 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-EAGLE: Parallel-Drafting EAGLE with Scalable Training
Feb 01, 2026Reasoning LLMs produce longer outputs, requiring speculative decoding drafters trained on extended sequences. Parallel drafting - predicting multiple tokens per forward pass - offers latency benefits over sequential generation, but training complexity scales quadratically with the product of sequence length and parallel positions, rendering long-context training impractical. We present P(arallel)-EAGLE, which transforms EAGLE from autoregressive to parallel multi-token prediction via a learnable shared hidden state. To scale training to long contexts, we develop a framework featuring attention mask pre-computation and sequence partitioning techniques, enabling gradient accumulation within individual sequences for parallel-prediction training. We implement P-EAGLE in vLLM and demonstrate speedups of 1.10-1.36x over autoregressive EAGLE-3 across GPT-OSS 120B, 20B, and Qwen3-Coder 30B.
MLZero: A Multi-Agent System for End-to-end Machine Learning Automation
May 20, 2025Existing AutoML systems have advanced the automation of machine learning (ML); however, they still require substantial manual configuration and expert input, particularly when handling multimodal data. We introduce MLZero, a novel multi-agent framework powered by Large Language Models (LLMs) that enables end-to-end ML automation across diverse data modalities with minimal human intervention. A cognitive perception module is first employed, transforming raw multimodal inputs into perceptual context that effectively guides the subsequent workflow. To address key limitations of LLMs, such as hallucinated code generation and outdated API knowledge, we enhance the iterative code generation process with semantic and episodic memory. MLZero demonstrates superior performance on MLE-Bench Lite, outperforming all competitors in both success rate and solution quality, securing six gold medals. Additionally, when evaluated on our Multimodal AutoML Agent Benchmark, which includes 25 more challenging tasks spanning diverse data modalities, MLZero outperforms the competing methods by a large margin with a success rate of 0.92 (+263.6\%) and an average rank of 2.28. Our approach maintains its robust effectiveness even with a compact 8B LLM, outperforming full-size systems from existing solutions.
From Demonstrations to Rewards: Alignment Without Explicit Human Preferences
Mar 15, 2025One of the challenges of aligning large models with human preferences lies in both the data requirements and the technical complexities of current approaches. Predominant methods, such as RLHF, involve multiple steps, each demanding distinct types of data, including demonstration data and preference data. In RLHF, human preferences are typically modeled through a reward model, which serves as a proxy to guide policy learning during the reinforcement learning stage, ultimately producing a policy aligned with human preferences. However, in this paper, we propose a fresh perspective on learning alignment based on inverse reinforcement learning principles, where the optimal policy is still derived from reward maximization. However, instead of relying on preference data, we directly learn the reward model from demonstration data. This new formulation offers the flexibility to be applied even when only demonstration data is available, a capability that current RLHF methods lack, and it also shows that demonstration data offers more utility than what conventional wisdom suggests. Our extensive evaluation, based on public reward benchmark, HuggingFace Open LLM Leaderboard and MT-Bench, demonstrates that our approach compares favorably to state-of-the-art methods that rely solely on demonstration data.
Understanding Silent Data Corruption in LLM Training
Feb 17, 2025As the scale of training large language models (LLMs) increases, one emergent failure is silent data corruption (SDC), where hardware produces incorrect computations without explicit failure signals. In this work, we are the first to investigate the impact of real-world SDCs on LLM training by comparing model training between healthy production nodes and unhealthy nodes exhibiting SDCs. With the help from a cloud computing platform, we access the unhealthy nodes that were swept out from production by automated fleet management. Using deterministic execution via XLA compiler and our proposed synchronization mechanisms, we isolate and analyze the impact of SDC errors on these nodes at three levels: at each submodule computation, at a single optimizer step, and at a training period. Our results reveal that the impact of SDCs on computation varies on different unhealthy nodes. Although in most cases the perturbations from SDCs on submodule computation and gradients are relatively small, SDCs can lead models to converge to different optima with different weights and even cause spikes in the training loss. Our analysis sheds light on further understanding and mitigating the impact of SDCs.
Open Materials Generation with Stochastic Interpolants
Feb 04, 2025The discovery of new materials is essential for enabling technological advancements. Computational approaches for predicting novel materials must effectively learn the manifold of stable crystal structures within an infinite design space. We introduce Open Materials Generation (OMG), a unifying framework for the generative design and discovery of inorganic crystalline materials. OMG employs stochastic interpolants (SI) to bridge an arbitrary base distribution to the target distribution of inorganic crystals via a broad class of tunable stochastic processes, encompassing both diffusion models and flow matching as special cases. In this work, we adapt the SI framework by integrating an equivariant graph representation of crystal structures and extending it to account for periodic boundary conditions in unit cell representations. Additionally, we couple the SI flow over spatial coordinates and lattice vectors with discrete flow matching for atomic species. We benchmark OMG's performance on two tasks: Crystal Structure Prediction (CSP) for specified compositions, and 'de novo' generation (DNG) aimed at discovering stable, novel, and unique structures. In our ground-up implementation of OMG, we refine and extend both CSP and DNG metrics compared to previous works. OMG establishes a new state-of-the-art in generative modeling for materials discovery, outperforming purely flow-based and diffusion-based implementations. These results underscore the importance of designing flexible deep learning frameworks to accelerate progress in materials science.
A Proximal Operator for Inducing 2:4-Sparsity
Jan 29, 2025



Recent hardware advancements in AI Accelerators and GPUs allow to efficiently compute sparse matrix multiplications, especially when 2 out of 4 consecutive weights are set to zero. However, this so-called 2:4 sparsity usually comes at a decreased accuracy of the model. We derive a regularizer that exploits the local correlation of features to find better sparsity masks in trained models. We minimize the regularizer jointly with a local squared loss by deriving the proximal operator for which we show that it has an efficient solution in the 2:4-sparse case. After optimizing the mask, we use maskedgradient updates to further minimize the local squared loss. We illustrate our method on toy problems and apply it to pruning entire large language models up to 70B parameters. On models up to 13B we improve over previous state of the art algorithms, whilst on 70B models we match their performance.
AutoG: Towards automatic graph construction from tabular data
Jan 25, 2025



Recent years have witnessed significant advancements in graph machine learning (GML), with its applications spanning numerous domains. However, the focus of GML has predominantly been on developing powerful models, often overlooking a crucial initial step: constructing suitable graphs from common data formats, such as tabular data. This construction process is fundamental to applying graphbased models, yet it remains largely understudied and lacks formalization. Our research aims to address this gap by formalizing the graph construction problem and proposing an effective solution. We identify two critical challenges to achieve this goal: 1. The absence of dedicated datasets to formalize and evaluate the effectiveness of graph construction methods, and 2. Existing automatic construction methods can only be applied to some specific cases, while tedious human engineering is required to generate high-quality graphs. To tackle these challenges, we present a two-fold contribution. First, we introduce a set of datasets to formalize and evaluate graph construction methods. Second, we propose an LLM-based solution, AutoG, automatically generating high-quality graph schemas without human intervention. The experimental results demonstrate that the quality of constructed graphs is critical to downstream task performance, and AutoG can generate high-quality graphs that rival those produced by human experts.
Bridging the Training-Inference Gap in LLMs by Leveraging Self-Generated Tokens
Oct 18, 2024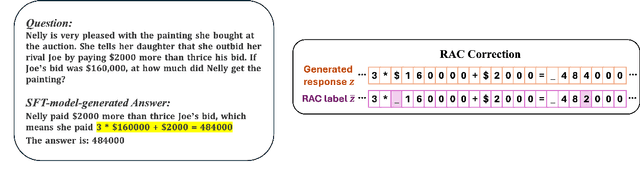
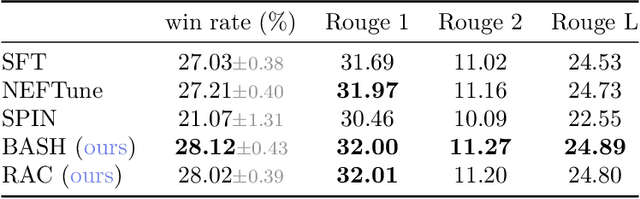
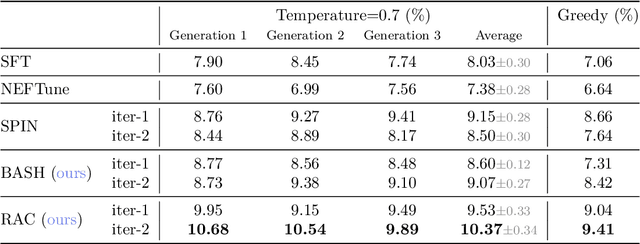
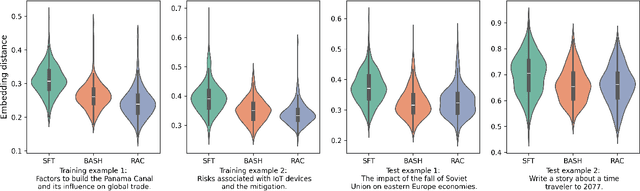
Language models are often trained to maximize the likelihood of the next token given past tokens in the training dataset. However, during inference time, they are utilized differently, generating text sequentially and auto-regressively by using previously generated tokens as input to predict the next one. Marginal differences in predictions at each step can cascade over successive steps, resulting in different distributions from what the models were trained for and potentially leading to unpredictable behavior. This paper proposes two simple approaches based on model own generation to address this discrepancy between the training and inference time. Our first approach is Batch-Scheduled Sampling, where, during training, we stochastically choose between the ground-truth token from the dataset and the model's own generated token as input to predict the next token. This is done in an offline manner, modifying the context window by interleaving ground-truth tokens with those generated by the model. Our second approach is Reference-Answer-based Correction, where we explicitly incorporate a self-correction capability into the model during training. This enables the model to effectively self-correct the gaps between the generated sequences and the ground truth data without relying on an external oracle model. By incorporating our proposed strategies during training, we have observed an overall improvement in performance compared to baseline methods, as demonstrated by our extensive experiments using summarization, general question-answering, and math question-answering tasks.
Fine-Tuning Language Models on Multiple Datasets for Citation Intention Classification
Oct 17, 2024



Citation intention Classification (CIC) tools classify citations by their intention (e.g., background, motivation) and assist readers in evaluating the contribution of scientific literature. Prior research has shown that pretrained language models (PLMs) such as SciBERT can achieve state-of-the-art performance on CIC benchmarks. PLMs are trained via self-supervision tasks on a large corpus of general text and can quickly adapt to CIC tasks via moderate fine-tuning on the corresponding dataset. Despite their advantages, PLMs can easily overfit small datasets during fine-tuning. In this paper, we propose a multi-task learning (MTL) framework that jointly fine-tunes PLMs on a dataset of primary interest together with multiple auxiliary CIC datasets to take advantage of additional supervision signals. We develop a data-driven task relation learning (TRL) method that controls the contribution of auxiliary datasets to avoid negative transfer and expensive hyper-parameter tuning. We conduct experiments on three CIC datasets and show that fine-tuning with additional datasets can improve the PLMs' generalization performance on the primary dataset. PLMs fine-tuned with our proposed framework outperform the current state-of-the-art models by 7% to 11% on small datasets while aligning with the best-performing model on a large dataset.
AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web Agents
Oct 17, 2024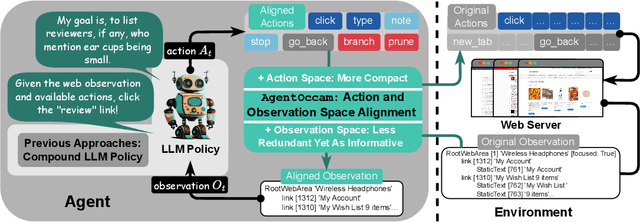
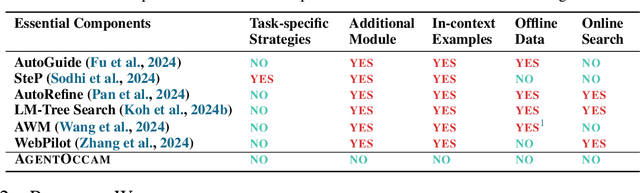
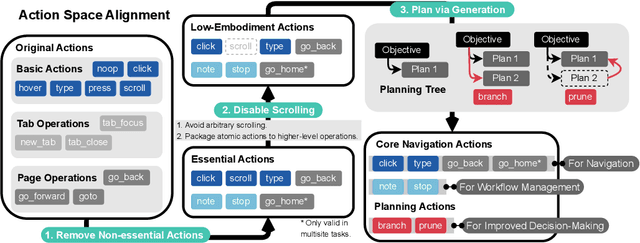

Autonomy via agents using large language models (LLMs) for personalized, standardized tasks boosts human efficiency. Automating web tasks (like booking hotels within a budget) is increasingly sought after. Fulfilling practical needs, the web agent also serves as an important proof-of-concept example for various agent grounding scenarios, with its success promising advancements in many future applications. Prior research often handcrafts web agent strategies (e.g., prompting templates, multi-agent systems, search methods, etc.) and the corresponding in-context examples, which may not generalize well across all real-world scenarios. On the other hand, there has been limited study on the misalignment between a web agent's observation/action representation and the pre-training data of the LLM it's based on. This discrepancy is especially notable when LLMs are primarily trained for language completion rather than tasks involving embodied navigation actions and symbolic web elements. Our study enhances an LLM-based web agent by simply refining its observation and action space to better align with the LLM's capabilities. This approach enables our base agent to significantly outperform previous methods on a wide variety of web tasks. Specifically, on WebArena, a benchmark featuring general-purpose web interaction tasks, our agent AgentOccam surpasses the previous state-of-the-art and concurrent work by 9.8 (+29.4%) and 5.9 (+15.8%) absolute points respectively, and boosts the success rate by 26.6 points (+161%) over similar plain web agents with its observation and action space alignment. We achieve this without using in-context examples, new agent roles, online feedback or search strategies. AgentOccam's simple design highlights LLMs' impressive zero-shot performance on web tasks, and underlines the critical role of carefully tuning observation and action spaces for LLM-based agents.