 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Decoder-Based Language Models for Diverse Encoder Downstream Tasks
Mar 04, 2025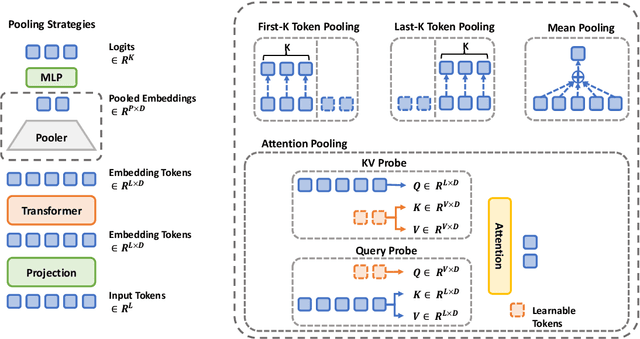
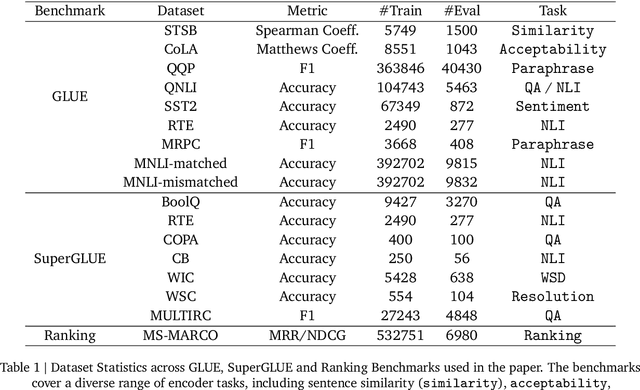
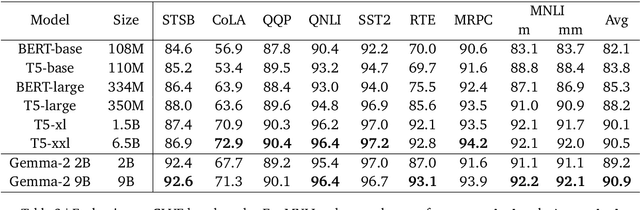
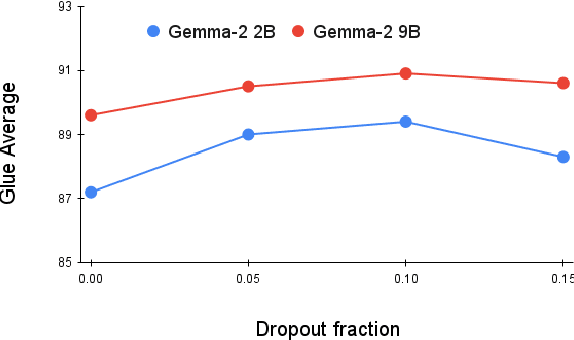
Decoder-based transformers, while revolutionizing language modeling and scaling to immense sizes, have not completely overtaken encoder-heavy architectures in natural language processing. Specifically, encoder-only models remain dominant in tasks like classification, regression, and ranking. This is primarily due to the inherent structure of decoder-based models, which limits their direct applicability to these tasks. In this paper, we introduce Gemma Encoder, adapting the powerful Gemma decoder model to an encoder architecture, thereby unlocking its potential for a wider range of non-generative applications. To optimize the adaptation from decoder to encoder, we systematically analyze various pooling strategies, attention mechanisms, and hyperparameters (e.g., dropout rate). Furthermore, we benchmark Gemma Encoder against established approaches on the GLUE benchmarks, and MS MARCO ranking benchmark, demonstrating its effectiveness and versatility.
Generating Diverse Criteria On-the-Fly to Improve Point-wise LLM Rankers
Apr 18, 2024The most recent pointwise Large Language Model (LLM) rankers have achieved remarkable ranking results. However, these rankers are hindered by two major drawbacks: (1) they fail to follow a standardized comparison guidance during the ranking process, and (2) they struggle with comprehensive considerations when dealing with complicated passages. To address these shortcomings, we propose to build a ranker that generates ranking scores based on a set of criteria from various perspectives. These criteria are intended to direct each perspective in providing a distinct yet synergistic evaluation. Our research, which examines eight datasets from the BEIR benchmark demonstrates that incorporating this multi-perspective criteria ensemble approach markedly enhanced the performance of pointwise LLM rankers.
Consolidating Ranking and Relevance Predictions of Large Language Models through Post-Processing
Apr 17, 2024



The powerful generative abilities of large language models (LLMs) show potential in generating relevance labels for search applications. Previous work has found that directly asking about relevancy, such as ``How relevant is document A to query Q?", results in sub-optimal ranking. Instead, the pairwise ranking prompting (PRP) approach produces promising ranking performance through asking about pairwise comparisons, e.g., ``Is document A more relevant than document B to query Q?". Thus, while LLMs are effective at their ranking ability, this is not reflected in their relevance label generation. In this work, we propose a post-processing method to consolidate the relevance labels generated by an LLM with its powerful ranking abilities. Our method takes both LLM generated relevance labels and pairwise preferences. The labels are then altered to satisfy the pairwise preferences of the LLM, while staying as close to the original values as possible. Our experimental results indicate that our approach effectively balances label accuracy and ranking performance. Thereby, our work shows it is possible to combine both the ranking and labeling abilities of LLMs through post-processing.
Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels
Oct 21, 2023Zero-shot text rankers powered by recent LLMs achieve remarkable ranking performance by simply prompting. Existing prompts for pointwise LLM rankers mostly ask the model to choose from binary relevance labels like "Yes" and "No". However, the lack of intermediate relevance label options may cause the LLM to provide noisy or biased answers for documents that are partially relevant to the query. We propose to incorporate fine-grained relevance labels into the prompt for LLM rankers, enabling them to better differentiate among documents with different levels of relevance to the query and thus derive a more accurate ranking. We study two variants of the prompt template, coupled with different numbers of relevance levels. Our experiments on 8 BEIR data sets show that adding fine-grained relevance labels significantly improves the performance of LLM rankers.
Learning to Rank when Grades Matter
Jun 20, 2023
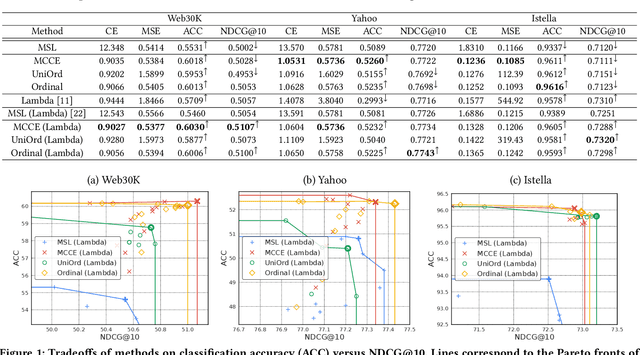
Graded labels are ubiquitous in real-world learning-to-rank applications, especially in human rated relevance data. Traditional learning-to-rank techniques aim to optimize the ranked order of documents. They typically, however, ignore predicting actual grades. This prevents them from being adopted in applications where grades matter, such as filtering out ``poor'' documents. Achieving both good ranking performance and good grade prediction performance is still an under-explored problem. Existing research either focuses only on ranking performance by not calibrating model outputs, or treats grades as numerical values, assuming labels are on a linear scale and failing to leverage the ordinal grade information. In this paper, we conduct a rigorous study of learning to rank with grades, where both ranking performance and grade prediction performance are important. We provide a formal discussion on how to perform ranking with non-scalar predictions for grades, and propose a multiobjective formulation to jointly optimize both ranking and grade predictions. In experiments, we verify on several public datasets that our methods are able to push the Pareto frontier of the tradeoff between ranking and grade prediction performance, showing the benefit of leveraging ordinal grade information.
RD-Suite: A Benchmark for Ranking Distillation
Jun 12, 2023



The distillation of ranking models has become an important topic in both academia and industry. In recent years, several advanced methods have been proposed to tackle this problem, often leveraging ranking information from teacher rankers that is absent in traditional classification settings. To date, there is no well-established consensus on how to evaluate this class of models. Moreover, inconsistent benchmarking on a wide range of tasks and datasets make it difficult to assess or invigorate advances in this field. This paper first examines representative prior arts on ranking distillation, and raises three questions to be answered around methodology and reproducibility. To that end, we propose a systematic and unified benchmark, Ranking Distillation Suite (RD-Suite), which is a suite of tasks with 4 large real-world datasets, encompassing two major modalities (textual and numeric) and two applications (standard distillation and distillation transfer). RD-Suite consists of benchmark results that challenge some of the common wisdom in the field, and the release of datasets with teacher scores and evaluation scripts for future research. RD-Suite paves the way towards better understanding of ranking distillation, facilities more research in this direction, and presents new challenges.
Towards Disentangling Relevance and Bias in Unbiased Learning to Rank
Dec 28, 2022Unbiased learning to rank (ULTR) studies the problem of mitigating various biases from implicit user feedback data such as clicks, and has been receiving considerable attention recently. A popular ULTR approach for real-world applications uses a two-tower architecture, where click modeling is factorized into a relevance tower with regular input features, and a bias tower with bias-relevant inputs such as the position of a document. A successful factorization will allow the relevance tower to be exempt from biases. In this work, we identify a critical issue that existing ULTR methods ignored - the bias tower can be confounded with the relevance tower via the underlying true relevance. In particular, the positions were determined by the logging policy, i.e., the previous production model, which would possess relevance information. We give both theoretical analysis and empirical results to show the negative effects on relevance tower due to such a correlation. We then propose three methods to mitigate the negative confounding effects by better disentangling relevance and bias. Empirical results on both controlled public datasets and a large-scale industry dataset show the effectiveness of the proposed approaches.
Rank4Class: A Ranking Formulation for Multiclass Classification
Dec 17, 2021



Multiclass classification (MCC) is a fundamental machine learning problem which aims to classify each instance into one of a predefined set of classes. Given an instance, a classification model computes a score for each class, all of which are then used to sort the classes. The performance of a classification model is usually measured by Top-K Accuracy/Error (e.g., K=1 or 5). In this paper, we do not aim to propose new neural representation learning models as most recent works do, but to show that it is easy to boost MCC performance with a novel formulation through the lens of ranking. In particular, by viewing MCC as to rank classes for an instance, we first argue that ranking metrics, such as Normalized Discounted Cumulative Gain (NDCG), can be more informative than existing Top-K metrics. We further demonstrate that the dominant neural MCC architecture can be formulated as a neural ranking framework with a specific set of design choices. Based on such generalization, we show that it is straightforward and intuitive to leverage techniques from the rich information retrieval literature to improve the MCC performance out of the box. Extensive empirical results on both text and image classification tasks with diverse datasets and backbone models (e.g., BERT and ResNet for text and image classification) show the value of our proposed framework.
Born Again Neural Rankers
Sep 30, 2021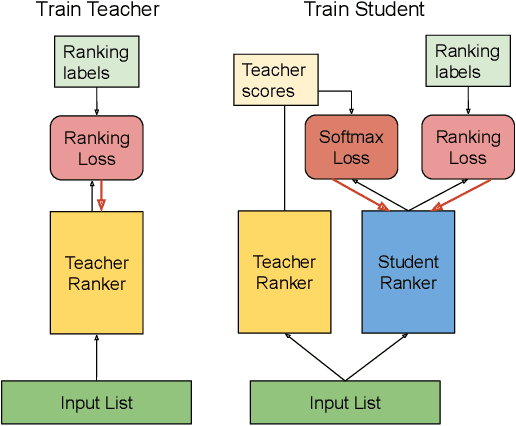
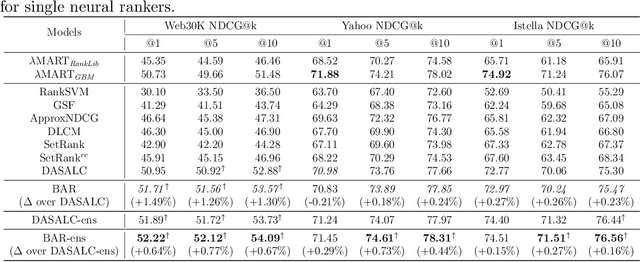
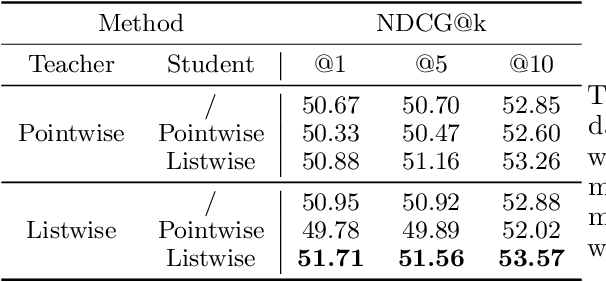
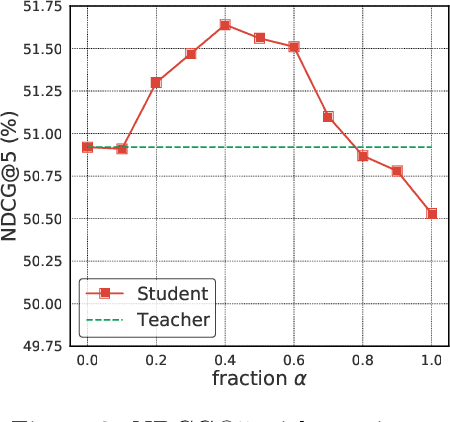
We introduce Born Again neural Rankers (BAR) in the Learning to Rank (LTR) setting, where student rankers, trained in the Knowledge Distillation (KD) framework, are parameterized identically to their teachers. Unlike the existing ranking distillation work which pursues a good trade-off between performance and efficiency, BAR adapts the idea of Born Again Networks (BAN) to ranking problems and significantly improves ranking performance of students over the teacher rankers without increasing model capacity. The key differences between BAR and common distillation techniques for classification are: (1) an appropriate teacher score transformation function, and (2) a novel listwise distillation framework. Both techniques are specifically designed for ranking problems and are rarely studied in the knowledge distillation literature. Using the state-of-the-art neural ranking structure, BAR is able to push the limits of neural rankers above a recent rigorous benchmark study and significantly outperforms traditionally strong gradient boosted decision tree based models on 7 out of 9 key metrics, the first time in the literature. In addition to the strong empirical results, we give theoretical explanations on why listwise distillation is effective for neural rankers.
Stream-Flow Forecasting of Small Rivers Based on LSTM
Jan 16, 2020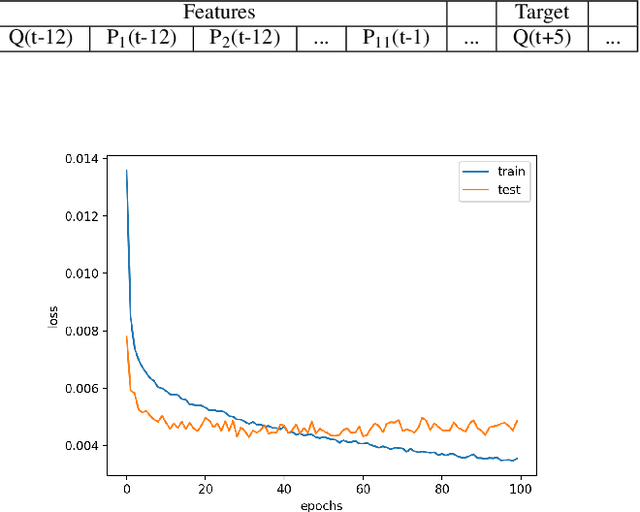
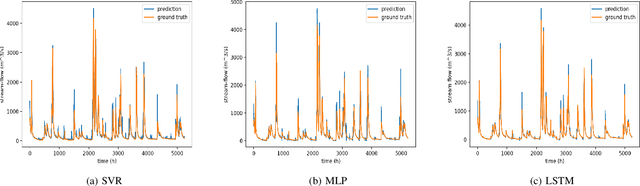
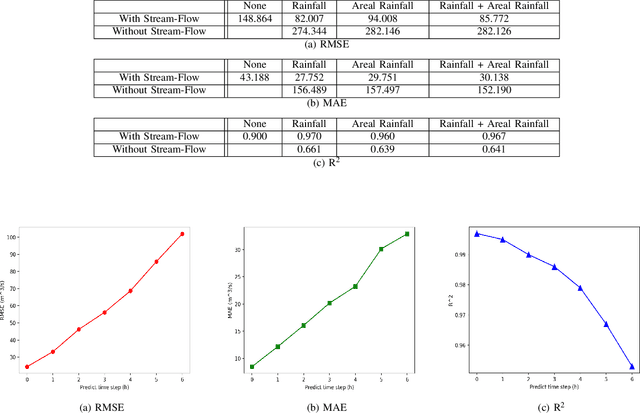
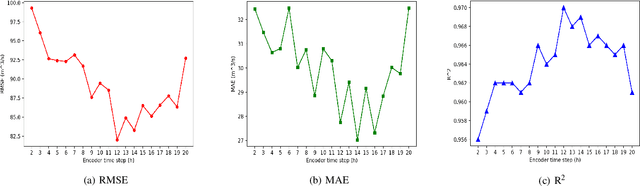
Stream-flow forecasting for small rivers has always been of great importance, yet comparatively challenging due to the special features of rivers with smaller volume. Artificial Intelligence (AI) methods have been employed in this area for long, but improvement of forecast quality is still on the way. In this paper, we tried to provide a new method to do the forecast using the Long-Short Term Memory (LSTM) deep learning model, which aims in the field of time-series data. Utilizing LSTM, we collected the stream flow data from one hydrologic station in Tunxi, China, and precipitation data from 11 rainfall stations around to forecast the stream flow data from that hydrologic station 6 hours in the future. We evaluated the prediction results using three criteria: root mean square error (RMSE), mean absolute error (MAE), and coefficient of determination (R^2). By comparing LSTM's prediction with predictions of Support Vector Regression (SVR) and Multilayer Perceptions (MLP) models, we showed that LSTM has better performance, achieving RMSE of 82.007, MAE of 27.752, and R^2 of 0.970. We also did extended experiments on LSTM model, discussing influence factors of its performance.