 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRICT: Stress Test of Rendering Images Containing Text
May 25, 2025While diffusion models have revolutionized text-to-image generation with their ability to synthesize realistic and diverse scenes, they continue to struggle to generate consistent and legible text within images. This shortcoming is commonly attributed to the locality bias inherent in diffusion-based generation, which limits their ability to model long-range spatial dependencies. In this paper, we introduce $\textbf{STRICT}$, a benchmark designed to systematically stress-test the ability of diffusion models to render coherent and instruction-aligned text in images. Our benchmark evaluates models across multiple dimensions: (1) the maximum length of readable text that can be generated; (2) the correctness and legibility of the generated text, and (3) the ratio of not following instructions for generating text. We evaluate several state-of-the-art models, including proprietary and open-source variants, and reveal persistent limitations in long-range consistency and instruction-following capabilities. Our findings provide insights into architectural bottlenecks and motivate future research directions in multimodal generative modeling. We release our entire evaluation pipeline at https://github.com/tianyu-z/STRICT-Bench.
System-1.5 Reasoning: Traversal in Language and Latent Spaces with Dynamic Shortcuts
May 25, 2025Chain-of-thought (CoT) reasoning enables large language models (LLMs) to move beyond fast System-1 responses and engage in deliberative System-2 reasoning. However, this comes at the cost of significant inefficiency due to verbose intermediate output. Recent latent-space reasoning methods improve efficiency by operating on hidden states without decoding into language, yet they treat all steps uniformly, failing to distinguish critical deductions from auxiliary steps and resulting in suboptimal use of computational resources. In this paper, we propose System-1.5 Reasoning, an adaptive reasoning framework that dynamically allocates computation across reasoning steps through shortcut paths in latent space.Specifically, System-1.5 Reasoning introduces two types of dynamic shortcuts. The model depth shortcut (DS) adaptively reasons along the vertical depth by early exiting non-critical tokens through lightweight adapter branches, while allowing critical tokens to continue through deeper Transformer layers. The step shortcut (SS) reuses hidden states across the decoding steps to skip trivial steps and reason horizontally in latent space. Training System-1.5 Reasoning involves a two-stage self-distillation process: first distilling natural language CoT into latent-space continuous thought, and then distilling full-path System-2 latent reasoning into adaptive shortcut paths (System-1.5 Reasoning).Experiments on reasoning tasks demonstrate the superior performance of our method. For example, on GSM8K, System-1.5 Reasoning achieves reasoning performance comparable to traditional CoT fine-tuning methods while accelerating inference by over 20x and reducing token generation by 92.31% on average.
FinSage: A Multi-aspect RAG System for Financial Filings Question Answering
Apr 20, 2025Leveraging large language models in real-world settings often entails a need to utilize domain-specific data and tools in order to follow the complex regulations that need to be followed for acceptable use. Within financial sectors, modern enterprises increasingly rely on Retrieval-Augmented Generation (RAG) systems to address complex compliance requirements in financial document workflows. However, existing solutions struggle to account for the inherent heterogeneity of data (e.g., text, tables, diagrams) and evolving nature of regulatory standards used in financial filings, leading to compromised accuracy in critical information extraction. We propose the FinSage framework as a solution, utilizing a multi-aspect RAG framework tailored for regulatory compliance analysis in multi-modal financial documents. FinSage introduces three innovative components: (1) a multi-modal pre-processing pipeline that unifies diverse data formats and generates chunk-level metadata summaries, (2) a multi-path sparse-dense retrieval system augmented with query expansion (HyDE) and metadata-aware semantic search, and (3) a domain-specialized re-ranking module fine-tuned via Direct Preference Optimization (DPO) to prioritize compliance-critical content. Extensive experiments demonstrate that FinSage achieves an impressive recall of 92.51% on 75 expert-curated questions derived from surpasses the best baseline method on the FinanceBench question answering datasets by 24.06% in accuracy. Moreover, FinSage has been successfully deployed as financial question-answering agent in online meetings, where it has already served more than 1,200 people.
GraphOmni: A Comprehensive and Extendable Benchmark Framework for Large Language Models on Graph-theoretic Tasks
Apr 17, 2025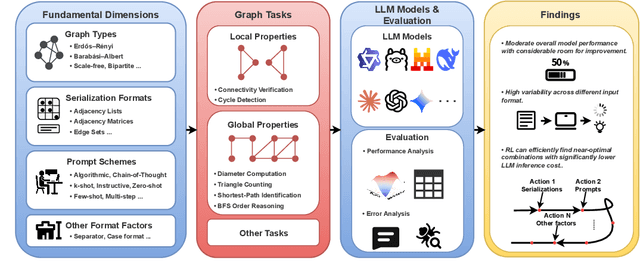

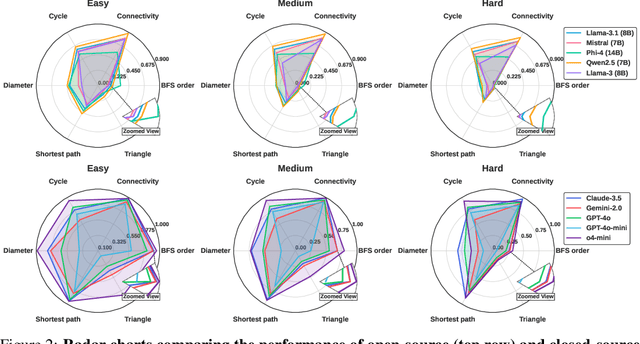
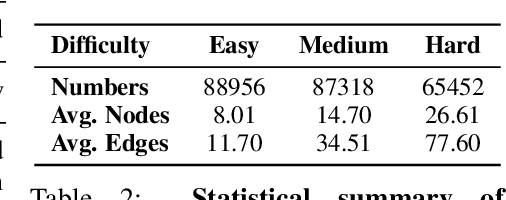
In this paper, we presented GraphOmni, a comprehensive benchmark framework for systematically evaluating the graph reasoning capabilities of LLMs. By analyzing critical dimensions, including graph types, serialization formats, and prompt schemes, we provided extensive insights into the strengths and limitations of current LLMs. Our empirical findings emphasize that no single serialization or prompting strategy consistently outperforms others. Motivated by these insights, we propose a reinforcement learning-based approach that dynamically selects the best serialization-prompt pairings, resulting in significant accuracy improvements. GraphOmni's modular and extensible design establishes a robust foundation for future research, facilitating advancements toward general-purpose graph reasoning models.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
R$^3$Mem: Bridging Memory Retention and Retrieval via Reversible Compression
Feb 21, 2025Memory plays a key role in enhancing LLMs' performance when deployed to real-world applications. Existing solutions face trade-offs: explicit memory designs based on external storage require complex management and incur storage overhead, while implicit memory designs that store information via parameters struggle with reliable retrieval. In this paper, we propose R$^3$Mem, a memory network that optimizes both information Retention and Retrieval through Reversible context compression. Specifically, R$^3$Mem employs virtual memory tokens to compress and encode infinitely long histories, further enhanced by a hierarchical compression strategy that refines information from document- to entity-level for improved assimilation across granularities. For retrieval, R$^3$Mem employs a reversible architecture, reconstructing raw data by invoking the model backward with compressed information. Implemented via parameter-efficient fine-tuning, it can integrate seamlessly with any Transformer-based model. Experiments demonstrate that our memory design achieves state-of-the-art performance in long-context language modeling and retrieval-augmented generation tasks. It also significantly outperforms conventional memory modules in long-horizon interaction tasks like conversational agents, showcasing its potential for next-generation retrieval systems.
AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
Feb 03, 2025



Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), often produce out-of-distribution or noisy inputs, leading to misalignment between the modalities. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where scanned document images must be accurately mapped to their textual content. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods. We provide further analysis demonstrating improved vision-text feature alignment and robustness to noise.
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
FACT: Examining the Effectiveness of Iterative Context Rewriting for Multi-fact Retrieval
Oct 28, 2024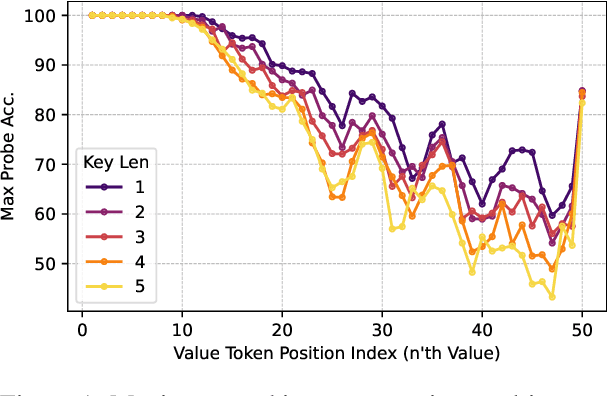
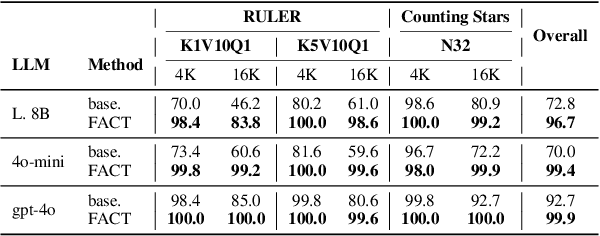
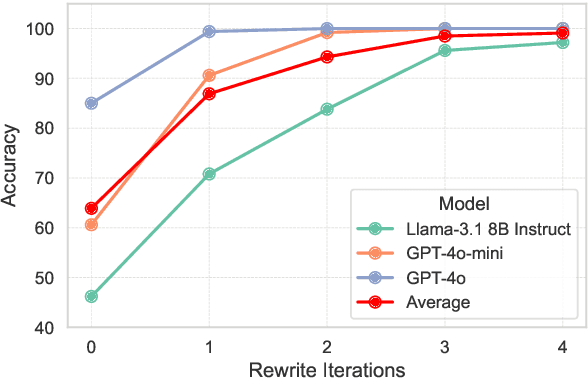
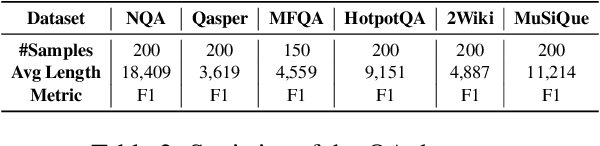
Large Language Models (LLMs) are proficient at retrieving single facts from extended contexts, yet they struggle with tasks requiring the simultaneous retrieval of multiple facts, especially during generation. This paper identifies a novel "lost-in-the-middle" phenomenon, where LLMs progressively lose track of critical information throughout the generation process, resulting in incomplete or inaccurate retrieval. To address this challenge, we introduce Find All Crucial Texts (FACT), an iterative retrieval method that refines context through successive rounds of rewriting. This approach enables models to capture essential facts incrementally, which are often overlooked in single-pass retrieval. Experiments demonstrate that FACT substantially enhances multi-fact retrieval performance across various tasks, though improvements are less notable in general-purpose QA scenarios. Our findings shed light on the limitations of LLMs in multi-fact retrieval and underscore the need for more resilient long-context retrieval strategies.
LongRecipe: Recipe for Efficient Long Context Generalization in Large Language Models
Sep 04, 2024Large language models (LLMs) face significant challenges in handling long-context tasks because of their limited effective context window size during pretraining, which restricts their ability to generalize over extended sequences. Meanwhile, extending the context window in LLMs through post-pretraining is highly resource-intensive. To address this, we introduce LongRecipe, an efficient training strategy for extending the context window of LLMs, including impactful token analysis, position index transformation, and training optimization strategies. It simulates long-sequence inputs while maintaining training efficiency and significantly improves the model's understanding of long-range dependencies. Experiments on three types of LLMs show that LongRecipe can utilize long sequences while requiring only 30% of the target context window size, and reduces computational training resource over 85% compared to full sequence training. Furthermore, LongRecipe also preserves the original LLM's capabilities in general tasks. Ultimately, we can extend the effective context window of open-source LLMs from 8k to 128k, achieving performance close to GPT-4 with just one day of dedicated training using a single GPU with 80G memory. Our code is released at https://github.com/zhiyuanhubj/LongRecipe.