 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingLanMiDian: Systematic Evaluation of LLMs on TCM Knowledge and Clinical Reasoning
Feb 02, 2026Large language models (LLMs) are advancing rapidly in medical NLP, yet Traditional Chinese Medicine (TCM) with its distinctive ontology, terminology, and reasoning patterns requires domain-faithful evaluation. Existing TCM benchmarks are fragmented in coverage and scale and rely on non-unified or generation-heavy scoring that hinders fair comparison. We present the LingLanMiDian (LingLan) benchmark, a large-scale, expert-curated, multi-task suite that unifies evaluation across knowledge recall, multi-hop reasoning, information extraction, and real-world clinical decision-making. LingLan introduces a consistent metric design, a synonym-tolerant protocol for clinical labels, a per-dataset 400-item Hard subset, and a reframing of diagnosis and treatment recommendation into single-choice decision recognition. We conduct comprehensive, zero-shot evaluations on 14 leading open-source and proprietary LLMs, providing a unified perspective on their strengths and limitations in TCM commonsense knowledge understanding, reasoning, and clinical decision support; critically, the evaluation on Hard subset reveals a substantial gap between current models and human experts in TCM-specialized reasoning. By bridging fundamental knowledge and applied reasoning through standardized evaluation, LingLan establishes a unified, quantitative, and extensible foundation for advancing TCM LLMs and domain-specific medical AI research. All evaluation data and code are available at https://github.com/TCMAI-BJTU/LingLan and http://tcmnlp.com.
DK-Root: A Joint Data-and-Knowledge-Driven Framework for Root Cause Analysis of QoE Degradations in Mobile Networks
Nov 13, 2025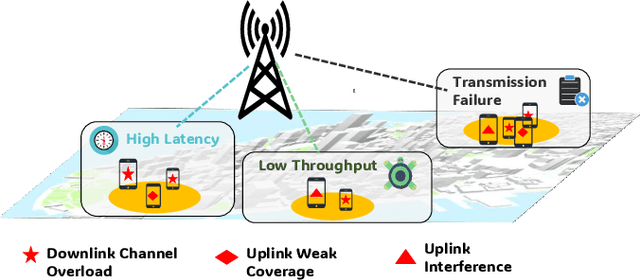
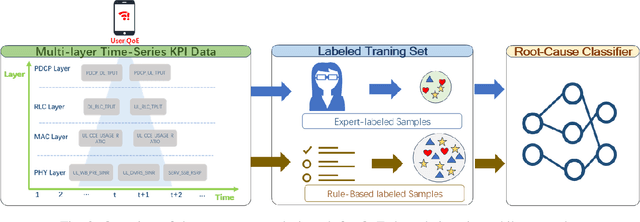
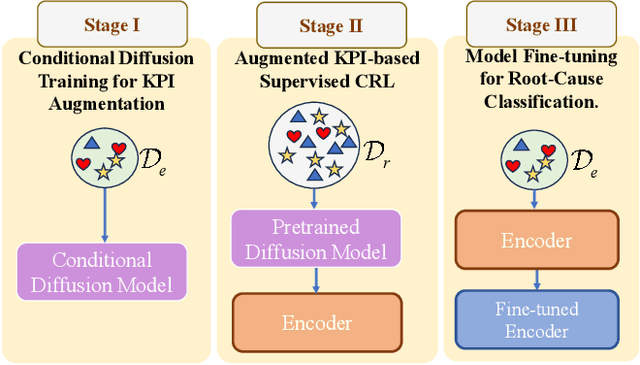
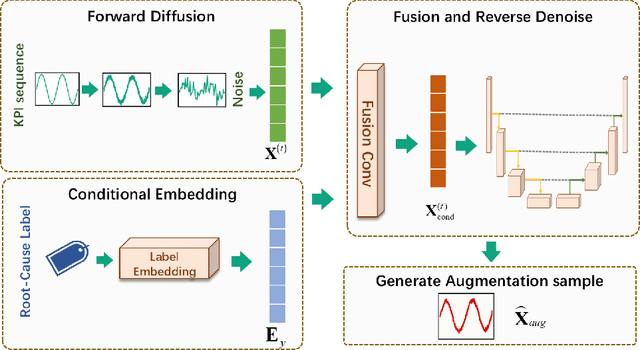
Diagnosing the root causes of Quality of Experience (QoE) degradations in operational mobile networks is challenging due to complex cross-layer interactions among kernel performance indicators (KPIs) and the scarcity of reliable expert annotations. Although rule-based heuristics can generate labels at scale, they are noisy and coarse-grained, limiting the accuracy of purely data-driven approaches. To address this, we propose DK-Root, a joint data-and-knowledge-driven framework that unifies scalable weak supervision with precise expert guidance for robust root-cause analysis. DK-Root first pretrains an encoder via contrastive representation learning using abundant rule-based labels while explicitly denoising their noise through a supervised contrastive objective. To supply task-faithful data augmentation, we introduce a class-conditional diffusion model that generates KPIs sequences preserving root-cause semantics, and by controlling reverse diffusion steps, it produces weak and strong augmentations that improve intra-class compactness and inter-class separability. Finally, the encoder and the lightweight classifier are jointly fine-tuned with scarce expert-verified labels to sharpen decision boundaries. Extensive experiments on a real-world, operator-grade dataset demonstrate state-of-the-art accuracy, with DK-Root surpassing traditional ML and recent semi-supervised time-series methods. Ablations confirm the necessity of the conditional diffusion augmentation and the pretrain-finetune design, validating both representation quality and classification gains.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025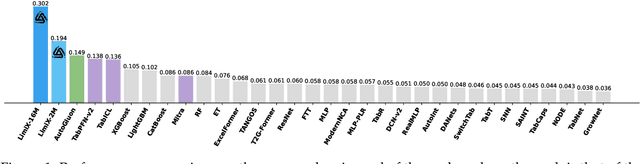
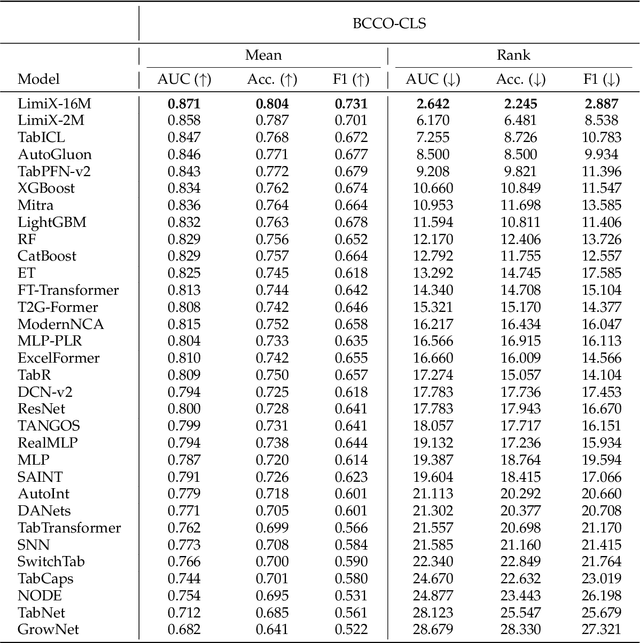
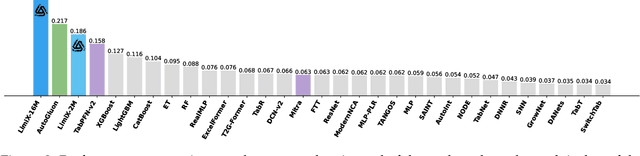
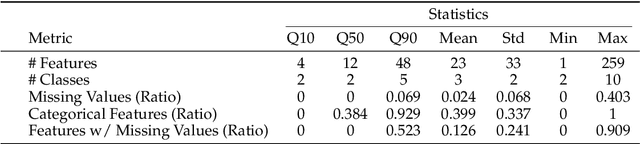
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
COUNTS: Benchmarking Object Detectors and Multimodal Large Language Models under Distribution Shifts
Apr 14, 2025Current object detectors often suffer significant perfor-mance degradation in real-world applications when encountering distributional shifts. Consequently, the out-of-distribution (OOD) generalization capability of object detectors has garnered increasing attention from researchers. Despite this growing interest, there remains a lack of a large-scale, comprehensive dataset and evaluation benchmark with fine-grained annotations tailored to assess the OOD generalization on more intricate tasks like object detection and grounding. To address this gap, we introduce COUNTS, a large-scale OOD dataset with object-level annotations. COUNTS encompasses 14 natural distributional shifts, over 222K samples, and more than 1,196K labeled bounding boxes. Leveraging COUNTS, we introduce two novel benchmarks: O(OD)2 and OODG. O(OD)2 is designed to comprehensively evaluate the OOD generalization capabilities of object detectors by utilizing controlled distribution shifts between training and testing data. OODG, on the other hand, aims to assess the OOD generalization of grounding abilities in multimodal large language models (MLLMs). Our findings reveal that, while large models and extensive pre-training data substantially en hance performance in in-distribution (IID) scenarios, significant limitations and opportunities for improvement persist in OOD contexts for both object detectors and MLLMs. In visual grounding tasks, even the advanced GPT-4o and Gemini-1.5 only achieve 56.7% and 28.0% accuracy, respectively. We hope COUNTS facilitates advancements in the development and assessment of robust object detectors and MLLMs capable of maintaining high performance under distributional shifts.
Understanding the Generalization of In-Context Learning in Transformers: An Empirical Study
Mar 19, 2025Large language models (LLMs) like GPT-4 and LLaMA-3 utilize the powerful in-context learning (ICL) capability of Transformer architecture to learn on the fly from limited examples. While ICL underpins many LLM applications, its full potential remains hindered by a limited understanding of its generalization boundaries and vulnerabilities. We present a systematic investigation of transformers' generalization capability with ICL relative to training data coverage by defining a task-centric framework along three dimensions: inter-problem, intra-problem, and intra-task generalization. Through extensive simulation and real-world experiments, encompassing tasks such as function fitting, API calling, and translation, we find that transformers lack inter-problem generalization with ICL, but excel in intra-task and intra-problem generalization. When the training data includes a greater variety of mixed tasks, it significantly enhances the generalization ability of ICL on unseen tasks and even on known simple tasks. This guides us in designing training data to maximize the diversity of tasks covered and to combine different tasks whenever possible, rather than solely focusing on the target task for testing.
RMG: Real-Time Expressive Motion Generation with Self-collision Avoidance for 6-DOF Companion Robotic Arms
Mar 13, 2025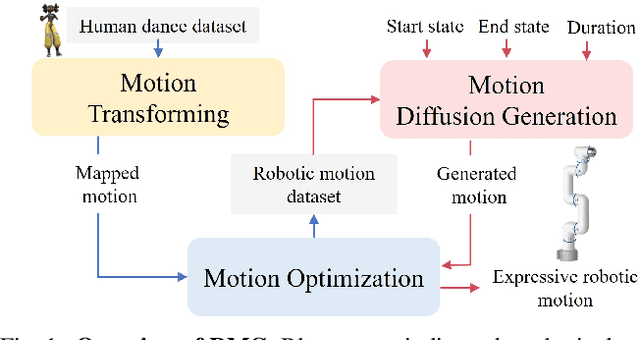
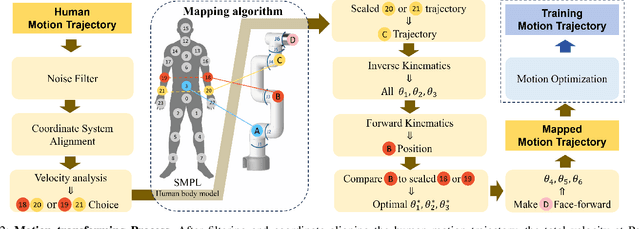
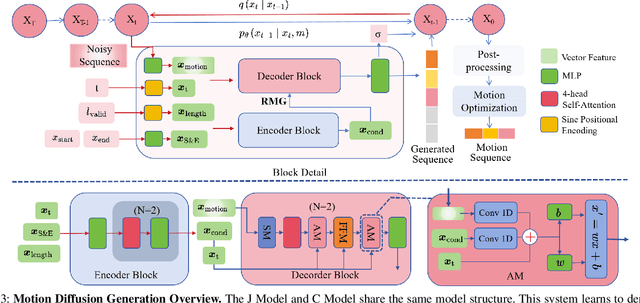
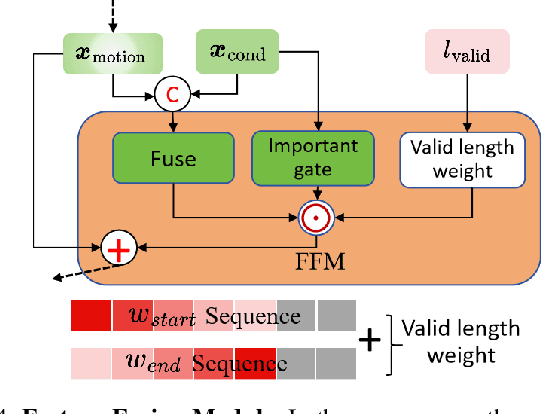
The six-degree-of-freedom (6-DOF) robotic arm has gained widespread application in human-coexisting environments. While previous research has predominantly focused on functional motion generation, the critical aspect of expressive motion in human-robot interaction remains largely unexplored. This paper presents a novel real-time motion generation planner that enhances interactivity by creating expressive robotic motions between arbitrary start and end states within predefined time constraints. Our approach involves three key contributions: first, we develop a mapping algorithm to construct an expressive motion dataset derived from human dance movements; second, we train motion generation models in both Cartesian and joint spaces using this dataset; third, we introduce an optimization algorithm that guarantees smooth, collision-free motion while maintaining the intended expressive style. Experimental results demonstrate the effectiveness of our method, which can generate expressive and generalized motions in under 0.5 seconds while satisfying all specified constraints.
On the Out-Of-Distribution Generalization of Multimodal Large Language Models
Feb 09, 2024We investigate the generalization boundaries of current Multimodal Large Language Models (MLLMs) via comprehensive evaluation under out-of-distribution scenarios and domain-specific tasks. We evaluate their zero-shot generalization across synthetic images, real-world distributional shifts, and specialized datasets like medical and molecular imagery. Empirical results indicate that MLLMs struggle with generalization beyond common training domains, limiting their direct application without adaptation. To understand the cause of unreliable performance, we analyze three hypotheses: semantic misinterpretation, visual feature extraction insufficiency, and mapping deficiency. Results identify mapping deficiency as the primary hurdle. To address this problem, we show that in-context learning (ICL) can significantly enhance MLLMs' generalization, opening new avenues for overcoming generalization barriers. We further explore the robustness of ICL under distribution shifts and show its vulnerability to domain shifts, label shifts, and spurious correlation shifts between in-context examples and test data.
Embedding in Recommender Systems: A Survey
Oct 28, 2023Recommender systems have become an essential component of many online platforms, providing personalized recommendations to users. A crucial aspect is embedding techniques that coverts the high-dimensional discrete features, such as user and item IDs, into low-dimensional continuous vectors and can enhance the recommendation performance. Applying embedding techniques captures complex entity relationships and has spurred substantial research. In this survey, we provide an overview of the recent literature on embedding techniques in recommender systems. This survey covers embedding methods like collaborative filtering, self-supervised learning, and graph-based techniques. Collaborative filtering generates embeddings capturing user-item preferences, excelling in sparse data. Self-supervised methods leverage contrastive or generative learning for various tasks. Graph-based techniques like node2vec exploit complex relationships in network-rich environments. Addressing the scalability challenges inherent to embedding methods, our survey delves into innovative directions within the field of recommendation systems. These directions aim to enhance performance and reduce computational complexity, paving the way for improved recommender systems. Among these innovative approaches, we will introduce Auto Machine Learning (AutoML), hash techniques, and quantization techniques in this survey. We discuss various architectures and techniques and highlight the challenges and future directions in these aspects. This survey aims to provide a comprehensive overview of the state-of-the-art in this rapidly evolving field and serve as a useful resource for researchers and practitioners working in the area of recommender systems.
MP-ResNet: Multi-path Residual Network for the Semantic segmentation of High-Resolution PolSAR Images
Nov 16, 2020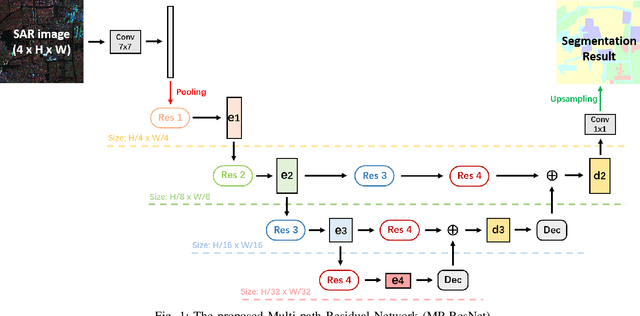
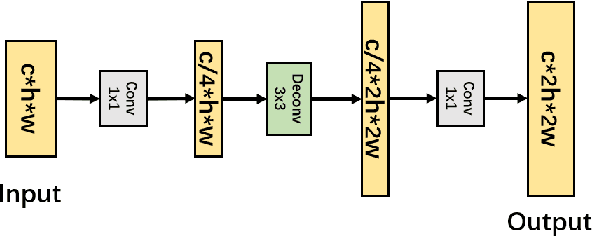
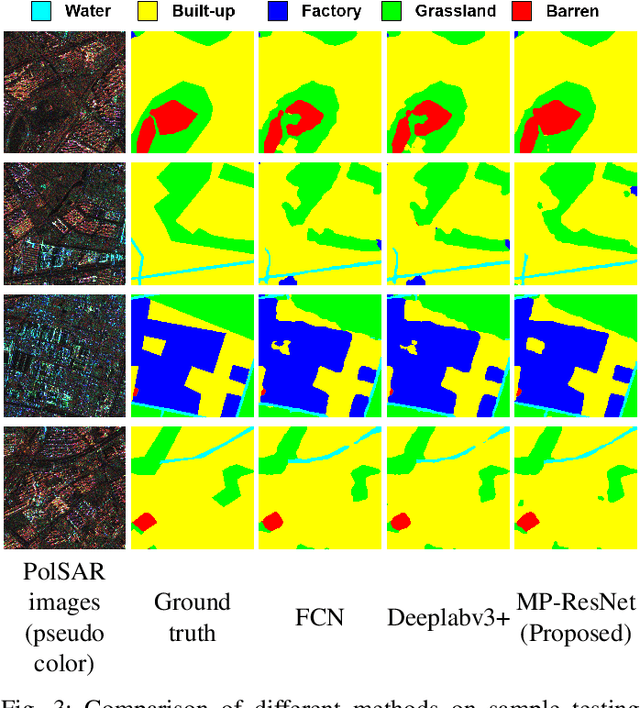
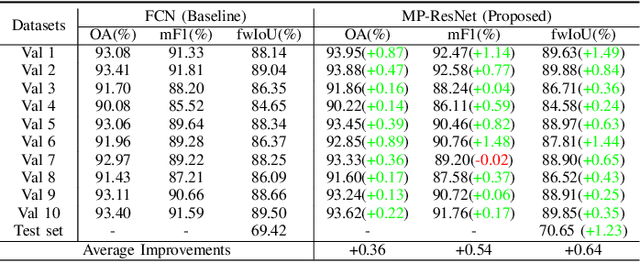
There are limited studies on the semantic segmentation of high-resolution Polarimetric Synthetic Aperture Radar (PolSAR) images due to the scarcity of training data and the inference of speckle noises. The Gaofen contest has provided open access of a high-quality PolSAR semantic segmentation dataset. Taking this chance, we propose a Multi-path ResNet (MP-ResNet) architecture for the semantic segmentation of high-resolution PolSAR images. Compared to conventional U-shape encoder-decoder convolutional neural network (CNN) architectures, the MP-ResNet learns semantic context with its parallel multi-scale branches, which greatly enlarges its valid receptive fields and improves the embedding of local discriminative features. In addition, MP-ResNet adopts a multi-level feature fusion design in its decoder to make the best use of the features learned from its different branches. Ablation studies show that the MPResNet has significant advantages over its baseline method (FCN with ResNet34). It also surpasses several classic state-of-the-art methods in terms of overall accuracy (OA), mean F1 and fwIoU, whereas its computational costs are not much increased. This CNN architecture can be used as a baseline method for future studies on the semantic segmentation of PolSAR images. The code is available at: https://github.com/ggsDing/SARSeg.