 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCoTTA: Continual Test-Time Adaptation for Multi-Task Point Cloud Understanding
Nov 01, 2024



In this paper, we present PCoTTA, an innovative, pioneering framework for Continual Test-Time Adaptation (CoTTA) in multi-task point cloud understanding, enhancing the model's transferability towards the continually changing target domain. We introduce a multi-task setting for PCoTTA, which is practical and realistic, handling multiple tasks within one unified model during the continual adaptation. Our PCoTTA involves three key components: automatic prototype mixture (APM), Gaussian Splatted feature shifting (GSFS), and contrastive prototype repulsion (CPR). Firstly, APM is designed to automatically mix the source prototypes with the learnable prototypes with a similarity balancing factor, avoiding catastrophic forgetting. Then, GSFS dynamically shifts the testing sample toward the source domain, mitigating error accumulation in an online manner. In addition, CPR is proposed to pull the nearest learnable prototype close to the testing feature and push it away from other prototypes, making each prototype distinguishable during the adaptation. Experimental comparisons lead to a new benchmark, demonstrating PCoTTA's superiority in boosting the model's transferability towards the continually changing target domain.
DG-PIC: Domain Generalized Point-In-Context Learning for Point Cloud Understanding
Jul 11, 2024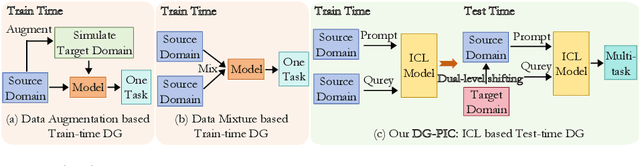
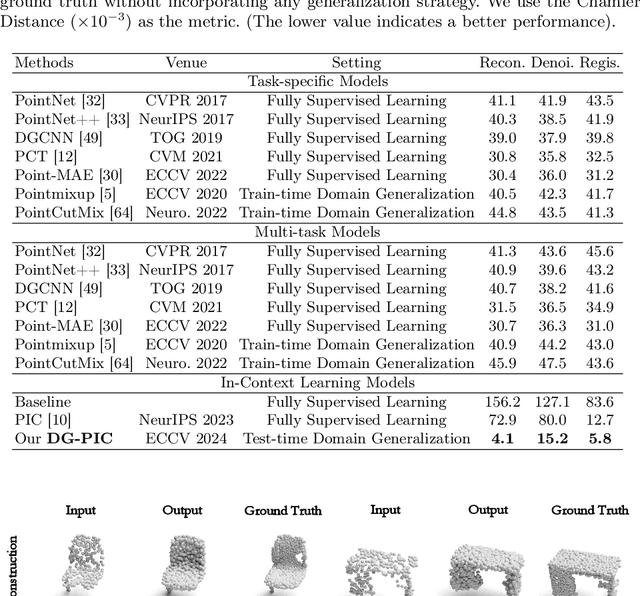
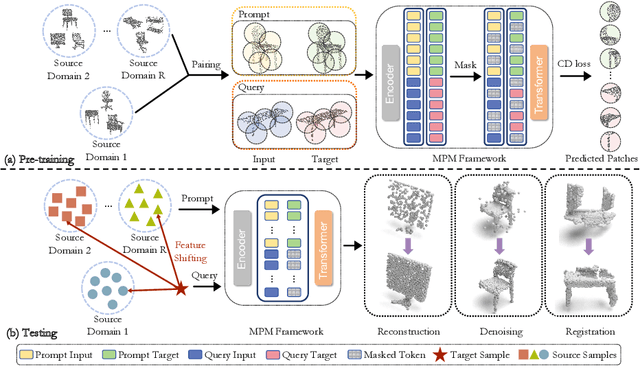

Recent point cloud understanding research suffers from performance drops on unseen data, due to the distribution shifts across different domains. While recent studies use Domain Generalization (DG) techniques to mitigate this by learning domain-invariant features, most are designed for a single task and neglect the potential of testing data. Despite In-Context Learning (ICL) showcasing multi-task learning capability, it usually relies on high-quality context-rich data and considers a single dataset, and has rarely been studied in point cloud understanding. In this paper, we introduce a novel, practical, multi-domain multi-task setting, handling multiple domains and multiple tasks within one unified model for domain generalized point cloud understanding. To this end, we propose Domain Generalized Point-In-Context Learning (DG-PIC) that boosts the generalizability across various tasks and domains at testing time. In particular, we develop dual-level source prototype estimation that considers both global-level shape contextual and local-level geometrical structures for representing source domains and a dual-level test-time feature shifting mechanism that leverages both macro-level domain semantic information and micro-level patch positional relationships to pull the target data closer to the source ones during the testing. Our DG-PIC does not require any model updates during the testing and can handle unseen domains and multiple tasks, \textit{i.e.,} point cloud reconstruction, denoising, and registration, within one unified model. We also introduce a benchmark for this new setting. Comprehensive experiments demonstrate that DG-PIC outperforms state-of-the-art techniques significantly.
Tele-Aloha: A Low-budget and High-authenticity Telepresence System Using Sparse RGB Cameras
May 23, 2024
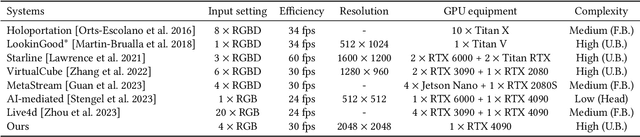

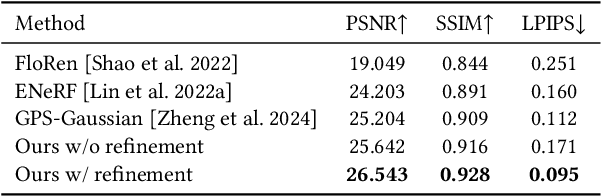
In this paper, we present a low-budget and high-authenticity bidirectional telepresence system, Tele-Aloha, targeting peer-to-peer communication scenarios. Compared to previous systems, Tele-Aloha utilizes only four sparse RGB cameras, one consumer-grade GPU, and one autostereoscopic screen to achieve high-resolution (2048x2048), real-time (30 fps), low-latency (less than 150ms) and robust distant communication. As the core of Tele-Aloha, we propose an efficient novel view synthesis algorithm for upper-body. Firstly, we design a cascaded disparity estimator for obtaining a robust geometry cue. Additionally a neural rasterizer via Gaussian Splatting is introduced to project latent features onto target view and to decode them into a reduced resolution. Further, given the high-quality captured data, we leverage weighted blending mechanism to refine the decoded image into the final resolution of 2K. Exploiting world-leading autostereoscopic display and low-latency iris tracking, users are able to experience a strong three-dimensional sense even without any wearable head-mounted display device. Altogether, our telepresence system demonstrates the sense of co-presence in real-life experiments, inspiring the next generation of communication.
DHGCN: Dynamic Hop Graph Convolution Network for Self-supervised Point Cloud Learning
Jan 05, 2024

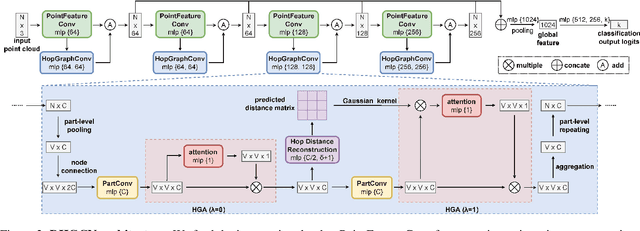

Recent works attempt to extend Graph Convolution Networks (GCNs) to point clouds for classification and segmentation tasks. These works tend to sample and group points to create smaller point sets locally and mainly focus on extracting local features through GCNs, while ignoring the relationship between point sets. In this paper, we propose the Dynamic Hop Graph Convolution Network (DHGCN) for explicitly learning the contextual relationships between the voxelized point parts, which are treated as graph nodes. Motivated by the intuition that the contextual information between point parts lies in the pairwise adjacent relationship, which can be depicted by the hop distance of the graph quantitatively, we devise a novel self-supervised part-level hop distance reconstruction task and design a novel loss function accordingly to facilitate training. In addition, we propose the Hop Graph Attention (HGA), which takes the learned hop distance as input for producing attention weights to allow edge features to contribute distinctively in aggregation. Eventually, the proposed DHGCN is a plug-and-play module that is compatible with point-based backbone networks. Comprehensive experiments on different backbones and tasks demonstrate that our self-supervised method achieves state-of-the-art performance. Our source code is available at: https://github.com/Jinec98/DHGCN.
Masked Autoencoders in 3D Point Cloud Representation Learning
Jul 04, 2022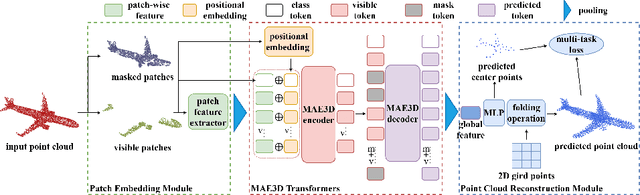



Transformer-based Self-supervised Representation Learning methods learn generic features from unlabeled datasets for providing useful network initialization parameters for downstream tasks. Recently, self-supervised learning based upon masking local surface patches for 3D point cloud data has been under-explored. In this paper, we propose masked Autoencoders in 3D point cloud representation learning (abbreviated as MAE3D), a novel autoencoding paradigm for self-supervised learning. We first split the input point cloud into patches and mask a portion of them, then use our Patch Embedding Module to extract the features of unmasked patches. Secondly, we employ patch-wise MAE3D Transformers to learn both local features of point cloud patches and high-level contextual relationships between patches and complete the latent representations of masked patches. We use our Point Cloud Reconstruction Module with multi-task loss to complete the incomplete point cloud as a result. We conduct self-supervised pre-training on ShapeNet55 with the point cloud completion pre-text task and fine-tune the pre-trained model on ModelNet40 and ScanObjectNN (PB\_T50\_RS, the hardest variant). Comprehensive experiments demonstrate that the local features extracted by our MAE3D from point cloud patches are beneficial for downstream classification tasks, soundly outperforming state-of-the-art methods ($93.4\%$ and $86.2\%$ classification accuracy, respectively).
Towards Uniform Point Distribution in Feature-preserving Point Cloud Filtering
Jan 17, 2022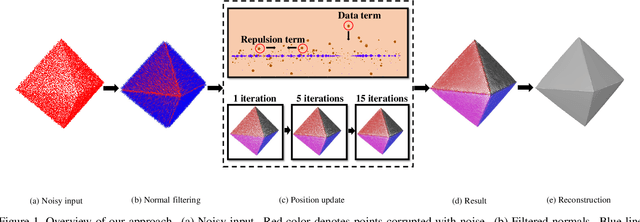
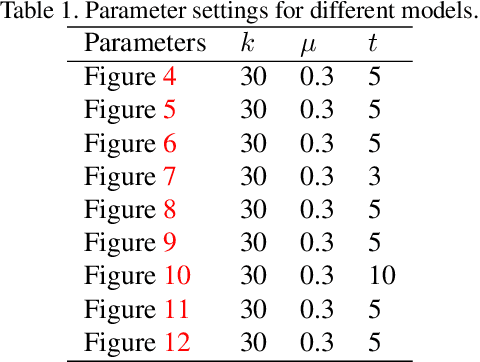
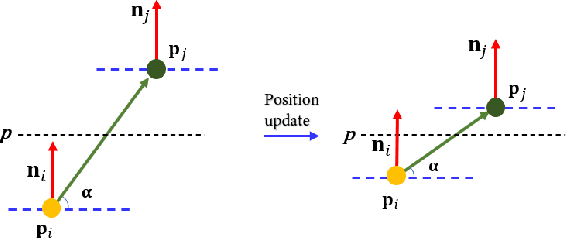
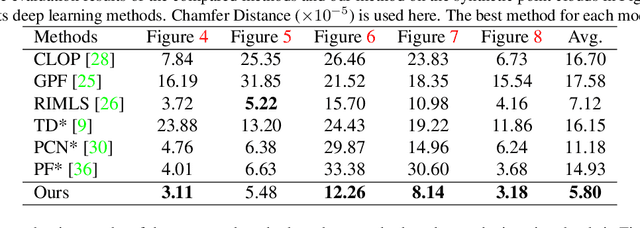
As a popular representation of 3D data, point cloud may contain noise and need to be filtered before use. Existing point cloud filtering methods either cannot preserve sharp features or result in uneven point distribution in the filtered output. To address this problem, this paper introduces a point cloud filtering method that considers both point distribution and feature preservation during filtering. The key idea is to incorporate a repulsion term with a data term in energy minimization. The repulsion term is responsible for the point distribution, while the data term is to approximate the noisy surfaces while preserving the geometric features. This method is capable of handling models with fine-scale features and sharp features. Extensive experiments show that our method yields better results with a more uniform point distribution ($5.8\times10^{-5}$ Chamfer Distance on average) in seconds.
Rethinking Point Cloud Filtering: A Non-Local Position Based Approach
Oct 14, 2021
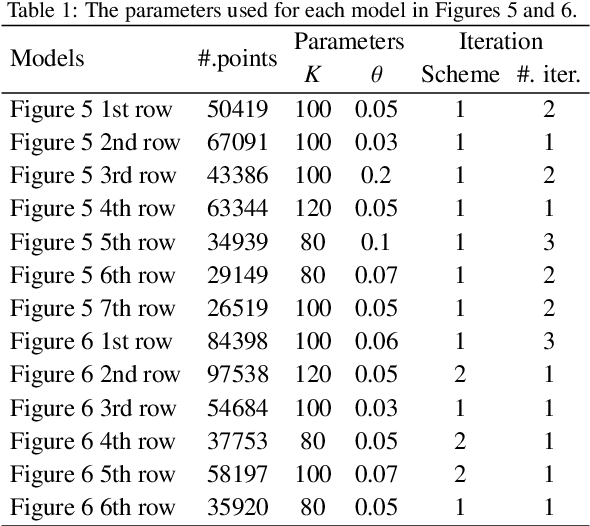
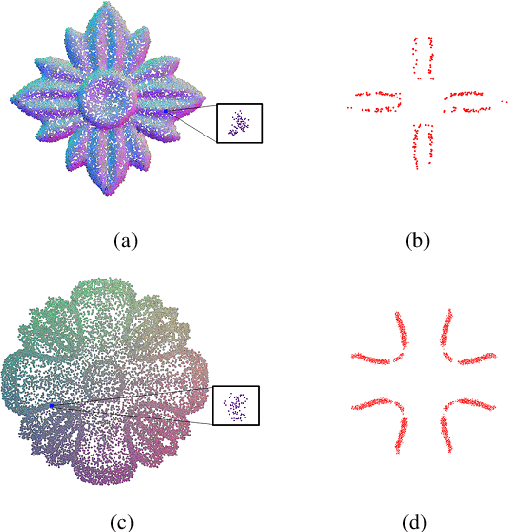
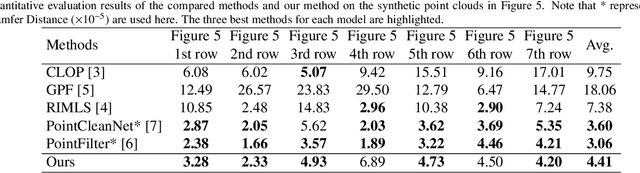
Existing position based point cloud filtering methods can hardly preserve sharp geometric features. In this paper, we rethink point cloud filtering from a non-learning non-local non-normal perspective, and propose a novel position based approach for feature-preserving point cloud filtering. Unlike normal based techniques, our method does not require the normal information. The core idea is to first design a similarity metric to search the non-local similar patches of a queried local patch. We then map the non-local similar patches into a canonical space and aggregate the non-local information. The aggregated outcome (i.e. coordinate) will be inversely mapped into the original space. Our method is simple yet effective. Extensive experiments validate our method, and show that it generally outperforms position based methods (deep learning and non-learning), and generates better or comparable outcomes to normal based techniques (deep learning and non-learning).
Unsupervised Representation Learning for 3D Point Cloud Data
Oct 13, 2021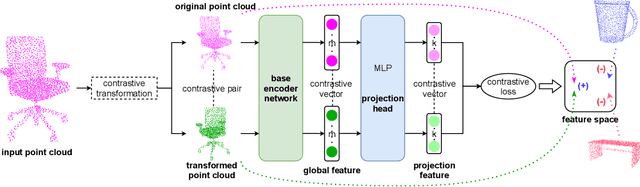


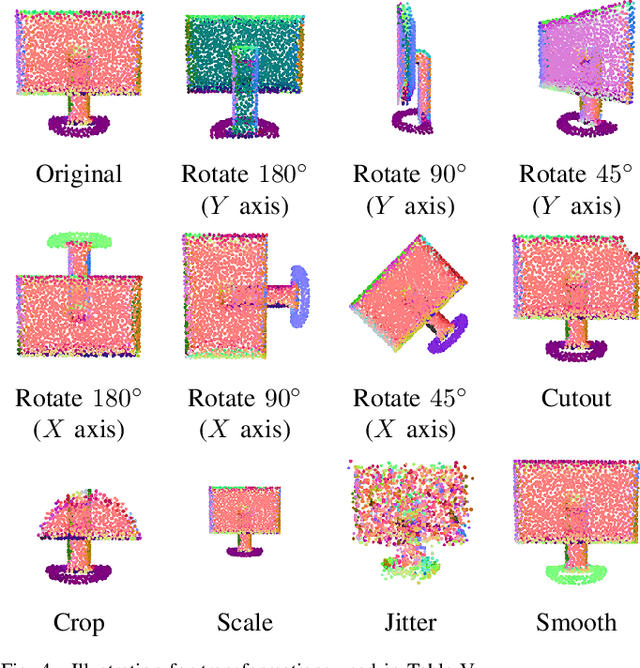
Though a number of point cloud learning methods have been proposed to handle unordered points, most of them are supervised and require labels for training. By contrast, unsupervised learning of point cloud data has received much less attention to date. In this paper, we propose a simple yet effective approach for unsupervised point cloud learning. In particular, we identify a very useful transformation which generates a good contrastive version of an original point cloud. They make up a pair. After going through a shared encoder and a shared head network, the consistency between the output representations are maximized with introducing two variants of contrastive losses to respectively facilitate downstream classification and segmentation. To demonstrate the efficacy of our method, we conduct experiments on three downstream tasks which are 3D object classification (on ModelNet40 and ModelNet10), shape part segmentation (on ShapeNet Part dataset) as well as scene segmentation (on S3DIS). Comprehensive results show that our unsupervised contrastive representation learning enables impressive outcomes in object classification and semantic segmentation. It generally outperforms current unsupervised methods, and even achieves comparable performance to supervised methods. Our source codes will be made publicly available.