Dual-Perspective Paradigm for Dynamic Preference Learning of LLMs
Jun 11, 2025Direct Preference Optimization (DPO) has become a cornerstone of reinforcement learning from human feedback (RLHF) due to its simplicity and efficiency. However, existing DPO-based approaches typically treat all preference pairs uniformly, ignoring critical variations in their inherent quality and learning utility, leading to suboptimal data utilization and performance. To address this challenge, we propose Omni-DPO, a dual-perspective optimization framework that jointly accounts for (1) the inherent quality of each preference pair and (2) the model's evolving performance on those pairs. By adaptively weighting samples according to both data quality and the model's learning dynamics during training, Omni-DPO enables more effective training data utilization and achieves better performance. Experimental results on various models and benchmarks demonstrate the superiority and generalization capabilities of Omni-DPO. On textual understanding tasks, Gemma-2-9b-it finetuned with Omni-DPO beats the leading LLM, Claude 3 Opus, by a significant margin of 6.7 points on the Arena-Hard benchmark. On mathematical reasoning tasks, Omni-DPO consistently outperforms the baseline methods across all benchmarks, providing strong empirical evidence for the effectiveness and robustness of our approach. Code and models will be available at https://github.com/pspdada/Omni-DPO.
AMD-Hummingbird: Towards an Efficient Text-to-Video Model
Mar 25, 2025Text-to-Video (T2V) generation has attracted significant attention for its ability to synthesize realistic videos from textual descriptions. However, existing models struggle to balance computational efficiency and high visual quality, particularly on resource-limited devices, e.g.,iGPUs and mobile phones. Most prior work prioritizes visual fidelity while overlooking the need for smaller, more efficient models suitable for real-world deployment. To address this challenge, we propose a lightweight T2V framework, termed Hummingbird, which prunes existing models and enhances visual quality through visual feedback learning. Our approach reduces the size of the U-Net from 1.4 billion to 0.7 billion parameters, significantly improving efficiency while preserving high-quality video generation. Additionally, we introduce a novel data processing pipeline that leverages Large Language Models (LLMs) and Video Quality Assessment (VQA) models to enhance the quality of both text prompts and video data. To support user-driven training and style customization, we publicly release the full training code, including data processing and model training. Extensive experiments show that our method achieves a 31X speedup compared to state-of-the-art models such as VideoCrafter2, while also attaining the highest overall score on VBench. Moreover, our method supports the generation of videos with up to 26 frames, addressing the limitations of existing U-Net-based methods in long video generation. Notably, the entire training process requires only four GPUs, yet delivers performance competitive with existing leading methods. Hummingbird presents a practical and efficient solution for T2V generation, combining high performance, scalability, and flexibility for real-world applications.
ReNeg: Learning Negative Embedding with Reward Guidance
Dec 27, 2024In text-to-image (T2I) generation applications, negative embeddings have proven to be a simple yet effective approach for enhancing generation quality. Typically, these negative embeddings are derived from user-defined negative prompts, which, while being functional, are not necessarily optimal. In this paper, we introduce ReNeg, an end-to-end method designed to learn improved Negative embeddings guided by a Reward model. We employ a reward feedback learning framework and integrate classifier-free guidance (CFG) into the training process, which was previously utilized only during inference, thus enabling the effective learning of negative embeddings. We also propose two strategies for learning both global and per-sample negative embeddings. Extensive experiments show that the learned negative embedding significantly outperforms null-text and handcrafted counterparts, achieving substantial improvements in human preference alignment. Additionally, the negative embedding learned within the same text embedding space exhibits strong generalization capabilities. For example, using the same CLIP text encoder, the negative embedding learned on SD1.5 can be seamlessly transferred to text-to-image or even text-to-video models such as ControlNet, ZeroScope, and VideoCrafter2, resulting in consistent performance improvements across the board.
List-Mode PET Image Reconstruction Using Deep Image Prior
Apr 28, 2022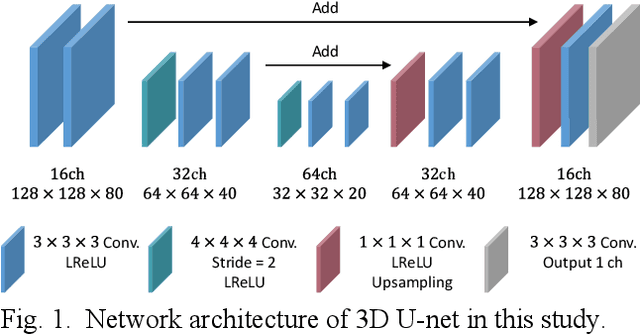
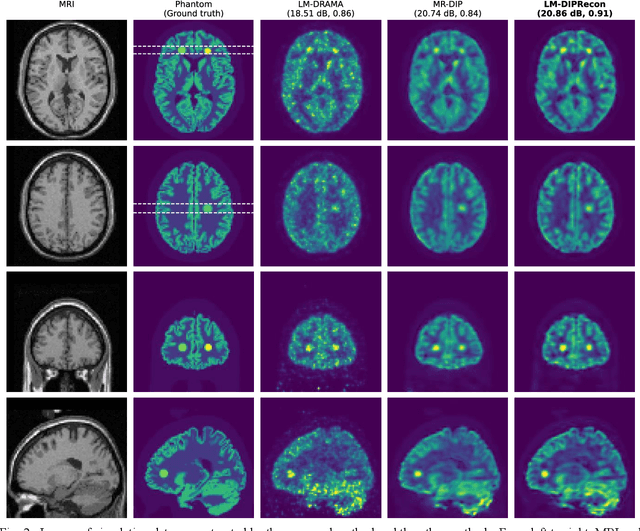
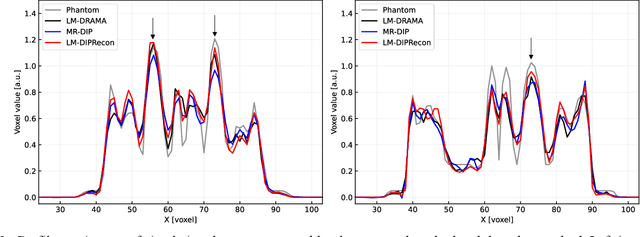
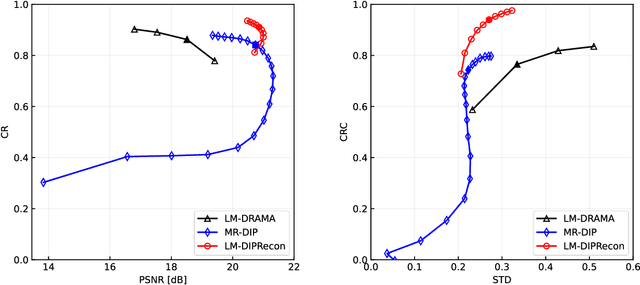
List-mode positron emission tomography (PET) image reconstruction is an important tool for PET scanners with many lines-of-response (LORs) and additional information such as time-of-flight and depth-of-interaction. Deep learning is one possible solution to enhance the quality of PET image reconstruction. However, the application of deep learning techniques to list-mode PET image reconstruction have not been progressed because list data is a sequence of bit codes and unsuitable for processing by convolutional neural networks (CNN). In this study, we propose a novel list-mode PET image reconstruction method using an unsupervised CNN called deep image prior (DIP) and a framework of alternating direction method of multipliers. The proposed list-mode DIP reconstruction (LM-DIPRecon) method alternatively iterates regularized list-mode dynamic row action maximum likelihood algorithm (LM-DRAMA) and magnetic resonance imaging conditioned DIP (MR-DIP). We evaluated LM-DIPRecon using both simulation and clinical data, and it achieved sharper images and better tradeoff curves between contrast and noise than the LM-DRAMA and MR-DIP. These results indicated that the LM-DIPRecon is useful for quantitative PET imaging with limited events. In addition, as list data has finer temporal information than dynamic sinograms, list-mode deep image prior reconstruction is expected to be useful for 4D PET imaging and motion correction.
Look Back and Forth: Video Super-Resolution with Explicit Temporal Difference Modeling
Apr 14, 2022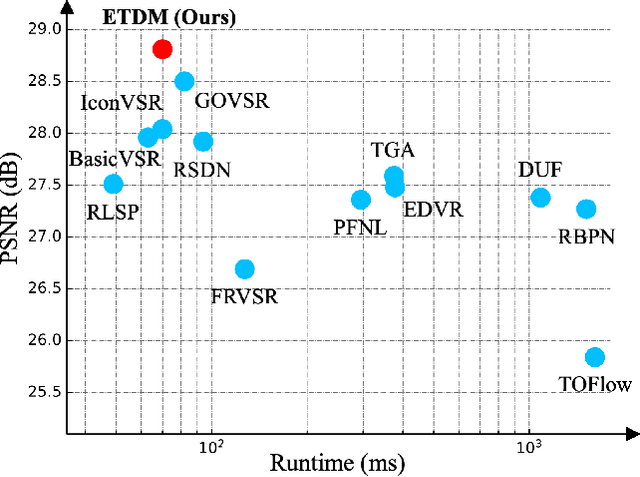
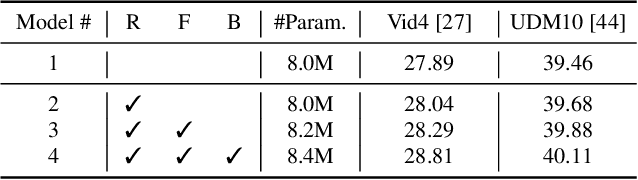
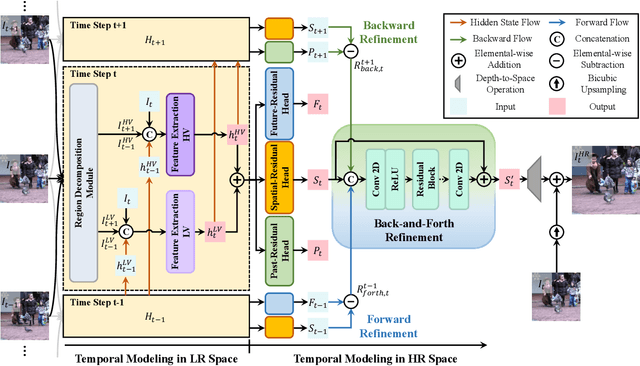
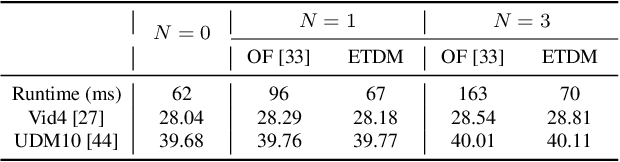
Temporal modeling is crucial for video super-resolution. Most of the video super-resolution methods adopt the optical flow or deformable convolution for explicitly motion compensation. However, such temporal modeling techniques increase the model complexity and might fail in case of occlusion or complex motion, resulting in serious distortion and artifacts. In this paper, we propose to explore the role of explicit temporal difference modeling in both LR and HR space. Instead of directly feeding consecutive frames into a VSR model, we propose to compute the temporal difference between frames and divide those pixels into two subsets according to the level of difference. They are separately processed with two branches of different receptive fields in order to better extract complementary information. To further enhance the super-resolution result, not only spatial residual features are extracted, but the difference between consecutive frames in high-frequency domain is also computed. It allows the model to exploit intermediate SR results in both future and past to refine the current SR output. The difference at different time steps could be cached such that information from further distance in time could be propagated to the current frame for refinement. Experiments on several video super-resolution benchmark datasets demonstrate the effectiveness of the proposed method and its favorable performance against state-of-the-art methods.
Towards Discriminative Representation Learning for Unsupervised Person Re-identification
Aug 16, 2021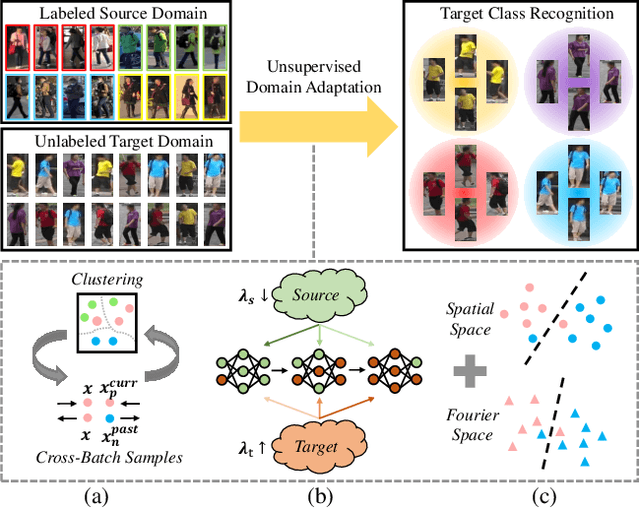
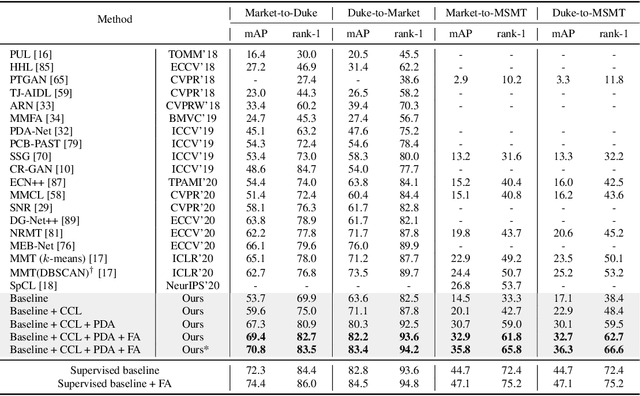
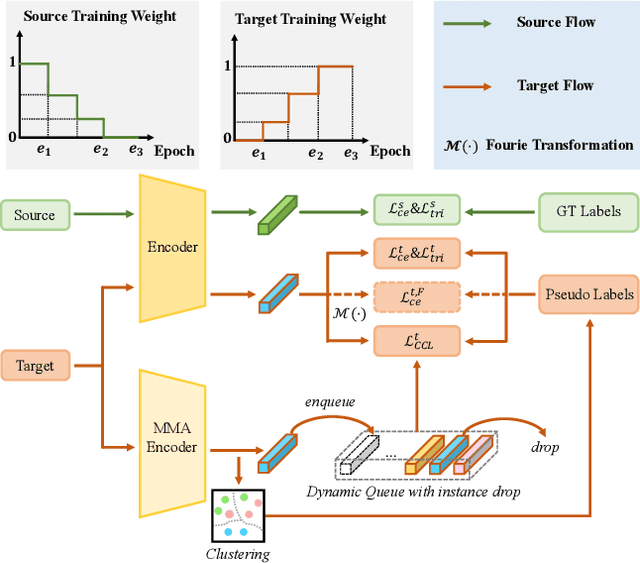
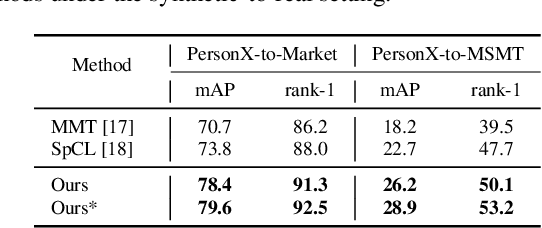
In this work, we address the problem of unsupervised domain adaptation for person re-ID where annotations are available for the source domain but not for target. Previous methods typically follow a two-stage optimization pipeline, where the network is first pre-trained on source and then fine-tuned on target with pseudo labels created by feature clustering. Such methods sustain two main limitations. (1) The label noise may hinder the learning of discriminative features for recognizing target classes. (2) The domain gap may hinder knowledge transferring from source to target. We propose three types of technical schemes to alleviate these issues. First, we propose a cluster-wise contrastive learning algorithm (CCL) by iterative optimization of feature learning and cluster refinery to learn noise-tolerant representations in the unsupervised manner. Second, we adopt a progressive domain adaptation (PDA) strategy to gradually mitigate the domain gap between source and target data. Third, we propose Fourier augmentation (FA) for further maximizing the class separability of re-ID models by imposing extra constraints in the Fourier space. We observe that these proposed schemes are capable of facilitating the learning of discriminative feature representations. Experiments demonstrate that our method consistently achieves notable improvements over the state-of-the-art unsupervised re-ID methods on multiple benchmarks, e.g., surpassing MMT largely by 8.1\%, 9.9\%, 11.4\% and 11.1\% mAP on the Market-to-Duke, Duke-to-Market, Market-to-MSMT and Duke-to-MSMT tasks, respectively.
Multi-Target Domain Adaptation with Collaborative Consistency Learning
Jun 07, 2021
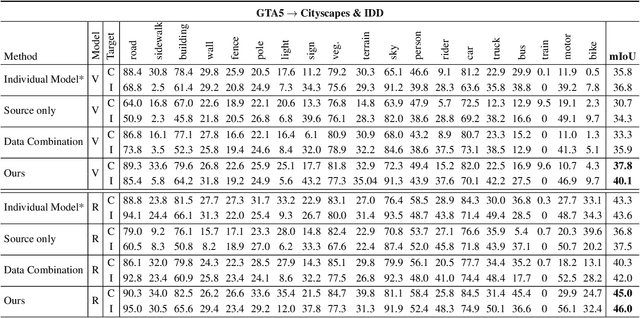

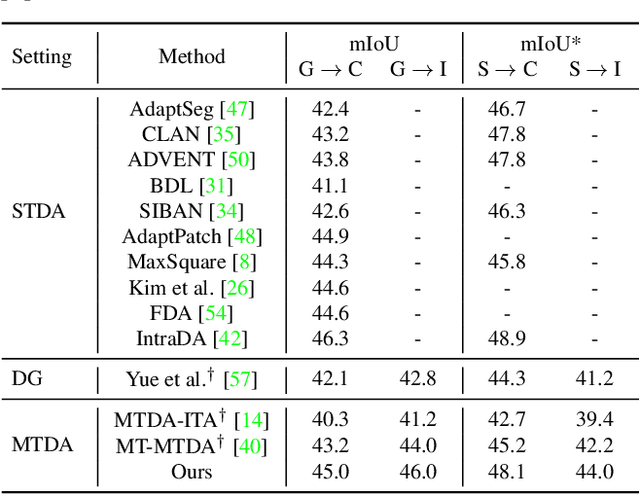
Recently unsupervised domain adaptation for the semantic segmentation task has become more and more popular due to high-cost of pixel-level annotation on real-world images. However, most domain adaptation methods are only restricted to single-source-single-target pair, and can not be directly extended to multiple target domains. In this work, we propose a collaborative learning framework to achieve unsupervised multi-target domain adaptation. An unsupervised domain adaptation expert model is first trained for each source-target pair and is further encouraged to collaborate with each other through a bridge built between different target domains. These expert models are further improved by adding the regularization of making the consistent pixel-wise prediction for each sample with the same structured context. To obtain a single model that works across multiple target domains, we propose to simultaneously learn a student model which is trained to not only imitate the output of each expert on the corresponding target domain, but also to pull different expert close to each other with regularization on their weights. Extensive experiments demonstrate that the proposed method can effectively exploit rich structured information contained in both labeled source domain and multiple unlabeled target domains. Not only does it perform well across multiple target domains but also performs favorably against state-of-the-art unsupervised domain adaptation methods specially trained on a single source-target pair
Revisiting Temporal Modeling for Video Super-resolution
Aug 20, 2020

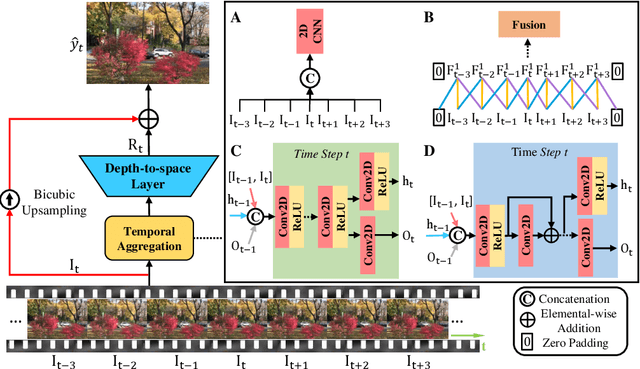

Video super-resolution plays an important role in surveillance video analysis and ultra-high-definition video display, which has drawn much attention in both the research and industrial communities. Although many deep learning-based VSR methods have been proposed, it is hard to directly compare these methods since the different loss functions and training datasets have a significant impact on the super-resolution results. In this work, we carefully study and compare three temporal modeling methods (2D CNN with early fusion, 3D CNN with slow fusion and Recurrent Neural Network) for video super-resolution. We also propose a novel Recurrent Residual Network (RRN) for efficient video super-resolution, where residual learning is utilized to stabilize the training of RNN and meanwhile to boost the super-resolution performance. Extensive experiments show that the proposed RRN is highly computational efficiency and produces temporal consistent VSR results with finer details than other temporal modeling methods. Besides, the proposed method achieves state-of-the-art results on several widely used benchmarks.