 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact Analysis of Inference Time Attack of Perception Sensors on Autonomous Vehicles
May 05, 2025As a safety-critical cyber-physical system, cybersecurity and related safety issues for Autonomous Vehicles (AVs) have been important research topics for a while. Among all the modules on AVs, perception is one of the most accessible attack surfaces, as drivers and AVs have no control over the outside environment. Most current work targeting perception security for AVs focuses on perception correctness. In this work, we propose an impact analysis based on inference time attacks for autonomous vehicles. We demonstrate in a simulation system that such inference time attacks can also threaten the safety of both the ego vehicle and other traffic participants.
Mono3R: Exploiting Monocular Cues for Geometric 3D Reconstruction
Apr 18, 2025Recent advances in data-driven geometric multi-view 3D reconstruction foundation models (e.g., DUSt3R) have shown remarkable performance across various 3D vision tasks, facilitated by the release of large-scale, high-quality 3D datasets. However, as we observed, constrained by their matching-based principles, the reconstruction quality of existing models suffers significant degradation in challenging regions with limited matching cues, particularly in weakly textured areas and low-light conditions. To mitigate these limitations, we propose to harness the inherent robustness of monocular geometry estimation to compensate for the inherent shortcomings of matching-based methods. Specifically, we introduce a monocular-guided refinement module that integrates monocular geometric priors into multi-view reconstruction frameworks. This integration substantially enhances the robustness of multi-view reconstruction systems, leading to high-quality feed-forward reconstructions. Comprehensive experiments across multiple benchmarks demonstrate that our method achieves substantial improvements in both mutli-view camera pose estimation and point cloud accuracy.
Regist3R: Incremental Registration with Stereo Foundation Model
Apr 16, 2025Multi-view 3D reconstruction has remained an essential yet challenging problem in the field of computer vision. While DUSt3R and its successors have achieved breakthroughs in 3D reconstruction from unposed images, these methods exhibit significant limitations when scaling to multi-view scenarios, including high computational cost and cumulative error induced by global alignment. To address these challenges, we propose Regist3R, a novel stereo foundation model tailored for efficient and scalable incremental reconstruction. Regist3R leverages an incremental reconstruction paradigm, enabling large-scale 3D reconstructions from unordered and many-view image collections. We evaluate Regist3R on public datasets for camera pose estimation and 3D reconstruction. Our experiments demonstrate that Regist3R achieves comparable performance with optimization-based methods while significantly improving computational efficiency, and outperforms existing multi-view reconstruction models. Furthermore, to assess its performance in real-world applications, we introduce a challenging oblique aerial dataset which has long spatial spans and hundreds of views. The results highlight the effectiveness of Regist3R. We also demonstrate the first attempt to reconstruct large-scale scenes encompassing over thousands of views through pointmap-based foundation models, showcasing its potential for practical applications in large-scale 3D reconstruction tasks, including urban modeling, aerial mapping, and beyond.
KoGNER: A Novel Framework for Knowledge Graph Distillation on Biomedical Named Entity Recognition
Mar 19, 2025Named Entity Recognition (NER) is a fundamental task in Natural Language Processing (NLP) that plays a crucial role in information extraction, question answering, and knowledge-based systems. Traditional deep learning-based NER models often struggle with domain-specific generalization and suffer from data sparsity issues. In this work, we introduce Knowledge Graph distilled for Named Entity Recognition (KoGNER), a novel approach that integrates Knowledge Graph (KG) distillation into NER models to enhance entity recognition performance. Our framework leverages structured knowledge representations from KGs to enrich contextual embeddings, thereby improving entity classification and reducing ambiguity in entity detection. KoGNER employs a two-step process: (1) Knowledge Distillation, where external knowledge sources are distilled into a lightweight representation for seamless integration with NER models, and (2) Entity-Aware Augmentation, which integrates contextual embeddings that have been enriched with knowledge graph information directly into GNN, thereby improving the model's ability to understand and represent entity relationships. Experimental results on benchmark datasets demonstrate that KoGNER achieves state-of-the-art performance, outperforming finetuned NER models and LLMs by a significant margin. These findings suggest that leveraging knowledge graphs as auxiliary information can significantly improve NER accuracy, making KoGNER a promising direction for future research in knowledge-aware NLP.
VoxNeuS: Enhancing Voxel-Based Neural Surface Reconstruction via Gradient Interpolation
Jun 11, 2024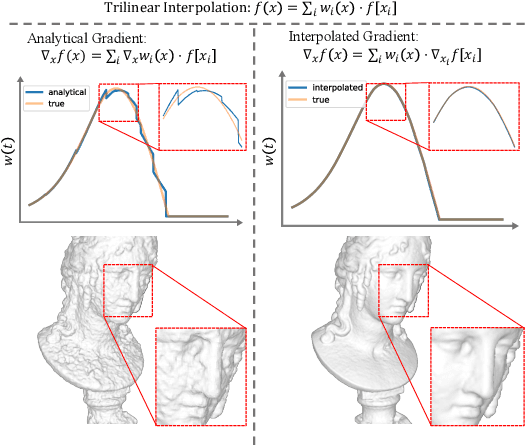
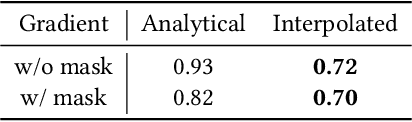
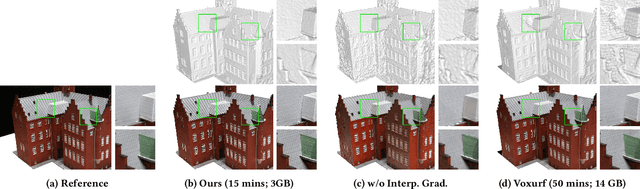
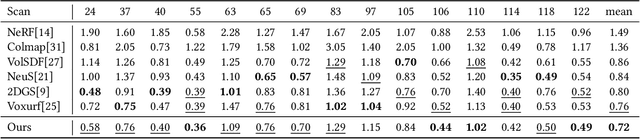
Neural Surface Reconstruction learns a Signed Distance Field~(SDF) to reconstruct the 3D model from multi-view images. Previous works adopt voxel-based explicit representation to improve efficiency. However, they ignored the gradient instability of interpolation in the voxel grid, leading to degradation on convergence and smoothness. Besides, previous works entangled the optimization of geometry and radiance, which leads to the deformation of geometry to explain radiance, causing artifacts when reconstructing textured planes. In this work, we reveal that the instability of gradient comes from its discontinuity during trilinear interpolation, and propose to use the interpolated gradient instead of the original analytical gradient to eliminate the discontinuity. Based on gradient interpolation, we propose VoxNeuS, a lightweight surface reconstruction method for computational and memory efficient neural surface reconstruction. Thanks to the explicit representation, the gradient of regularization terms, i.e. Eikonal and curvature loss, are directly solved, avoiding computation and memory-access overhead. Further, VoxNeuS adopts a geometry-radiance disentangled architecture to handle the geometry deformation from radiance optimization. The experimental results show that VoxNeuS achieves better reconstruction quality than previous works. The entire training process takes 15 minutes and less than 3 GB of memory on a single 2080ti GPU.
Tele-Aloha: A Low-budget and High-authenticity Telepresence System Using Sparse RGB Cameras
May 23, 2024
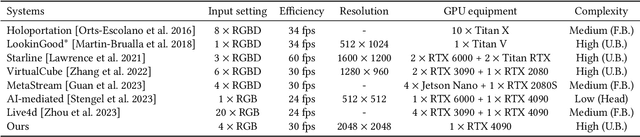

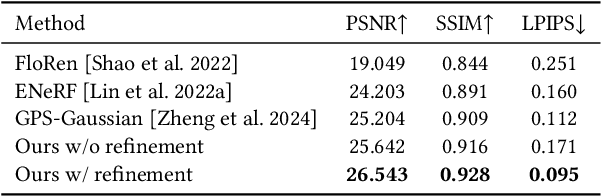
In this paper, we present a low-budget and high-authenticity bidirectional telepresence system, Tele-Aloha, targeting peer-to-peer communication scenarios. Compared to previous systems, Tele-Aloha utilizes only four sparse RGB cameras, one consumer-grade GPU, and one autostereoscopic screen to achieve high-resolution (2048x2048), real-time (30 fps), low-latency (less than 150ms) and robust distant communication. As the core of Tele-Aloha, we propose an efficient novel view synthesis algorithm for upper-body. Firstly, we design a cascaded disparity estimator for obtaining a robust geometry cue. Additionally a neural rasterizer via Gaussian Splatting is introduced to project latent features onto target view and to decode them into a reduced resolution. Further, given the high-quality captured data, we leverage weighted blending mechanism to refine the decoded image into the final resolution of 2K. Exploiting world-leading autostereoscopic display and low-latency iris tracking, users are able to experience a strong three-dimensional sense even without any wearable head-mounted display device. Altogether, our telepresence system demonstrates the sense of co-presence in real-life experiments, inspiring the next generation of communication.
DistGrid: Scalable Scene Reconstruction with Distributed Multi-resolution Hash Grid
May 08, 2024



Neural Radiance Field~(NeRF) achieves extremely high quality in object-scaled and indoor scene reconstruction. However, there exist some challenges when reconstructing large-scale scenes. MLP-based NeRFs suffer from limited network capacity, while volume-based NeRFs are heavily memory-consuming when the scene resolution increases. Recent approaches propose to geographically partition the scene and learn each sub-region using an individual NeRF. Such partitioning strategies help volume-based NeRF exceed the single GPU memory limit and scale to larger scenes. However, this approach requires multiple background NeRF to handle out-of-partition rays, which leads to redundancy of learning. Inspired by the fact that the background of current partition is the foreground of adjacent partition, we propose a scalable scene reconstruction method based on joint Multi-resolution Hash Grids, named DistGrid. In this method, the scene is divided into multiple closely-paved yet non-overlapped Axis-Aligned Bounding Boxes, and a novel segmented volume rendering method is proposed to handle cross-boundary rays, thereby eliminating the need for background NeRFs. The experiments demonstrate that our method outperforms existing methods on all evaluated large-scale scenes, and provides visually plausible scene reconstruction. The scalability of our method on reconstruction quality is further evaluated qualitatively and quantitatively.
Generating Diverse Criteria On-the-Fly to Improve Point-wise LLM Rankers
Apr 18, 2024The most recent pointwise Large Language Model (LLM) rankers have achieved remarkable ranking results. However, these rankers are hindered by two major drawbacks: (1) they fail to follow a standardized comparison guidance during the ranking process, and (2) they struggle with comprehensive considerations when dealing with complicated passages. To address these shortcomings, we propose to build a ranker that generates ranking scores based on a set of criteria from various perspectives. These criteria are intended to direct each perspective in providing a distinct yet synergistic evaluation. Our research, which examines eight datasets from the BEIR benchmark demonstrates that incorporating this multi-perspective criteria ensemble approach markedly enhanced the performance of pointwise LLM rankers.
AbsGS: Recovering Fine Details for 3D Gaussian Splatting
Apr 16, 2024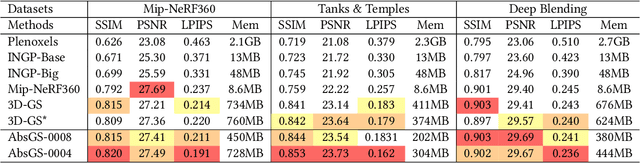

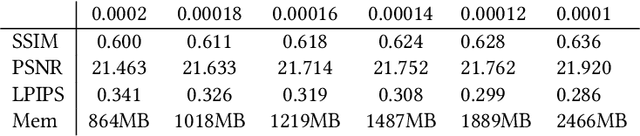
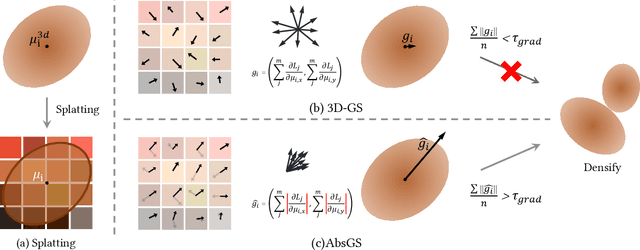
3D Gaussian Splatting (3D-GS) technique couples 3D Gaussian primitives with differentiable rasterization to achieve high-quality novel view synthesis results while providing advanced real-time rendering performance. However, due to the flaw of its adaptive density control strategy in 3D-GS, it frequently suffers from over-reconstruction issue in intricate scenes containing high-frequency details, leading to blurry rendered images. The underlying reason for the flaw has still been under-explored. In this work, we present a comprehensive analysis of the cause of aforementioned artifacts, namely gradient collision, which prevents large Gaussians in over-reconstructed regions from splitting. To address this issue, we propose the novel homodirectional view-space positional gradient as the criterion for densification. Our strategy efficiently identifies large Gaussians in over-reconstructed regions, and recovers fine details by splitting. We evaluate our proposed method on various challenging datasets. The experimental results indicate that our approach achieves the best rendering quality with reduced or similar memory consumption. Our method is easy to implement and can be incorporated into a wide variety of most recent Gaussian Splatting-based methods. We will open source our codes upon formal publication. Our project page is available at: https://ty424.github.io/AbsGS.github.io/
ShoeModel: Learning to Wear on the User-specified Shoes via Diffusion Model
Apr 07, 2024



With the development of the large-scale diffusion model, Artificial Intelligence Generated Content (AIGC) techniques are popular recently. However, how to truly make it serve our daily lives remains an open question. To this end, in this paper, we focus on employing AIGC techniques in one filed of E-commerce marketing, i.e., generating hyper-realistic advertising images for displaying user-specified shoes by human. Specifically, we propose a shoe-wearing system, called Shoe-Model, to generate plausible images of human legs interacting with the given shoes. It consists of three modules: (1) shoe wearable-area detection module (WD), (2) leg-pose synthesis module (LpS) and the final (3) shoe-wearing image generation module (SW). Them three are performed in ordered stages. Compared to baselines, our ShoeModel is shown to generalize better to different type of shoes and has ability of keeping the ID-consistency of the given shoes, as well as automatically producing reasonable interactions with human. Extensive experiments show the effectiveness of our proposed shoe-wearing system. Figure 1 shows the input and output examples of our ShoeModel.