 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Regularised Reinforcement Learning for Large Language Models Alignment
May 29, 2024The dominant framework for alignment of large language models (LLM), whether through reinforcement learning from human feedback or direct preference optimisation, is to learn from preference data. This involves building datasets where each element is a quadruplet composed of a prompt, two independent responses (completions of the prompt) and a human preference between the two independent responses, yielding a preferred and a dis-preferred response. Such data is typically scarce and expensive to collect. On the other hand, \emph{single-trajectory} datasets where each element is a triplet composed of a prompt, a response and a human feedback is naturally more abundant. The canonical element of such datasets is for instance an LLM's response to a user's prompt followed by a user's feedback such as a thumbs-up/down. Consequently, in this work, we propose DRO, or \emph{Direct Reward Optimisation}, as a framework and associated algorithms that do not require pairwise preferences. DRO uses a simple mean-squared objective that can be implemented in various ways. We validate our findings empirically, using T5 encoder-decoder language models, and show DRO's performance over selected baselines such as Kahneman-Tversky Optimization (KTO). Thus, we confirm that DRO is a simple and empirically compelling method for single-trajectory policy optimisation.
Learning to Rank when Grades Matter
Jun 20, 2023
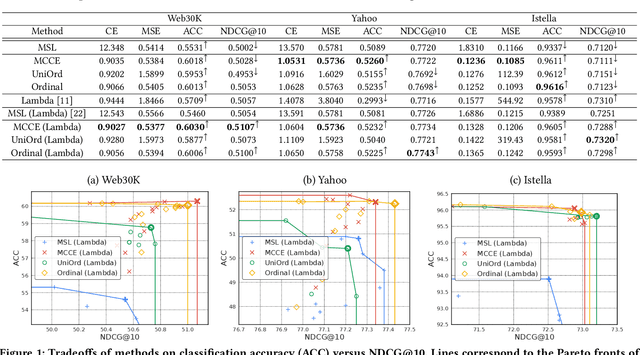
Graded labels are ubiquitous in real-world learning-to-rank applications, especially in human rated relevance data. Traditional learning-to-rank techniques aim to optimize the ranked order of documents. They typically, however, ignore predicting actual grades. This prevents them from being adopted in applications where grades matter, such as filtering out ``poor'' documents. Achieving both good ranking performance and good grade prediction performance is still an under-explored problem. Existing research either focuses only on ranking performance by not calibrating model outputs, or treats grades as numerical values, assuming labels are on a linear scale and failing to leverage the ordinal grade information. In this paper, we conduct a rigorous study of learning to rank with grades, where both ranking performance and grade prediction performance are important. We provide a formal discussion on how to perform ranking with non-scalar predictions for grades, and propose a multiobjective formulation to jointly optimize both ranking and grade predictions. In experiments, we verify on several public datasets that our methods are able to push the Pareto frontier of the tradeoff between ranking and grade prediction performance, showing the benefit of leveraging ordinal grade information.
Dropout Prediction Variation Estimation Using Neuron Activation Strength
Oct 25, 2021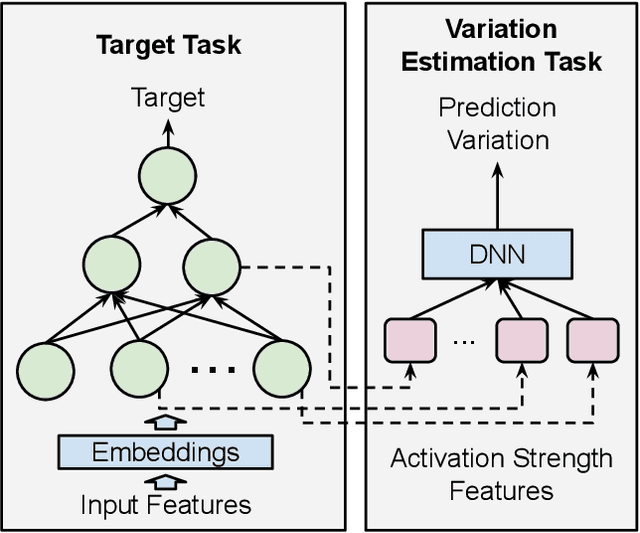
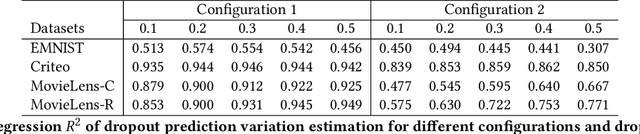
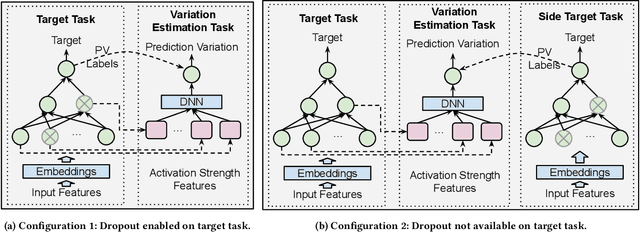
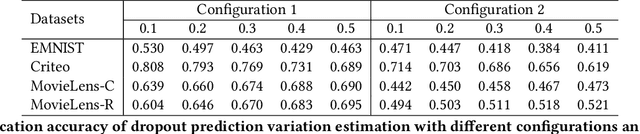
It is well-known that deep neural networks generate different predictions even given the same model configuration and training dataset. It thus becomes more and more important to study prediction variation, the variation of the predictions on a given input example, in neural network models. Dropout has been commonly used in various applications to quantify prediction variations. However, using dropout in practice can be expensive as it requires running dropout inferences many times to estimate prediction variation. We study how to estimate dropout prediction variation in a resource-efficient manner. We demonstrate that we can use neuron activation strengths to estimate dropout prediction variation under different dropout settings and on a variety of tasks using three large datasets, MovieLens, Criteo, and EMNIST. Our approach provides an inference-once alternative to estimate dropout prediction variation as an auxiliary task. Moreover, we demonstrate that using activation features from a subset of the neural network layers can be sufficient to achieve variation estimation performance almost comparable to that of using activation features from all layers, thus reducing resources even further for variation estimation.