 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRL-Bench: Standardizing Cross-Paradigm Representation-Level Evaluation of Tabular Encoders
Jun 08, 2026Tabular encoders are usually evaluated inside task-specific end-to-end pipelines, so models from different training paradigms are difficult to compare directly even when they operate on similar tabular signals. We introduce TRL-Bench, a multi-granular tabular representation learning (TRL) benchmark that standardizes cross-paradigm representation-level evaluation: each encoder exports row-, column-, or table embeddings through its supported wrapper, and shared lightweight heads probe them across three suites: TRL-CTbench (column/table), TRL-Rbench (row), and TRL-DLTE (compositional Data-Lake Table Enrichment spanning all three granularities). To support this standardized setting, we release curated benchmark assets and task reformulations, including 50 OpenML tables with 123 verified targets, 16 row-pair linkage rewrites, and a 47,772-table DLTE lake derived from 1,379 parent tables. Across 20 models and 16 tasks, TRL-Bench shows that once downstream conditions are standardized, encoder quality is capability-specific rather than captured by a single leaderboard. In TRL-CTbench, generic text encoders often lead on tasks with strong surface-text signal, while tabular specialists win where their pretraining objective aligns with the task. In TRL-Rbench, within-table prediction and cross-table linkage favor different training regimes, with atomic linkage performance correlating strongly with the row-matching stage of DLTE pipelines. In TRL-DLTE, the strongest pipelines combine capability-matched specialists rather than reuse a single encoder, and top end-to-end quality depends on non-additive compositional fit rather than per-stage marginal rank alone. TRL-Bench provides a common protocol for measuring reusable signal in exported tabular representations under shared downstream conditions. Code and data: https://github.com/LOGO-CUHKSZ/TRL-Bench
Towards Human-Like Interactive Speech Recognition With Agentic Correction and Semantic Evaluation
May 28, 2026Automatic speech recognition (ASR) is a core component of human--computer interaction and an increasingly important front-end for LLM-based assistants and agents. However, most current ASR systems still follow a single-pass paradigm, which is poorly aligned with human communication, where misunderstandings are resolved through iterative clarification and refinement. This mismatch makes it difficult to correct meaning-critical errors once they occur. Meanwhile, token-level metrics such as WER or CER cannot adequately reflect such a problem. To address these limitations, we formulate \emph{Interactive ASR} as a multi-turn refinement task and propose \textbf{Agentic ASR}, a closed-loop framework that combines a single-pass ASR front-end with semantic correction, intent routing, and reasoning-based editing. We further introduce the \textbf{Sentence-level Semantic Error Rate} ($S^2ER$), an LLM-based semantic evaluation metric, together with an \textbf{Interactive Simulation System} for scalable and reproducible benchmarking. Experiments on multilingual, named-entity-intensive, and code-switching benchmarks show that iterative interaction consistently reduces semantic errors, with much larger gains in $S^2ER$ than in conventional token-level metrics. Human--AI alignment and ablation studies further validate the reliability of the semantic judge and the robustness of the proposed framework. The code is available at: https://interactiveasr.github.io/ and the live demo is available at https://i-asr.sjtuxlance.com/
FORGE:Fine-grained Multimodal Evaluation for Manufacturing Scenarios
Apr 08, 2026The manufacturing sector is increasingly adopting Multimodal Large Language Models (MLLMs) to transition from simple perception to autonomous execution, yet current evaluations fail to reflect the rigorous demands of real-world manufacturing environments. Progress is hindered by data scarcity and a lack of fine-grained domain semantics in existing datasets. To bridge this gap, we introduce FORGE. Wefirst construct a high-quality multimodal dataset that combines real-world 2D images and 3D point clouds, annotated with fine-grained domain semantics (e.g., exact model numbers). We then evaluate 18 state-of-the-art MLLMs across three manufacturing tasks, namely workpiece verification, structural surface inspection, and assembly verification, revealing significant performance gaps. Counter to conventional understanding, the bottleneck analysis shows that visual grounding is not the primary limiting factor. Instead, insufficient domain-specific knowledge is the key bottleneck, setting a clear direction for future research. Beyond evaluation, we show that our structured annotations can serve as an actionable training resource: supervised fine-tuning of a compact 3B-parameter model on our data yields up to 90.8% relative improvement in accuracy on held-out manufacturing scenarios, providing preliminary evidence for a practical pathway toward domain-adapted manufacturing MLLMs. The code and datasets are available at https://ai4manufacturing.github.io/forge-web.
HT-GNN: Hyper-Temporal Graph Neural Network for Customer Lifetime Value Prediction in Baidu Ads
Jan 19, 2026Lifetime value (LTV) prediction is crucial for news feed advertising, enabling platforms to optimize bidding and budget allocation for long-term revenue growth. However, it faces two major challenges: (1) demographic-based targeting creates segment-specific LTV distributions with large value variations across user groups; and (2) dynamic marketing strategies generate irregular behavioral sequences where engagement patterns evolve rapidly. We propose a Hyper-Temporal Graph Neural Network (HT-GNN), which jointly models demographic heterogeneity and temporal dynamics through three key components: (i) a hypergraph-supervised module capturing inter-segment relationships; (ii) a transformer-based temporal encoder with adaptive weighting; and (iii) a task-adaptive mixture-of-experts with dynamic prediction towers for multi-horizon LTV forecasting. Experiments on \textit{Baidu Ads} with 15 million users demonstrate that HT-GNN consistently outperforms state-of-the-art methods across all metrics and prediction horizons.
GraphOmni: A Comprehensive and Extendable Benchmark Framework for Large Language Models on Graph-theoretic Tasks
Apr 17, 2025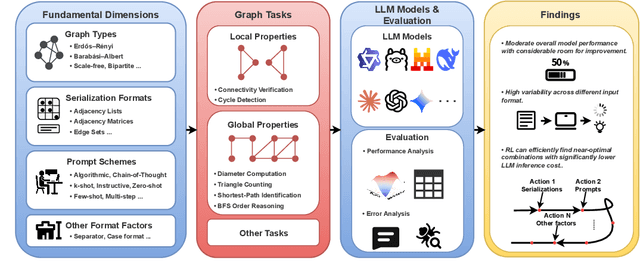

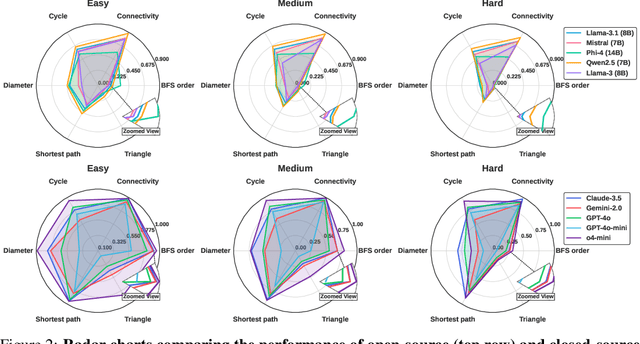
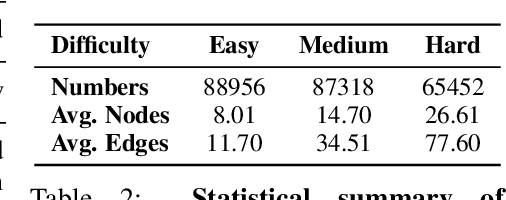
In this paper, we presented GraphOmni, a comprehensive benchmark framework for systematically evaluating the graph reasoning capabilities of LLMs. By analyzing critical dimensions, including graph types, serialization formats, and prompt schemes, we provided extensive insights into the strengths and limitations of current LLMs. Our empirical findings emphasize that no single serialization or prompting strategy consistently outperforms others. Motivated by these insights, we propose a reinforcement learning-based approach that dynamically selects the best serialization-prompt pairings, resulting in significant accuracy improvements. GraphOmni's modular and extensible design establishes a robust foundation for future research, facilitating advancements toward general-purpose graph reasoning models.
Enhancing Graph Self-Supervised Learning with Graph Interplay
Oct 08, 2024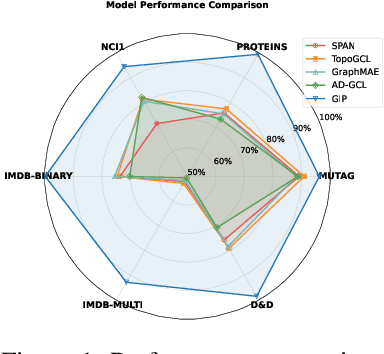
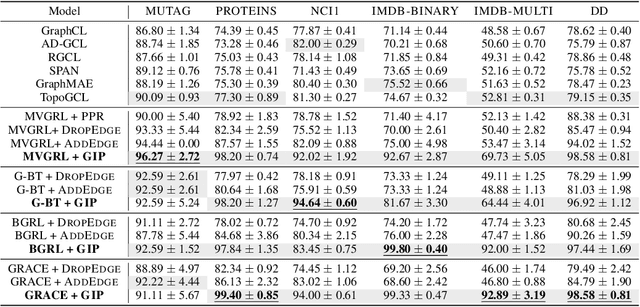
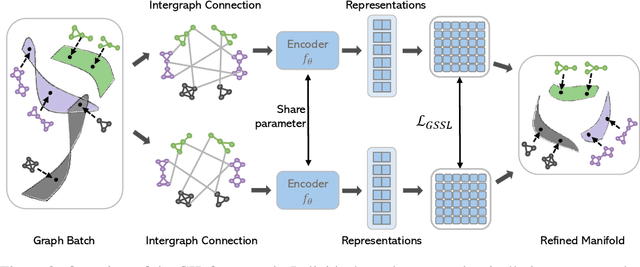
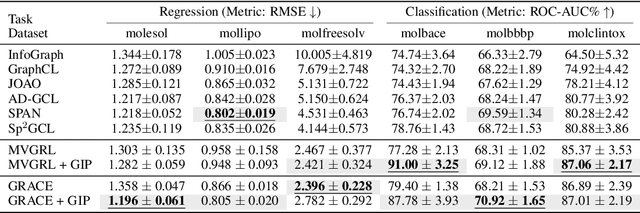
Graph self-supervised learning (GSSL) has emerged as a compelling framework for extracting informative representations from graph-structured data without extensive reliance on labeled inputs. In this study, we introduce Graph Interplay (GIP), an innovative and versatile approach that significantly enhances the performance equipped with various existing GSSL methods. To this end, GIP advocates direct graph-level communications by introducing random inter-graph edges within standard batches. Against GIP's simplicity, we further theoretically show that \textsc{GIP} essentially performs a principled manifold separation via combining inter-graph message passing and GSSL, bringing about more structured embedding manifolds and thus benefits a series of downstream tasks. Our empirical study demonstrates that GIP surpasses the performance of prevailing GSSL methods across multiple benchmarks by significant margins, highlighting its potential as a breakthrough approach. Besides, GIP can be readily integrated into a series of GSSL methods and consistently offers additional performance gain. This advancement not only amplifies the capability of GSSL but also potentially sets the stage for a novel graph learning paradigm in a broader sense.
Do spectral cues matter in contrast-based graph self-supervised learning?
May 30, 2024

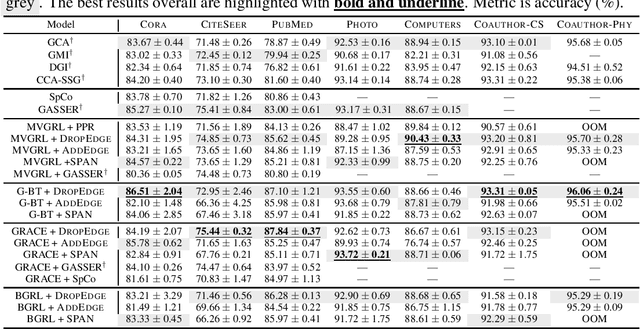
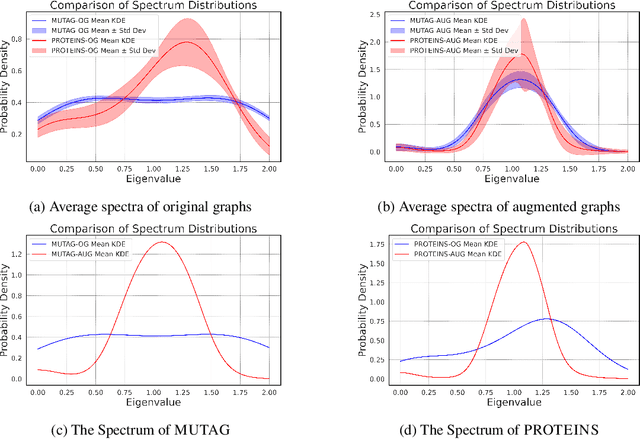
The recent surge in contrast-based graph self-supervised learning has prominently featured an intensified exploration of spectral cues. However, an intriguing paradox emerges, as methods grounded in seemingly conflicting assumptions or heuristic approaches regarding the spectral domain demonstrate notable enhancements in learning performance. This paradox prompts a critical inquiry into the genuine contribution of spectral information to contrast-based graph self-supervised learning. This study undertakes an extensive investigation into this inquiry, conducting a thorough study of the relationship between spectral characteristics and the learning outcomes of contemporary methodologies. Based on this analysis, we claim that the effectiveness and significance of spectral information need to be questioned. Instead, we revisit simple edge perturbation: random edge dropping designed for node-level self-supervised learning and random edge adding intended for graph-level self-supervised learning. Compelling evidence is presented that these simple yet effective strategies consistently yield superior performance while demanding significantly fewer computational resources compared to all prior spectral augmentation methods. The proposed insights represent a significant leap forward in the field, potentially reshaping the understanding and implementation of graph self-supervised learning.
Boosting Protein Language Models with Negative Sample Mining
May 28, 2024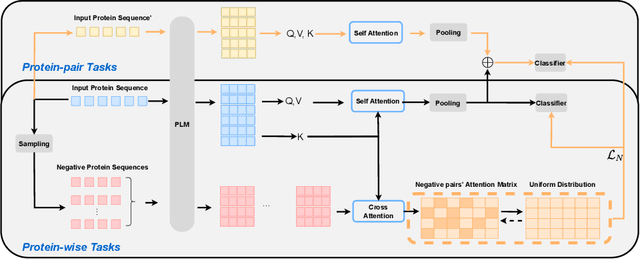
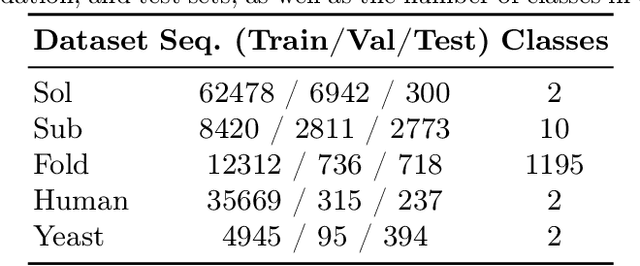
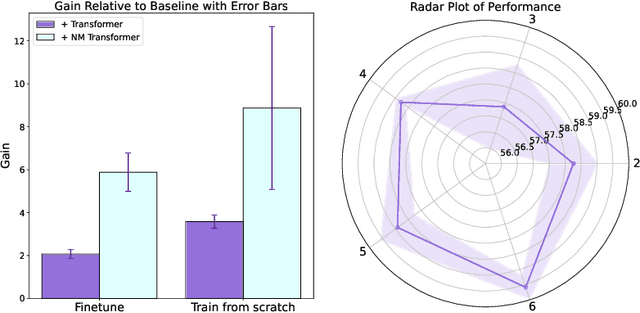
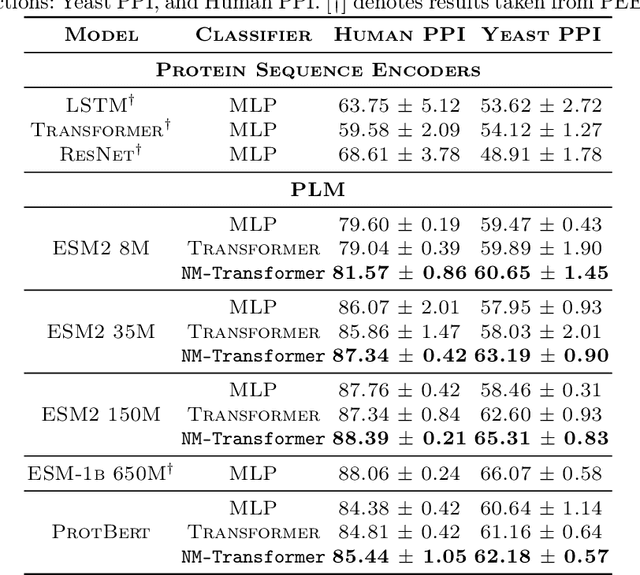
We introduce a pioneering methodology for boosting large language models in the domain of protein representation learning. Our primary contribution lies in the refinement process for correlating the over-reliance on co-evolution knowledge, in a way that networks are trained to distill invaluable insights from negative samples, constituted by protein pairs sourced from disparate categories. By capitalizing on this novel approach, our technique steers the training of transformer-based models within the attention score space. This advanced strategy not only amplifies performance but also reflects the nuanced biological behaviors exhibited by proteins, offering aligned evidence with traditional biological mechanisms such as protein-protein interaction. We experimentally observed improved performance on various tasks over datasets, on top of several well-established large protein models. This innovative paradigm opens up promising horizons for further progress in the realms of protein research and computational biology.
Boosting Graph Pooling with Persistent Homology
Feb 26, 2024



Recently, there has been an emerging trend to integrate persistent homology (PH) into graph neural networks (GNNs) to enrich expressive power. However, naively plugging PH features into GNN layers always results in marginal improvement with low interpretability. In this paper, we investigate a novel mechanism for injecting global topological invariance into pooling layers using PH, motivated by the observation that filtration operation in PH naturally aligns graph pooling in a cut-off manner. In this fashion, message passing in the coarsened graph acts along persistent pooled topology, leading to improved performance. Experimentally, we apply our mechanism to a collection of graph pooling methods and observe consistent and substantial performance gain over several popular datasets, demonstrating its wide applicability and flexibility.
Graph Learning with Distributional Edge Layouts
Feb 26, 2024



Graph Neural Networks (GNNs) learn from graph-structured data by passing local messages between neighboring nodes along edges on certain topological layouts. Typically, these topological layouts in modern GNNs are deterministically computed (e.g., attention-based GNNs) or locally sampled (e.g., GraphSage) under heuristic assumptions. In this paper, we for the first time pose that these layouts can be globally sampled via Langevin dynamics following Boltzmann distribution equipped with explicit physical energy, leading to higher feasibility in the physical world. We argue that such a collection of sampled/optimized layouts can capture the wide energy distribution and bring extra expressivity on top of WL-test, therefore easing downstream tasks. As such, we propose Distributional Edge Layouts (DELs) to serve as a complement to a variety of GNNs. DEL is a pre-processing strategy independent of subsequent GNN variants, thus being highly flexible. Experimental results demonstrate that DELs consistently and substantially improve a series of GNN baselines, achieving state-of-the-art performance on multiple datasets.