 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalizing Federated Learning for Hierarchical Edge Networks with Non-IID Data
Apr 11, 2025Accommodating edge networks between IoT devices and the cloud server in Hierarchical Federated Learning (HFL) enhances communication efficiency without compromising data privacy. However, devices connected to the same edge often share geographic or contextual similarities, leading to varying edge-level data heterogeneity with different subsets of labels per edge, on top of device-level heterogeneity. This hierarchical non-Independent and Identically Distributed (non-IID) nature, which implies that each edge has its own optimization goal, has been overlooked in HFL research. Therefore, existing edge-accommodated HFL demonstrates inconsistent performance across edges in various hierarchical non-IID scenarios. To ensure robust performance with diverse edge-level non-IID data, we propose a Personalized Hierarchical Edge-enabled Federated Learning (PHE-FL), which personalizes each edge model to perform well on the unique class distributions specific to each edge. We evaluated PHE-FL across 4 scenarios with varying levels of edge-level non-IIDness, with extreme IoT device level non-IIDness. To accurately assess the effectiveness of our personalization approach, we deployed test sets on each edge server instead of the cloud server, and used both balanced and imbalanced test sets. Extensive experiments show that PHE-FL achieves up to 83 percent higher accuracy compared to existing federated learning approaches that incorporate edge networks, given the same number of training rounds. Moreover, PHE-FL exhibits improved stability, as evidenced by reduced accuracy fluctuations relative to the state-of-the-art FedAvg with two-level (edge and cloud) aggregation.
AutoRank: MCDA Based Rank Personalization for LoRA-Enabled Distributed Learning
Dec 20, 2024



As data volumes expand rapidly, distributed machine learning has become essential for addressing the growing computational demands of modern AI systems. However, training models in distributed environments is challenging with participants hold skew, Non-Independent-Identically distributed (Non-IID) data. Low-Rank Adaptation (LoRA) offers a promising solution to this problem by personalizing low-rank updates rather than optimizing the entire model, LoRA-enabled distributed learning minimizes computational and maximize personalization for each participant. Enabling more robust and efficient training in distributed learning settings, especially in large-scale, heterogeneous systems. Despite the strengths of current state-of-the-art methods, they often require manual configuration of the initial rank, which is increasingly impractical as the number of participants grows. This manual tuning is not only time-consuming but also prone to suboptimal configurations. To address this limitation, we propose AutoRank, an adaptive rank-setting algorithm inspired by the bias-variance trade-off. AutoRank leverages the MCDA method TOPSIS to dynamically assign local ranks based on the complexity of each participant's data. By evaluating data distribution and complexity through our proposed data complexity metrics, AutoRank provides fine-grained adjustments to the rank of each participant's local LoRA model. This adaptive approach effectively mitigates the challenges of double-imbalanced, non-IID data. Experimental results demonstrate that AutoRank significantly reduces computational overhead, enhances model performance, and accelerates convergence in highly heterogeneous federated learning environments. Through its strong adaptability, AutoRank offers a scalable and flexible solution for distributed machine learning.
RBLA: Rank-Based-LoRA-Aggregation for Fine-tuning Heterogeneous Models in FLaaS
Aug 16, 2024



Federated Learning (FL) is a promising privacy-aware distributed learning framework that can be deployed on various devices, such as mobile phones, desktops, and devices equipped with CPUs or GPUs. In the context of server-based Federated Learning as a Service (FLaas), FL enables the central server to coordinate the training process across multiple devices without direct access to the local data, thereby enhancing privacy and data security. Low-Rank Adaptation (LoRA) is a method that fine-tunes models efficiently by focusing on a low-dimensional subspace of the model's parameters. This approach significantly reduces computational and memory costs compared to fine-tuning all parameters from scratch. When integrated with FL, especially in a FLaas environment, LoRA allows for flexible and efficient deployment across diverse hardware with varying computational capabilities by adjusting the local model's rank. However, in LoRA-enabled FL, different clients may train models with varying ranks, which poses a challenge for model aggregation on the server. Current methods of aggregating models of different ranks require padding weights to a uniform shape, which can degrade the global model's performance. To address this issue, we propose Rank-Based LoRA Aggregation (RBLA), a novel model aggregation method designed for heterogeneous LoRA structures. RBLA preserves key features across models with different ranks. This paper analyzes the issues with current padding methods that reshape models for aggregation in a FLaas environment. Then, we introduce RBLA, a rank-based aggregation method that maintains both low-rank and high-rank features. Finally, we demonstrate the effectiveness of RBLA through comparative experiments with state-of-the-art methods.
Towards Uniform Point Distribution in Feature-preserving Point Cloud Filtering
Jan 17, 2022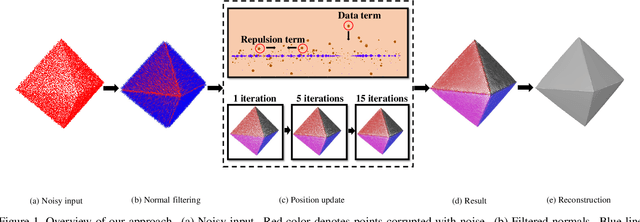
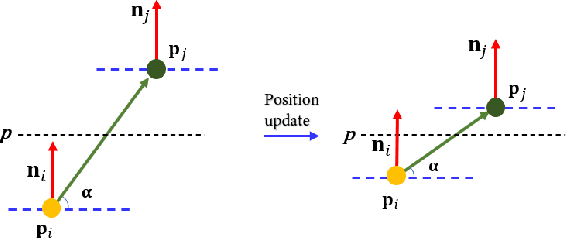
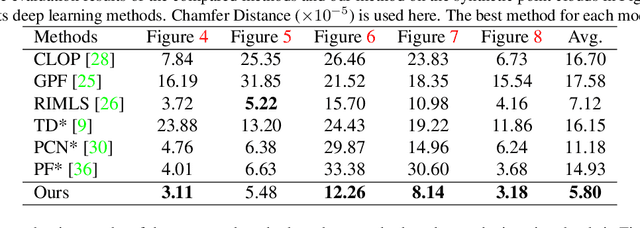
As a popular representation of 3D data, point cloud may contain noise and need to be filtered before use. Existing point cloud filtering methods either cannot preserve sharp features or result in uneven point distribution in the filtered output. To address this problem, this paper introduces a point cloud filtering method that considers both point distribution and feature preservation during filtering. The key idea is to incorporate a repulsion term with a data term in energy minimization. The repulsion term is responsible for the point distribution, while the data term is to approximate the noisy surfaces while preserving the geometric features. This method is capable of handling models with fine-scale features and sharp features. Extensive experiments show that our method yields better results with a more uniform point distribution ($5.8\times10^{-5}$ Chamfer Distance on average) in seconds.
T-SVDNet: Exploring High-Order Prototypical Correlations for Multi-Source Domain Adaptation
Jul 30, 2021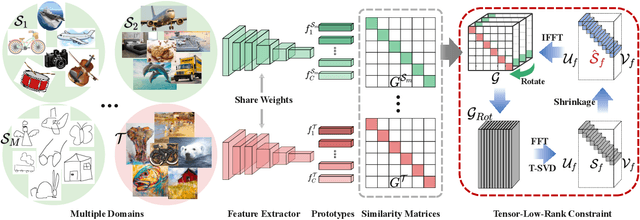
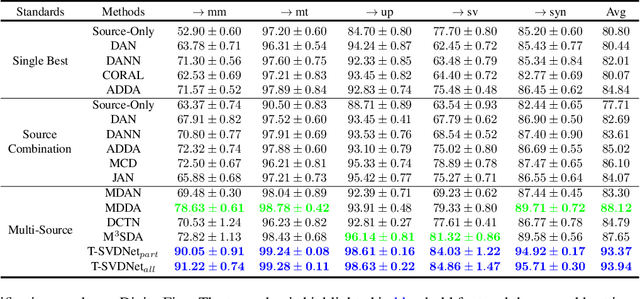
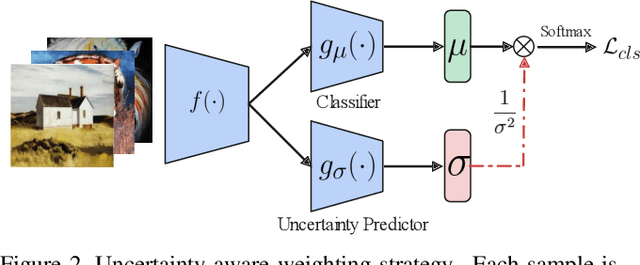
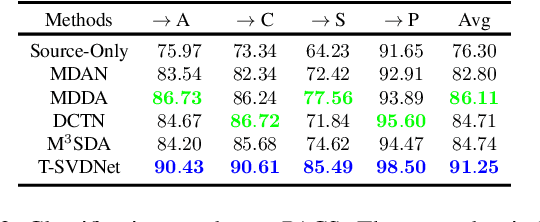
Most existing domain adaptation methods focus on adaptation from only one source domain, however, in practice there are a number of relevant sources that could be leveraged to help improve performance on target domain. We propose a novel approach named T-SVDNet to address the task of Multi-source Domain Adaptation (MDA), which is featured by incorporating Tensor Singular Value Decomposition (T-SVD) into a neural network's training pipeline. Overall, high-order correlations among multiple domains and categories are fully explored so as to better bridge the domain gap. Specifically, we impose Tensor-Low-Rank (TLR) constraint on a tensor obtained by stacking up a group of prototypical similarity matrices, aiming at capturing consistent data structure across different domains. Furthermore, to avoid negative transfer brought by noisy source data, we propose a novel uncertainty-aware weighting strategy to adaptively assign weights to different source domains and samples based on the result of uncertainty estimation. Extensive experiments conducted on public benchmarks demonstrate the superiority of our model in addressing the task of MDA compared to state-of-the-art methods.
Multi-Target Domain Adaptation with Collaborative Consistency Learning
Jun 07, 2021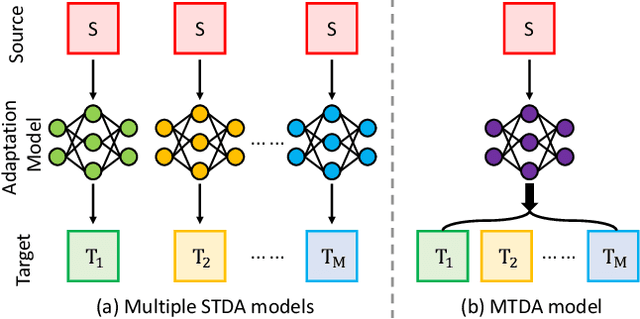
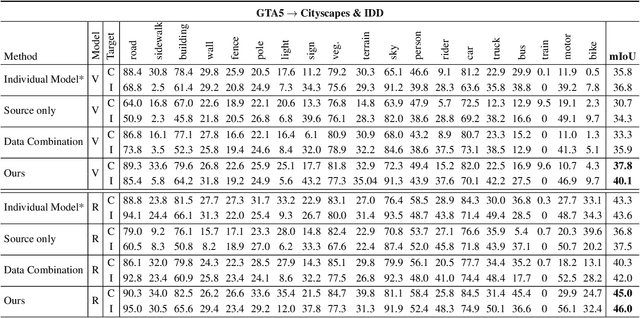

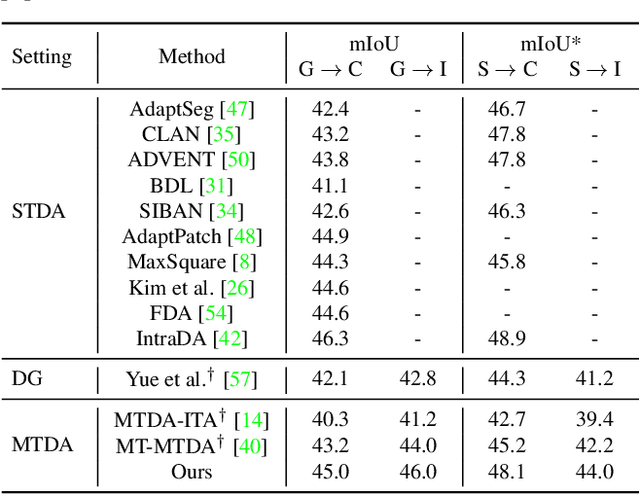
Recently unsupervised domain adaptation for the semantic segmentation task has become more and more popular due to high-cost of pixel-level annotation on real-world images. However, most domain adaptation methods are only restricted to single-source-single-target pair, and can not be directly extended to multiple target domains. In this work, we propose a collaborative learning framework to achieve unsupervised multi-target domain adaptation. An unsupervised domain adaptation expert model is first trained for each source-target pair and is further encouraged to collaborate with each other through a bridge built between different target domains. These expert models are further improved by adding the regularization of making the consistent pixel-wise prediction for each sample with the same structured context. To obtain a single model that works across multiple target domains, we propose to simultaneously learn a student model which is trained to not only imitate the output of each expert on the corresponding target domain, but also to pull different expert close to each other with regularization on their weights. Extensive experiments demonstrate that the proposed method can effectively exploit rich structured information contained in both labeled source domain and multiple unlabeled target domains. Not only does it perform well across multiple target domains but also performs favorably against state-of-the-art unsupervised domain adaptation methods specially trained on a single source-target pair
Multi-Source Domain Adaptation with Collaborative Learning for Semantic Segmentation
Mar 16, 2021
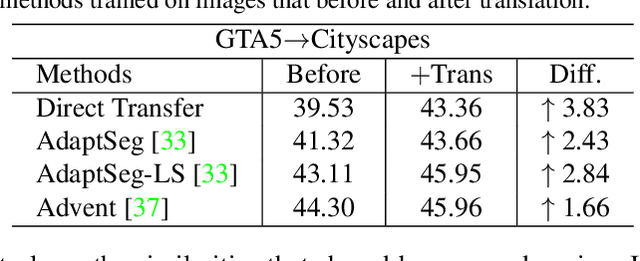
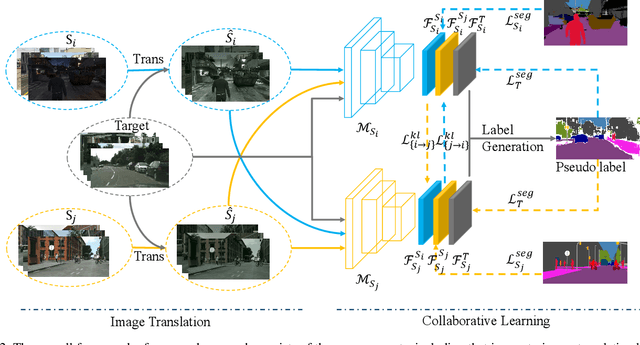
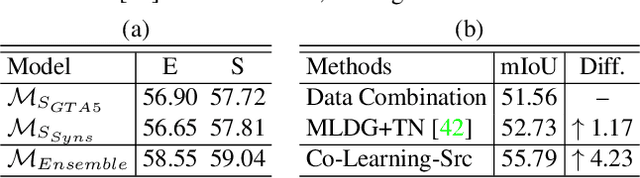
Multi-source unsupervised domain adaptation~(MSDA) aims at adapting models trained on multiple labeled source domains to an unlabeled target domain. In this paper, we propose a novel multi-source domain adaptation framework based on collaborative learning for semantic segmentation. Firstly, a simple image translation method is introduced to align the pixel value distribution to reduce the gap between source domains and target domain to some extent. Then, to fully exploit the essential semantic information across source domains, we propose a collaborative learning method for domain adaptation without seeing any data from target domain. In addition, similar to the setting of unsupervised domain adaptation, unlabeled target domain data is leveraged to further improve the performance of domain adaptation. This is achieved by additionally constraining the outputs of multiple adaptation models with pseudo labels online generated by an ensembled model. Extensive experiments and ablation studies are conducted on the widely-used domain adaptation benchmark datasets in semantic segmentation. Our proposed method achieves 59.0\% mIoU on the validation set of Cityscapes by training on the labeled Synscapes and GTA5 datasets and unlabeled training set of Cityscapes. It significantly outperforms all previous state-of-the-arts single-source and multi-source unsupervised domain adaptation methods.
Semi-supervised Domain Adaptation based on Dual-level Domain Mixing for Semantic Segmentation
Mar 08, 2021


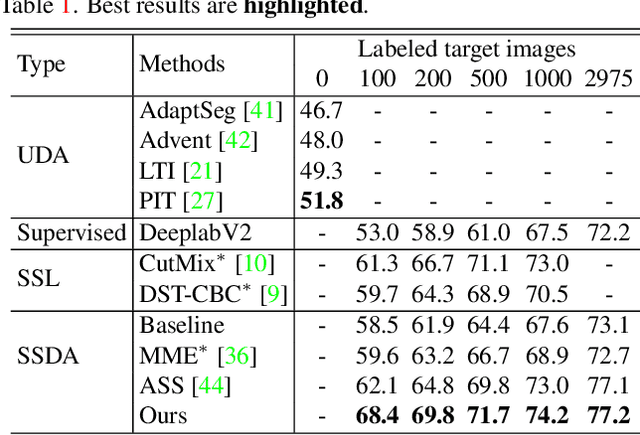
Data-driven based approaches, in spite of great success in many tasks, have poor generalization when applied to unseen image domains, and require expensive cost of annotation especially for dense pixel prediction tasks such as semantic segmentation. Recently, both unsupervised domain adaptation (UDA) from large amounts of synthetic data and semi-supervised learning (SSL) with small set of labeled data have been studied to alleviate this issue. However, there is still a large gap on performance compared to their supervised counterparts. We focus on a more practical setting of semi-supervised domain adaptation (SSDA) where both a small set of labeled target data and large amounts of labeled source data are available. To address the task of SSDA, a novel framework based on dual-level domain mixing is proposed. The proposed framework consists of three stages. First, two kinds of data mixing methods are proposed to reduce domain gap in both region-level and sample-level respectively. We can obtain two complementary domain-mixed teachers based on dual-level mixed data from holistic and partial views respectively. Then, a student model is learned by distilling knowledge from these two teachers. Finally, pseudo labels of unlabeled data are generated in a self-training manner for another few rounds of teachers training. Extensive experimental results have demonstrated the effectiveness of our proposed framework on synthetic-to-real semantic segmentation benchmarks.
Unsupervised Image Super-Resolution with an Indirect Supervised Path
Oct 13, 2019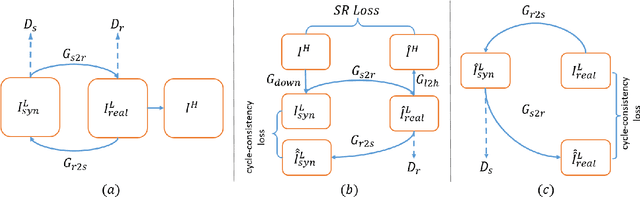



The task of single image super-resolution (SISR) aims at reconstructing a high-resolution (HR) image from a low-resolution (LR) image. Although significant progress has been made by deep learning models, they are trained on synthetic paired data in a supervised way and do not perform well on real data. There are several attempts that directly apply unsupervised image translation models to address such a problem. However, unsupervised low-level vision problem poses more challenge on the accuracy of translation. In this work,we propose a novel framework which is composed of two stages: 1) unsupervised image translation between real LR images and synthetic LR images; 2) supervised super-resolution from approximated real LR images to HR images. It takes the synthetic LR images as a bridge and creates an indirect supervised path from real LR images to HR images. Any existed deep learning based image super-resolution model can be integrated into the second stage of the proposed framework for further improvement. In addition it shows great flexibility in balancing between distortion and perceptual quality under unsupervised setting. The proposed method is evaluated on both NTIRE 2017 and 2018 challenge datasets and achieves favorable performance against supervised methods.