 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Autoencoders in 3D Point Cloud Representation Learning
Paper and Code
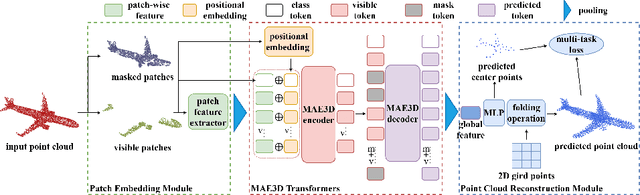



Transformer-based Self-supervised Representation Learning methods learn generic features from unlabeled datasets for providing useful network initialization parameters for downstream tasks. Recently, self-supervised learning based upon masking local surface patches for 3D point cloud data has been under-explored. In this paper, we propose masked Autoencoders in 3D point cloud representation learning (abbreviated as MAE3D), a novel autoencoding paradigm for self-supervised learning. We first split the input point cloud into patches and mask a portion of them, then use our Patch Embedding Module to extract the features of unmasked patches. Secondly, we employ patch-wise MAE3D Transformers to learn both local features of point cloud patches and high-level contextual relationships between patches and complete the latent representations of masked patches. We use our Point Cloud Reconstruction Module with multi-task loss to complete the incomplete point cloud as a result. We conduct self-supervised pre-training on ShapeNet55 with the point cloud completion pre-text task and fine-tune the pre-trained model on ModelNet40 and ScanObjectNN (PB\_T50\_RS, the hardest variant). Comprehensive experiments demonstrate that the local features extracted by our MAE3D from point cloud patches are beneficial for downstream classification tasks, soundly outperforming state-of-the-art methods ($93.4\%$ and $86.2\%$ classification accuracy, respectively).