 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Dominance in Deep Learning I: A Scaling Law of Loss and Learning Rate
Feb 06, 2026Deep learning has non-convex loss landscape and its optimization dynamics is hard to analyze or control. Nevertheless, the dynamics can be empirically convex-like across various tasks, models, optimizers, hyperparameters, etc. In this work, we examine the applicability of convexity and Lipschitz continuity in deep learning, in order to precisely control the loss dynamics via the learning rate schedules. We illustrate that deep learning quickly becomes weakly convex after a short period of training, and the loss is predicable by an upper bound on the last iterate, which further informs the scaling of optimal learning rate. Through the lens of convexity, we build scaling laws of learning rates and losses that extrapolate as much as 80X across training horizons and 70X across model sizes.
To 2:4 Sparsity and Beyond: Neuron-level Activation Function to Accelerate LLM Pre-Training
Feb 05, 2026Trainings of Large Language Models are generally bottlenecked by matrix multiplications. In the Transformer architecture, a large portion of these operations happens in the Feed Forward Network (FFN), and this portion increases for larger models, up to 50% of the total pretraining floating point operations. We show that we can leverage hardware-accelerated sparsity to accelerate all matrix multiplications in the FFN, with 2:4 sparsity for weights and v:n:m (Venom) sparsity for activations. Our recipe relies on sparse training steps to accelerate a large part of the pretraining, associated with regular dense training steps towards the end. Overall, models trained with this approach exhibit the same performance on our quality benchmarks, and can speed up training end-to-end by 1.4 to 1.7x. This approach is applicable to all NVIDIA GPUs starting with the A100 generation, and is orthogonal to common optimization techniques, such as, quantization, and can also be applied to mixture-of-experts model architectures.
Deep Progressive Training: scaling up depth capacity of zero/one-layer models
Nov 07, 2025Model depth is a double-edged sword in deep learning: deeper models achieve higher accuracy but require higher computational cost. To efficiently train models at scale, an effective strategy is the progressive training, which scales up model capacity during training, hence significantly reducing computation with little to none performance degradation. In this work, we study the depth expansion of large models through the lens of optimization theory and feature learning, offering insights on the initialization of new layers, hyperparameter transfer, learning rate schedule, and timing of model expansion. Specifically, we propose zero/one-layer progressive training for the optimal tradeoff between computation and loss. For example, zero/one-layer progressive training on GPT2 can save $\approx 80\%$ compute, or equivalently accelerate $\approx 5\times$ while achieving almost the same loss, compared to to a fully trained 60-layer model with 7B parameters.
BLUR: A Bi-Level Optimization Approach for LLM Unlearning
Jun 09, 2025Enabling large language models (LLMs) to unlearn knowledge and capabilities acquired during training has proven vital for ensuring compliance with data regulations and promoting ethical practices in generative AI. Although there are growing interests in developing various unlearning algorithms, it remains unclear how to best formulate the unlearning problem. The most popular formulation uses a weighted sum of forget and retain loss, but it often leads to performance degradation due to the inherent trade-off between forget and retain losses. In this work, we argue that it is important to model the hierarchical structure of the unlearning problem, where the forget problem (which \textit{unlearns} certain knowledge and/or capabilities) takes priority over the retain problem (which preserves model utility). This hierarchical structure naturally leads to a bi-level optimization formulation where the lower-level objective focuses on minimizing the forget loss, while the upper-level objective aims to maintain the model's utility. Based on this new formulation, we propose a novel algorithm, termed Bi-Level UnleaRning (\texttt{BLUR}), which not only possesses strong theoretical guarantees but more importantly, delivers superior performance. In particular, our extensive experiments demonstrate that \texttt{BLUR} consistently outperforms all the state-of-the-art algorithms across various unlearning tasks, models, and metrics. Codes are available at https://github.com/OptimAI-Lab/BLURLLMUnlearning.
Adaptive parameter-efficient fine-tuning via Hessian-informed subset selection
May 18, 2025Parameter-efficient fine-tuning (PEFT) is a highly effective approach for adapting large pre-trained models to downstream tasks with minimal computational overhead. At the core, PEFT methods freeze most parameters and only trains a small subset (say $<0.1\%$ of total parameters). Notably, different PEFT methods select different subsets, resulting in varying levels of performance. This variation prompts a key question: how to effectively select the most influential subset to train? We formulate the subset selection as a multi-task problem: maximizing the performance and minimizing the number of trainable parameters. We leverage a series of transformations -- including $\epsilon$-constraint method and second-order Taylor approximation -- to arrive at the classical 0-1 knapsack problem, which we solve through the lens of Pareto optimality. Consequently, we propose AdaPEFT, a Hessian-informed PEFT that adapts to various tasks and models, in which the selected subset empirically transfers across training horizons and model sizes.
LUME: LLM Unlearning with Multitask Evaluations
Feb 20, 2025
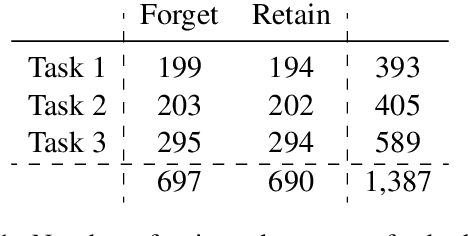
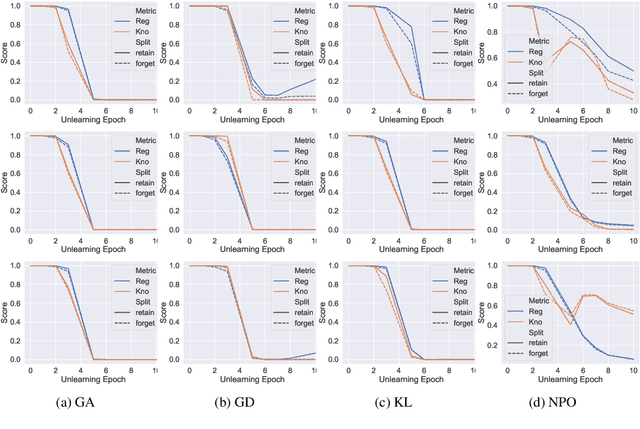
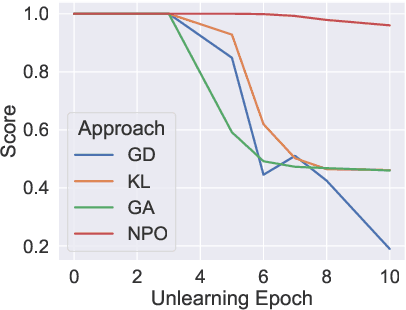
Unlearning aims to remove copyrighted, sensitive, or private content from large language models (LLMs) without a full retraining. In this work, we develop a multi-task unlearning benchmark (LUME) which features three tasks: (1) unlearn synthetically generated creative short novels, (2) unlearn synthetic biographies with sensitive information, and (3) unlearn a collection of public biographies. We further release two fine-tuned LLMs of 1B and 7B parameter sizes as the target models. We conduct detailed evaluations of several recently proposed unlearning algorithms and present results on carefully crafted metrics to understand their behavior and limitations.
A Hessian-informed hyperparameter optimization for differential learning rate
Jan 12, 2025Differential learning rate (DLR), a technique that applies different learning rates to different model parameters, has been widely used in deep learning and achieved empirical success via its various forms. For example, parameter-efficient fine-tuning (PEFT) applies zero learning rates to most parameters so as to significantly save the computational cost. At the core, DLR leverages the observation that different parameters can have different loss curvature, which is hard to characterize in general. We propose the Hessian-informed differential learning rate (Hi-DLR), an efficient approach that solves the hyperparameter optimization (HPO) of learning rates and captures the loss curvature for any model and optimizer adaptively. Given a proper grouping of parameters, we empirically demonstrate that Hi-DLR can improve the convergence by dynamically determining the learning rates during the training. Furthermore, we can quantify the influence of different parameters and freeze the less-contributing parameters, which leads to a new PEFT that automatically adapts to various tasks and models. Additionally, Hi-DLR also exhibits comparable performance on various full model training tasks.
Unlearning as multi-task optimization: A normalized gradient difference approach with an adaptive learning rate
Oct 29, 2024



Machine unlearning has been used to remove unwanted knowledge acquired by large language models (LLMs). In this paper, we examine machine unlearning from an optimization perspective, framing it as a regularized multi-task optimization problem, where one task optimizes a forgetting objective and another optimizes the model performance. In particular, we introduce a normalized gradient difference (NGDiff) algorithm, enabling us to have better control over the trade-off between the objectives, while integrating a new, automatic learning rate scheduler. We provide a theoretical analysis and empirically demonstrate the superior performance of NGDiff among state-of-the-art unlearning methods on the TOFU and MUSE datasets while exhibiting stable training.
DiSK: Differentially Private Optimizer with Simplified Kalman Filter for Noise Reduction
Oct 04, 2024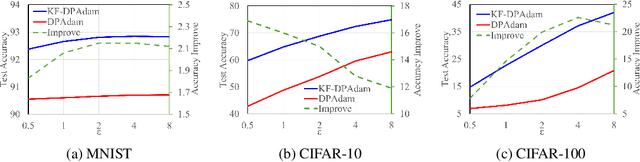
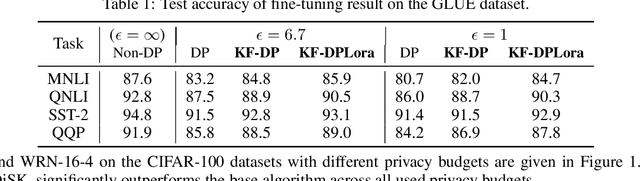
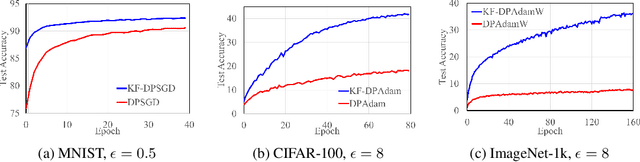
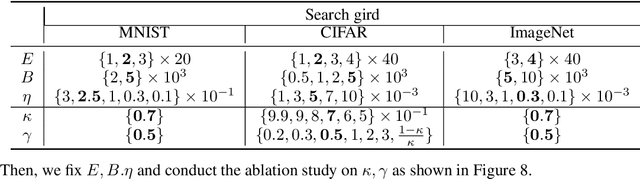
Differential privacy (DP) offers a robust framework for safeguarding individual data privacy. To utilize DP in training modern machine learning models, differentially private optimizers have been widely used in recent years. A popular approach to privatize an optimizer is to clip the individual gradients and add sufficiently large noise to the clipped gradient. This approach led to the development of DP optimizers that have comparable performance with their non-private counterparts in fine-tuning tasks or in tasks with a small number of training parameters. However, a significant performance drop is observed when these optimizers are applied to large-scale training. This degradation stems from the substantial noise injection required to maintain DP, which disrupts the optimizer's dynamics. This paper introduces DiSK, a novel framework designed to significantly enhance the performance of DP optimizers. DiSK employs Kalman filtering, a technique drawn from control and signal processing, to effectively denoise privatized gradients and generate progressively refined gradient estimations. To ensure practicality for large-scale training, we simplify the Kalman filtering process, minimizing its memory and computational demands. We establish theoretical privacy-utility trade-off guarantees for DiSK, and demonstrate provable improvements over standard DP optimizers like DPSGD in terms of iteration complexity upper-bound. Extensive experiments across diverse tasks, including vision tasks such as CIFAR-100 and ImageNet-1k and language fine-tuning tasks such as GLUE, E2E, and DART, validate the effectiveness of DiSK. The results showcase its ability to significantly improve the performance of DP optimizers, surpassing state-of-the-art results under the same privacy constraints on several benchmarks.
DOPPLER: Differentially Private Optimizers with Low-pass Filter for Privacy Noise Reduction
Aug 24, 2024



Privacy is a growing concern in modern deep-learning systems and applications. Differentially private (DP) training prevents the leakage of sensitive information in the collected training data from the trained machine learning models. DP optimizers, including DP stochastic gradient descent (DPSGD) and its variants, privatize the training procedure by gradient clipping and DP noise injection. However, in practice, DP models trained using DPSGD and its variants often suffer from significant model performance degradation. Such degradation prevents the application of DP optimization in many key tasks, such as foundation model pretraining. In this paper, we provide a novel signal processing perspective to the design and analysis of DP optimizers. We show that a ``frequency domain'' operation called low-pass filtering can be used to effectively reduce the impact of DP noise. More specifically, by defining the ``frequency domain'' for both the gradient and differential privacy (DP) noise, we have developed a new component, called DOPPLER. This component is designed for DP algorithms and works by effectively amplifying the gradient while suppressing DP noise within this frequency domain. As a result, it maintains privacy guarantees and enhances the quality of the DP-protected model. Our experiments show that the proposed DP optimizers with a low-pass filter outperform their counterparts without the filter by 3%-10% in test accuracy on various models and datasets. Both theoretical and practical evidence suggest that the DOPPLER is effective in closing the gap between DP and non-DP training.