 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterleaved Reasoning for Large Language Models via Reinforcement Learning
May 26, 2025Long chain-of-thought (CoT) significantly enhances large language models' (LLM) reasoning capabilities. However, the extensive reasoning traces lead to inefficiencies and an increased time-to-first-token (TTFT). We propose a novel training paradigm that uses reinforcement learning (RL) to guide reasoning LLMs to interleave thinking and answering for multi-hop questions. We observe that models inherently possess the ability to perform interleaved reasoning, which can be further enhanced through RL. We introduce a simple yet effective rule-based reward to incentivize correct intermediate steps, which guides the policy model toward correct reasoning paths by leveraging intermediate signals generated during interleaved reasoning. Extensive experiments conducted across five diverse datasets and three RL algorithms (PPO, GRPO, and REINFORCE++) demonstrate consistent improvements over traditional think-answer reasoning, without requiring external tools. Specifically, our approach reduces TTFT by over 80% on average and improves up to 19.3% in Pass@1 accuracy. Furthermore, our method, trained solely on question answering and logical reasoning datasets, exhibits strong generalization ability to complex reasoning datasets such as MATH, GPQA, and MMLU. Additionally, we conduct in-depth analysis to reveal several valuable insights into conditional reward modeling.
Learning to Rank when Grades Matter
Jun 20, 2023
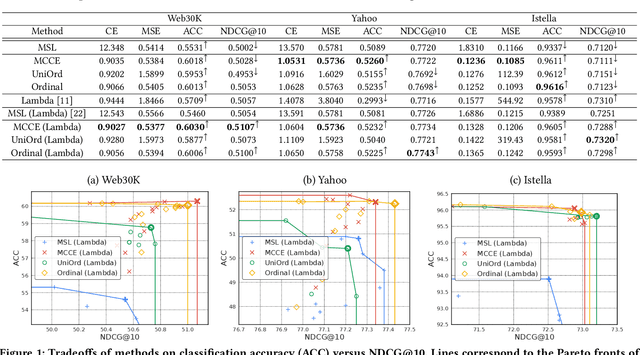
Graded labels are ubiquitous in real-world learning-to-rank applications, especially in human rated relevance data. Traditional learning-to-rank techniques aim to optimize the ranked order of documents. They typically, however, ignore predicting actual grades. This prevents them from being adopted in applications where grades matter, such as filtering out ``poor'' documents. Achieving both good ranking performance and good grade prediction performance is still an under-explored problem. Existing research either focuses only on ranking performance by not calibrating model outputs, or treats grades as numerical values, assuming labels are on a linear scale and failing to leverage the ordinal grade information. In this paper, we conduct a rigorous study of learning to rank with grades, where both ranking performance and grade prediction performance are important. We provide a formal discussion on how to perform ranking with non-scalar predictions for grades, and propose a multiobjective formulation to jointly optimize both ranking and grade predictions. In experiments, we verify on several public datasets that our methods are able to push the Pareto frontier of the tradeoff between ranking and grade prediction performance, showing the benefit of leveraging ordinal grade information.
On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models
Sep 12, 2022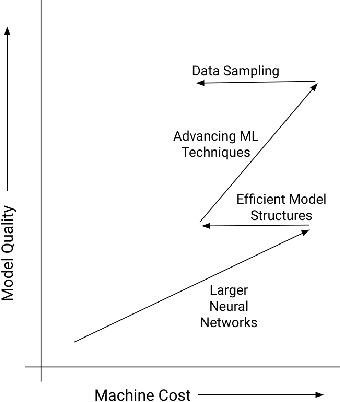
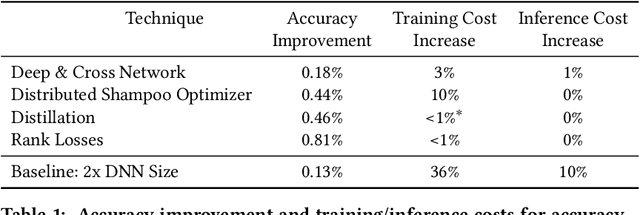
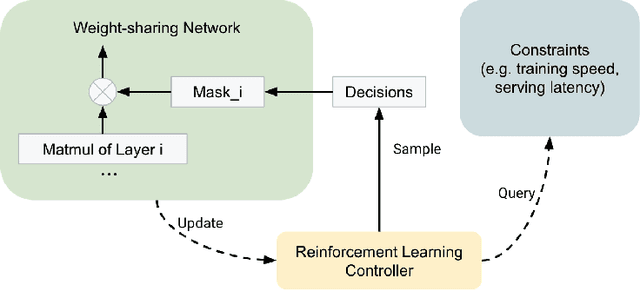

For industrial-scale advertising systems, prediction of ad click-through rate (CTR) is a central problem. Ad clicks constitute a significant class of user engagements and are often used as the primary signal for the usefulness of ads to users. Additionally, in cost-per-click advertising systems where advertisers are charged per click, click rate expectations feed directly into value estimation. Accordingly, CTR model development is a significant investment for most Internet advertising companies. Engineering for such problems requires many machine learning (ML) techniques suited to online learning that go well beyond traditional accuracy improvements, especially concerning efficiency, reproducibility, calibration, credit attribution. We present a case study of practical techniques deployed in Google's search ads CTR model. This paper provides an industry case study highlighting important areas of current ML research and illustrating how impactful new ML methods are evaluated and made useful in a large-scale industrial setting.
Real World Large Scale Recommendation Systems Reproducibility and Smooth Activations
Feb 14, 2022Real world recommendation systems influence a constantly growing set of domains. With deep networks, that now drive such systems, recommendations have been more relevant to the user's interests and tasks. However, they may not always be reproducible even if produced by the same system for the same user, recommendation sequence, request, or query. This problem received almost no attention in academic publications, but is, in fact, very realistic and critical in real production systems. We consider reproducibility of real large scale deep models, whose predictions determine such recommendations. We demonstrate that the celebrated Rectified Linear Unit (ReLU) activation, used in deep models, can be a major contributor to irreproducibility. We propose the use of smooth activations to improve recommendation reproducibility. We describe a novel family of smooth activations; Smooth ReLU (SmeLU), designed to improve reproducibility with mathematical simplicity, with potentially cheaper implementation. SmeLU is a member of a wider family of smooth activations. While other techniques that improve reproducibility in real systems usually come at accuracy costs, smooth activations not only improve reproducibility, but can even give accuracy gains. We report metrics from real systems in which we were able to productionalize SmeLU with substantial reproducibility gains and better accuracy-reproducibility trade-offs. These include click-through-rate (CTR) prediction systems, content, and application recommendation systems.
Dropout Prediction Variation Estimation Using Neuron Activation Strength
Oct 25, 2021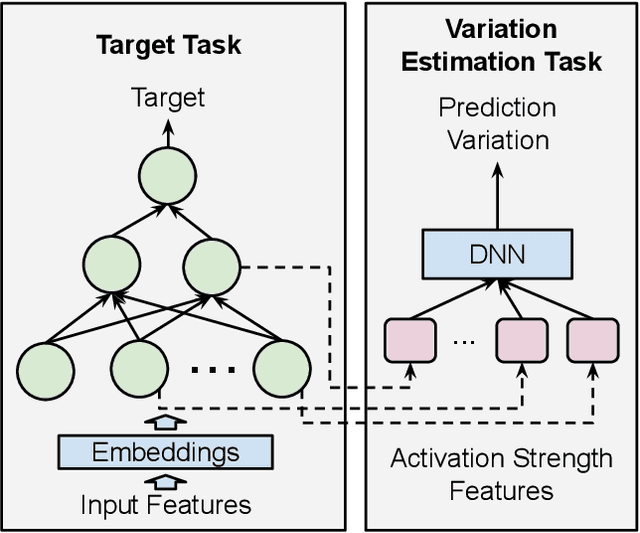
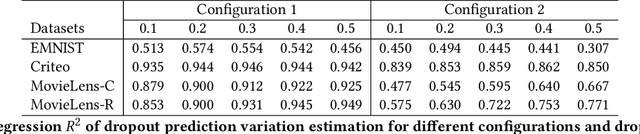
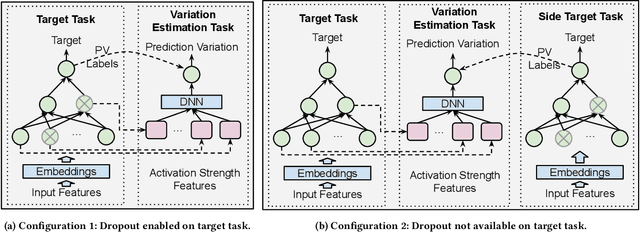
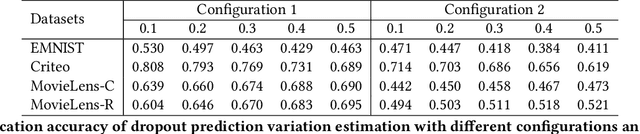
It is well-known that deep neural networks generate different predictions even given the same model configuration and training dataset. It thus becomes more and more important to study prediction variation, the variation of the predictions on a given input example, in neural network models. Dropout has been commonly used in various applications to quantify prediction variations. However, using dropout in practice can be expensive as it requires running dropout inferences many times to estimate prediction variation. We study how to estimate dropout prediction variation in a resource-efficient manner. We demonstrate that we can use neuron activation strengths to estimate dropout prediction variation under different dropout settings and on a variety of tasks using three large datasets, MovieLens, Criteo, and EMNIST. Our approach provides an inference-once alternative to estimate dropout prediction variation as an auxiliary task. Moreover, we demonstrate that using activation features from a subset of the neural network layers can be sufficient to achieve variation estimation performance almost comparable to that of using activation features from all layers, thus reducing resources even further for variation estimation.
Looking Outside the Window: Wide-Context Transformer for the Semantic Segmentation of High-Resolution Remote Sensing Images
Jul 14, 2021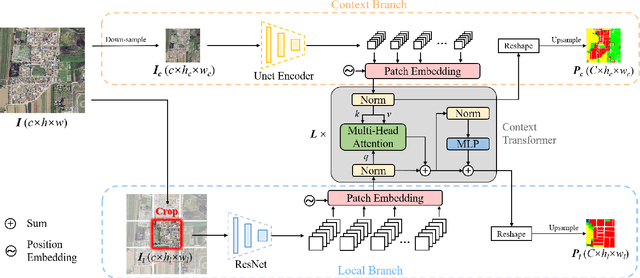
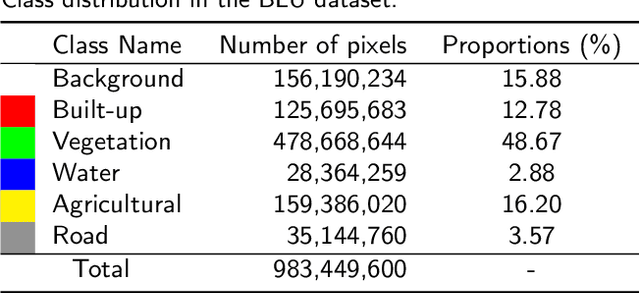
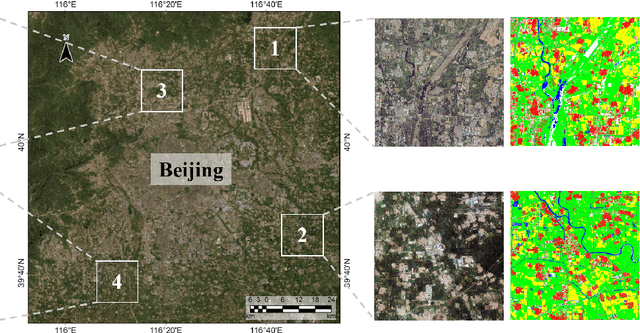
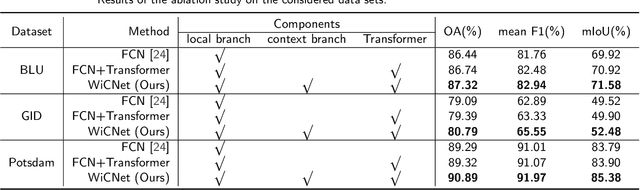
Long-range context information is crucial for the semantic segmentation of High-Resolution (HR) Remote Sensing Images (RSIs). The image cropping operations, commonly used for training neural networks, limit the perception of long-range context information in large RSIs. To break this limitation, we propose a Wide-Context Network (WiCoNet) for the semantic segmentation of HR RSIs. In the WiCoNet, apart from a conventional feature extraction network that aggregates the local information, an extra context branch is designed to explicitly model the spatial information in a larger image area. The information between the two branches is communicated through a Context Transformer, which is a novel design derived from the Vision Transformer to model the long-range context correlations. Ablation studies and comparative experiments conducted on several benchmark datasets prove the effectiveness of the proposed method. In addition, we present a new Beijing Land-Use (BLU) dataset. This is a large-scale HR satellite dataset provided with high-quality and fine-grained reference labels, which can boost future studies in this field.
MP-ResNet: Multi-path Residual Network for the Semantic segmentation of High-Resolution PolSAR Images
Nov 16, 2020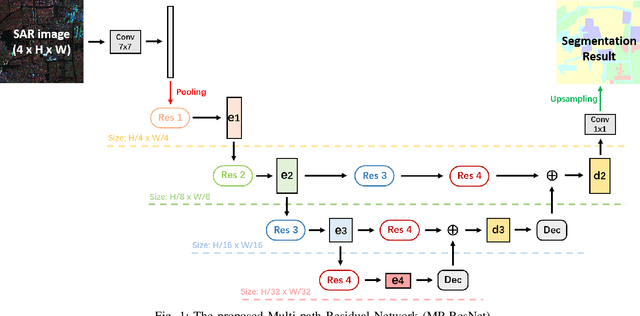
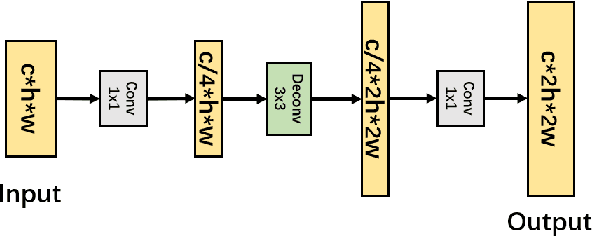
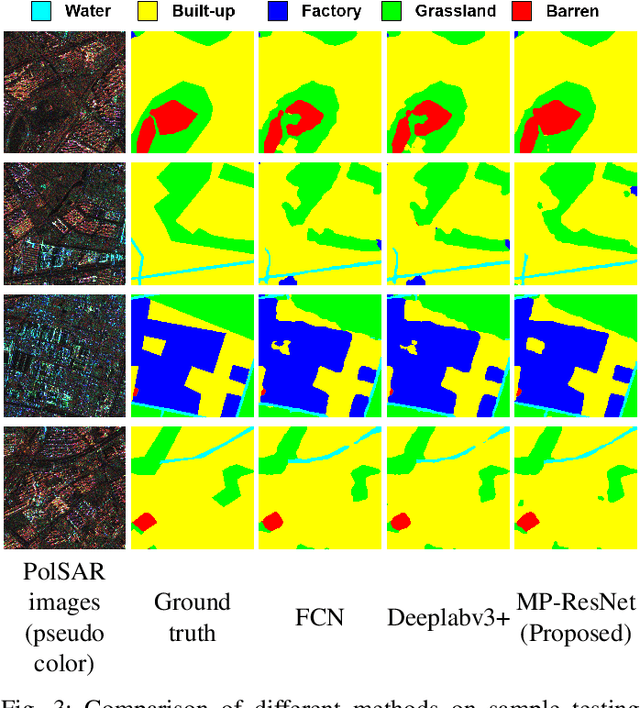
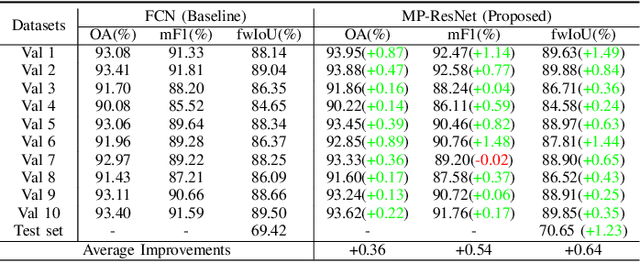
There are limited studies on the semantic segmentation of high-resolution Polarimetric Synthetic Aperture Radar (PolSAR) images due to the scarcity of training data and the inference of speckle noises. The Gaofen contest has provided open access of a high-quality PolSAR semantic segmentation dataset. Taking this chance, we propose a Multi-path ResNet (MP-ResNet) architecture for the semantic segmentation of high-resolution PolSAR images. Compared to conventional U-shape encoder-decoder convolutional neural network (CNN) architectures, the MP-ResNet learns semantic context with its parallel multi-scale branches, which greatly enlarges its valid receptive fields and improves the embedding of local discriminative features. In addition, MP-ResNet adopts a multi-level feature fusion design in its decoder to make the best use of the features learned from its different branches. Ablation studies show that the MPResNet has significant advantages over its baseline method (FCN with ResNet34). It also surpasses several classic state-of-the-art methods in terms of overall accuracy (OA), mean F1 and fwIoU, whereas its computational costs are not much increased. This CNN architecture can be used as a baseline method for future studies on the semantic segmentation of PolSAR images. The code is available at: https://github.com/ggsDing/SARSeg.
Smooth activations and reproducibility in deep networks
Oct 20, 2020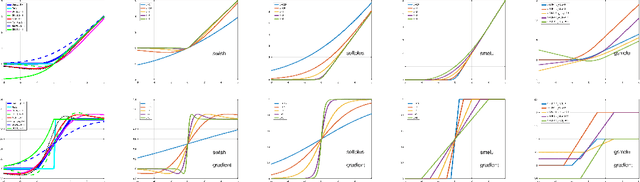
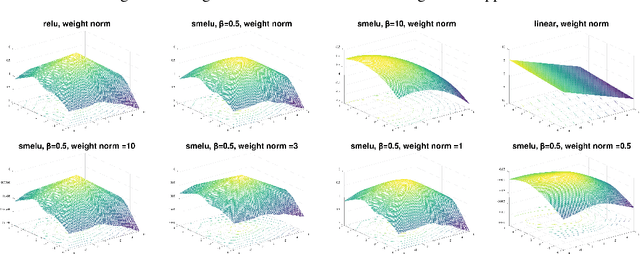
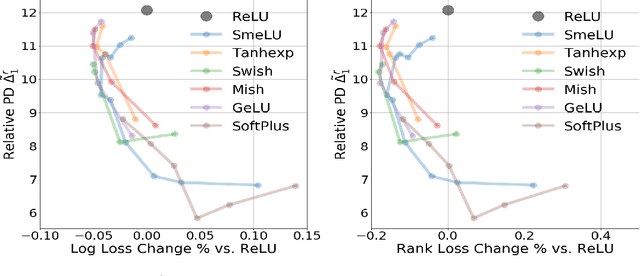
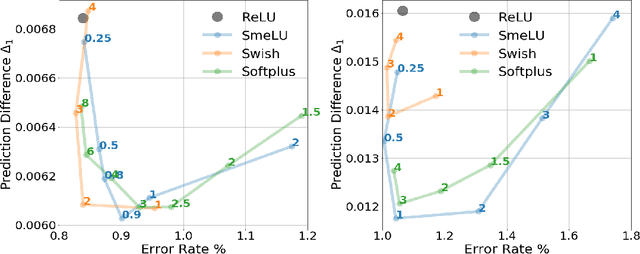
Deep networks are gradually penetrating almost every domain in our lives due to their amazing success. However, with substantive performance accuracy improvements comes the price of \emph{irreproducibility}. Two identical models, trained on the exact same training dataset may exhibit large differences in predictions on individual examples even when average accuracy is similar, especially when trained on highly distributed parallel systems. The popular Rectified Linear Unit (ReLU) activation has been key to recent success of deep networks. We demonstrate, however, that ReLU is also a catalyzer to irreproducibility in deep networks. We show that not only can activations smoother than ReLU provide better accuracy, but they can also provide better accuracy-reproducibility tradeoffs. We propose a new family of activations; Smooth ReLU (\emph{SmeLU}), designed to give such better tradeoffs, while also keeping the mathematical expression simple, and thus training speed fast and implementation cheap. SmeLU is monotonic, mimics ReLU, while providing continuous gradients, yielding better reproducibility. We generalize SmeLU to give even more flexibility and then demonstrate that SmeLU and its generalized form are special cases of a more general methodology of REctified Smooth Continuous Unit (RESCU) activations. Empirical results demonstrate the superior accuracy-reproducibility tradeoffs with smooth activations, SmeLU in particular.
DCN-M: Improved Deep & Cross Network for Feature Cross Learning in Web-scale Learning to Rank Systems
Aug 19, 2020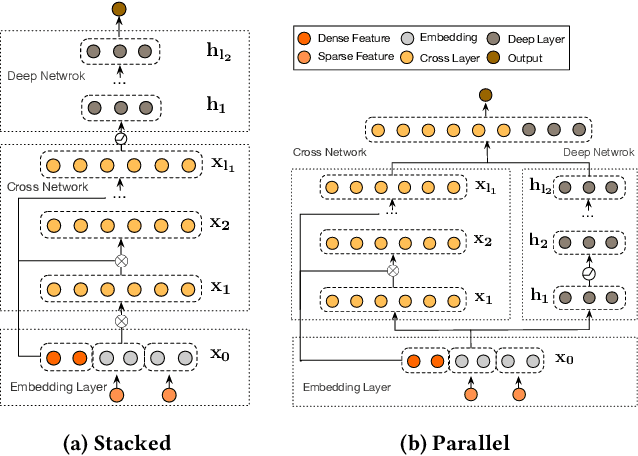
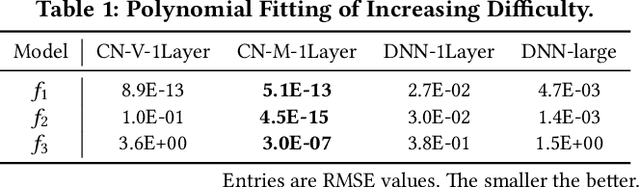
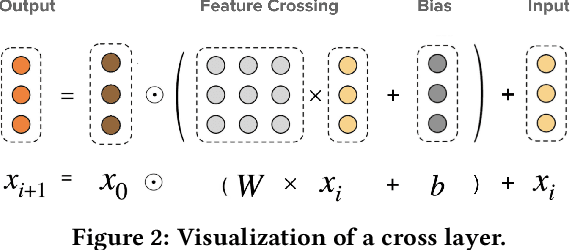

Learning effective feature crosses is the key behind building recommender systems. However, the sparse and large feature space requires exhaustive search to identify effective crosses. Deep & Cross Network (DCN) was proposed to automatically and efficiently learn bounded-degree predictive feature interactions. Unfortunately, in models that serve web-scale traffic with billions of training examples, DCN showed limited expressiveness in its cross network at learning more predictive feature interactions. Despite significant research progress made, many deep learning models in production still rely on traditional feed-forward neural networks to learn feature crosses inefficiently. In light of the pros/cons of DCN and existing feature interaction learning approaches, we propose an improved framework DCN-M to make DCN more practical in large-scale industrial settings. In a comprehensive experimental study with extensive hyper-parameter search and model tuning, we observed that DCN-M approaches outperform all the state-of-the-art algorithms on popular benchmark datasets. The improved DCN-M is more expressive yet remains cost efficient at feature interaction learning, especially when coupled with a mixture of low-rank architecture. DCN-M is simple, can be easily adopted as building blocks, and has delivered significant offline accuracy and online business metrics gains across many web-scale learning to rank systems.
Beyond Point Estimate: Inferring Ensemble Prediction Variation from Neuron Activation Strength in Recommender Systems
Aug 17, 2020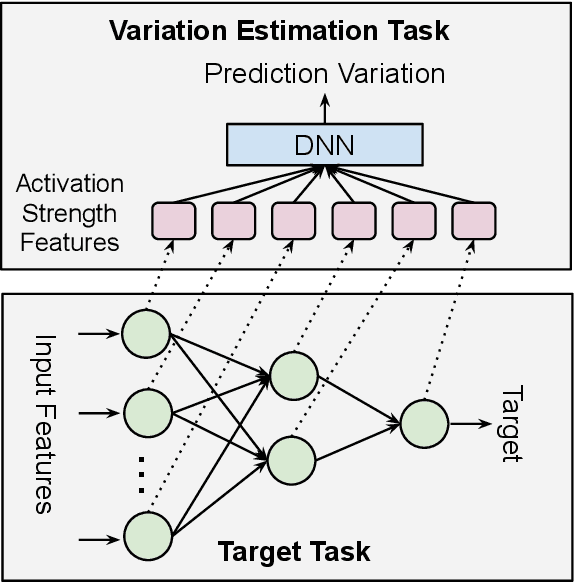
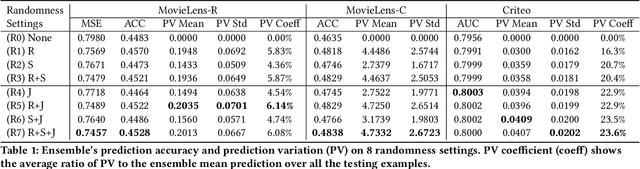
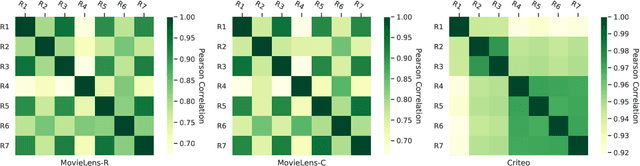
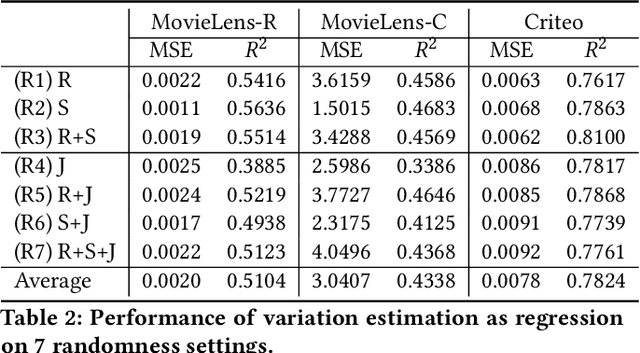
Despite deep neural network (DNN)'s impressive prediction performance in various domains, it is well known now that a set of DNN models trained with the same model specification and the same data can produce very different prediction results. Ensemble method is one state-of-the-art benchmark for prediction uncertainty estimation. However, ensembles are expensive to train and serve for web-scale traffic. In this paper, we seek to advance the understanding of prediction variation estimated by the ensemble method. Through empirical experiments on two widely used benchmark datasets MovieLens and Criteo in recommender systems, we observe that prediction variations come from various randomness sources, including training data shuffling, and parameter random initialization. By introducing more randomness into model training, we notice that ensemble's mean predictions tend to be more accurate while the prediction variations tend to be higher. Moreover, we propose to infer prediction variation from neuron activation strength and demonstrate the strong prediction power from activation strength features. Our experiment results show that the average R squared on MovieLens is as high as 0.56 and on Criteo is 0.81. Our method performs especially well when detecting the lowest and highest variation buckets, with 0.92 AUC and 0.89 AUC respectively. Our approach provides a simple way for prediction variation estimation, which opens up new opportunities for future work in many interesting areas (e.g.,model-based reinforcement learning) without relying on serving expensive ensemble models.