 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDHGCN: Dynamic Hop Graph Convolution Network for Self-supervised Point Cloud Learning
Jan 05, 2024

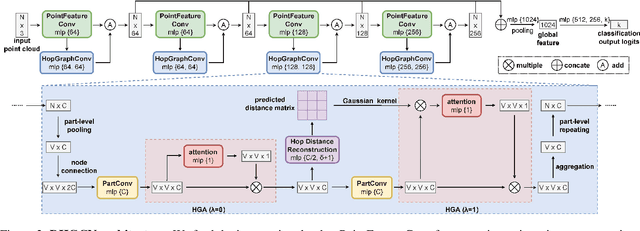

Recent works attempt to extend Graph Convolution Networks (GCNs) to point clouds for classification and segmentation tasks. These works tend to sample and group points to create smaller point sets locally and mainly focus on extracting local features through GCNs, while ignoring the relationship between point sets. In this paper, we propose the Dynamic Hop Graph Convolution Network (DHGCN) for explicitly learning the contextual relationships between the voxelized point parts, which are treated as graph nodes. Motivated by the intuition that the contextual information between point parts lies in the pairwise adjacent relationship, which can be depicted by the hop distance of the graph quantitatively, we devise a novel self-supervised part-level hop distance reconstruction task and design a novel loss function accordingly to facilitate training. In addition, we propose the Hop Graph Attention (HGA), which takes the learned hop distance as input for producing attention weights to allow edge features to contribute distinctively in aggregation. Eventually, the proposed DHGCN is a plug-and-play module that is compatible with point-based backbone networks. Comprehensive experiments on different backbones and tasks demonstrate that our self-supervised method achieves state-of-the-art performance. Our source code is available at: https://github.com/Jinec98/DHGCN.
Masked Autoencoders in 3D Point Cloud Representation Learning
Jul 04, 2022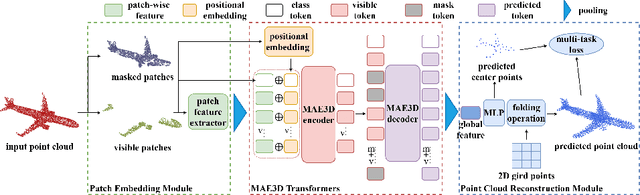



Transformer-based Self-supervised Representation Learning methods learn generic features from unlabeled datasets for providing useful network initialization parameters for downstream tasks. Recently, self-supervised learning based upon masking local surface patches for 3D point cloud data has been under-explored. In this paper, we propose masked Autoencoders in 3D point cloud representation learning (abbreviated as MAE3D), a novel autoencoding paradigm for self-supervised learning. We first split the input point cloud into patches and mask a portion of them, then use our Patch Embedding Module to extract the features of unmasked patches. Secondly, we employ patch-wise MAE3D Transformers to learn both local features of point cloud patches and high-level contextual relationships between patches and complete the latent representations of masked patches. We use our Point Cloud Reconstruction Module with multi-task loss to complete the incomplete point cloud as a result. We conduct self-supervised pre-training on ShapeNet55 with the point cloud completion pre-text task and fine-tune the pre-trained model on ModelNet40 and ScanObjectNN (PB\_T50\_RS, the hardest variant). Comprehensive experiments demonstrate that the local features extracted by our MAE3D from point cloud patches are beneficial for downstream classification tasks, soundly outperforming state-of-the-art methods ($93.4\%$ and $86.2\%$ classification accuracy, respectively).