 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting SMoE Language Models by Evaluating Inefficiencies with Task Specific Expert Pruning
Sep 02, 2024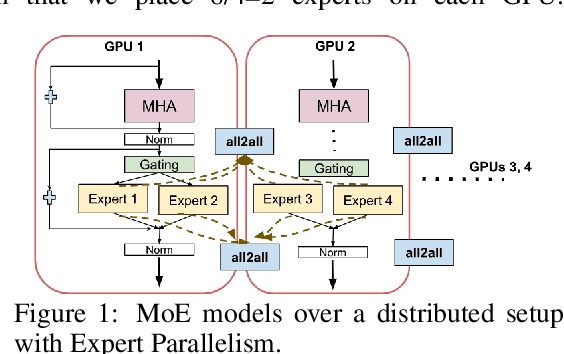

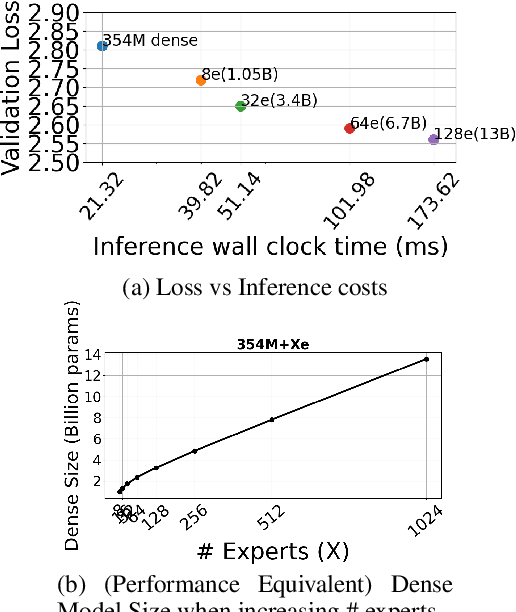
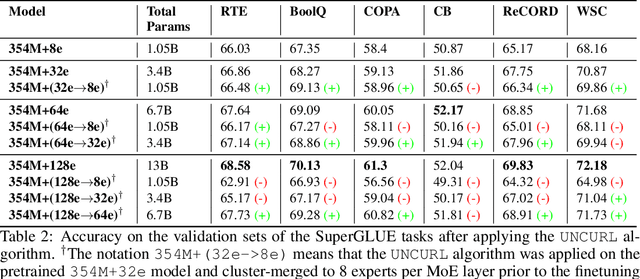
Sparse Mixture of Expert (SMoE) models have emerged as a scalable alternative to dense models in language modeling. These models use conditionally activated feedforward subnetworks in transformer blocks, allowing for a separation between total model parameters and per-example computation. However, large token-routed SMoE models face a significant challenge: during inference, the entire model must be used for a sequence or a batch, resulting in high latencies in a distributed setting that offsets the advantages of per-token sparse activation. Our research explores task-specific model pruning to inform decisions about designing SMoE architectures, mainly modulating the choice of expert counts in pretraining. We investigate whether such pruned models offer advantages over smaller SMoE models trained from scratch, when evaluating and comparing them individually on tasks. To that end, we introduce an adaptive task-aware pruning technique UNCURL to reduce the number of experts per MoE layer in an offline manner post-training. Our findings reveal a threshold pruning factor for the reduction that depends on the number of experts used in pretraining, above which, the reduction starts to degrade model performance. These insights contribute to our understanding of model design choices when pretraining with SMoE architectures, particularly useful when considering task-specific inference optimization for later stages.
EMC$^2$: Efficient MCMC Negative Sampling for Contrastive Learning with Global Convergence
Apr 16, 2024



A key challenge in contrastive learning is to generate negative samples from a large sample set to contrast with positive samples, for learning better encoding of the data. These negative samples often follow a softmax distribution which are dynamically updated during the training process. However, sampling from this distribution is non-trivial due to the high computational costs in computing the partition function. In this paper, we propose an Efficient Markov Chain Monte Carlo negative sampling method for Contrastive learning (EMC$^2$). We follow the global contrastive learning loss as introduced in SogCLR, and propose EMC$^2$ which utilizes an adaptive Metropolis-Hastings subroutine to generate hardness-aware negative samples in an online fashion during the optimization. We prove that EMC$^2$ finds an $\mathcal{O}(1/\sqrt{T})$-stationary point of the global contrastive loss in $T$ iterations. Compared to prior works, EMC$^2$ is the first algorithm that exhibits global convergence (to stationarity) regardless of the choice of batch size while exhibiting low computation and memory cost. Numerical experiments validate that EMC$^2$ is effective with small batch training and achieves comparable or better performance than baseline algorithms. We report the results for pre-training image encoders on STL-10 and Imagenet-100.
Testing the Limits of Unified Sequence to Sequence LLM Pretraining on Diverse Table Data Tasks
Oct 01, 2023
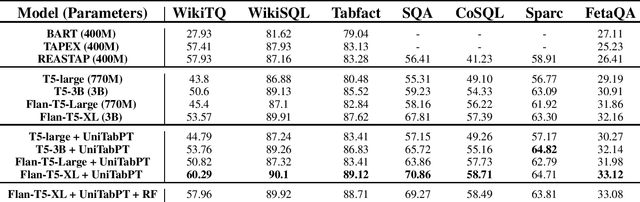
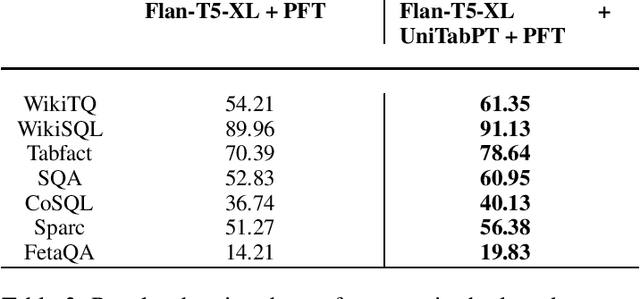
Tables stored in databases and tables which are present in web pages and articles account for a large part of semi-structured data that is available on the internet. It then becomes pertinent to develop a modeling approach with large language models (LLMs) that can be used to solve diverse table tasks such as semantic parsing, question answering as well as classification problems. Traditionally, there existed separate models specialized for each task individually. It raises the question of how far can we go to build a unified model that works well on some table tasks without significant degradation on others. To that end, we attempt at creating a shared modeling approach in the pretraining stage with encoder-decoder style LLMs that can cater to diverse tasks. We evaluate our approach that continually pretrains and finetunes different model families of T5 with data from tables and surrounding context, on these downstream tasks at different model scales. Through multiple ablation studies, we observe that our pretraining with self-supervised objectives can significantly boost the performance of the models on these tasks. As an example of one improvement, we observe that the instruction finetuned public models which come specialized on text question answering (QA) and have been trained on table data still have room for improvement when it comes to table specific QA. Our work is the first attempt at studying the advantages of a unified approach to table specific pretraining when scaled from 770M to 11B sequence to sequence models while also comparing the instruction finetuned variants of the models.
HYTREL: Hypergraph-enhanced Tabular Data Representation Learning
Jul 14, 2023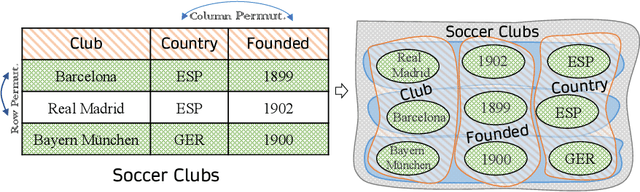
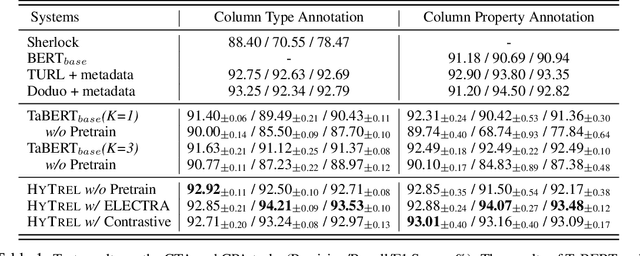
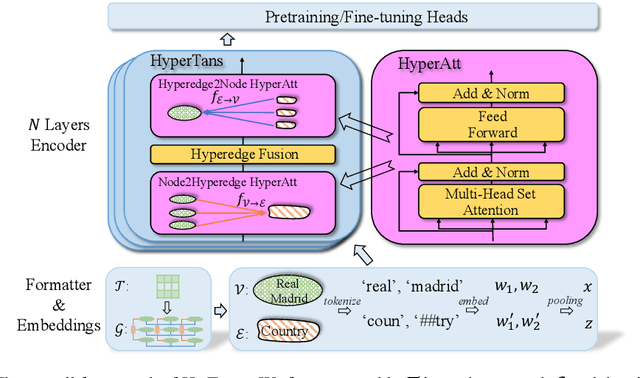
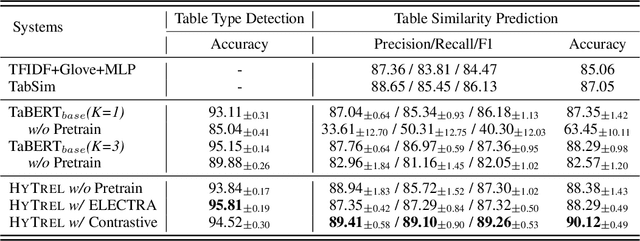
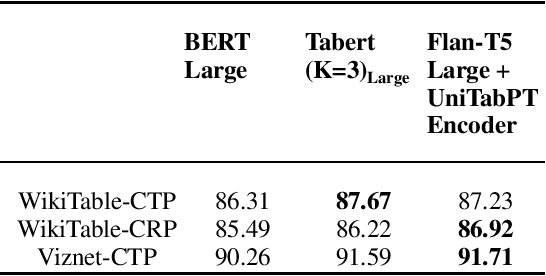
Language models pretrained on large collections of tabular data have demonstrated their effectiveness in several downstream tasks. However, many of these models do not take into account the row/column permutation invariances, hierarchical structure, etc. that exist in tabular data. To alleviate these limitations, we propose HYTREL, a tabular language model, that captures the permutation invariances and three more structural properties of tabular data by using hypergraphs - where the table cells make up the nodes and the cells occurring jointly together in each row, column, and the entire table are used to form three different types of hyperedges. We show that HYTREL is maximally invariant under certain conditions for tabular data, i.e., two tables obtain the same representations via HYTREL iff the two tables are identical up to permutations. Our empirical results demonstrate that HYTREL consistently outperforms other competitive baselines on four downstream tasks with minimal pretraining, illustrating the advantages of incorporating the inductive biases associated with tabular data into the representations. Finally, our qualitative analyses showcase that HYTREL can assimilate the table structures to generate robust representations for the cells, rows, columns, and the entire table.
An Algorithm For Adversary Aware Decentralized Networked MARL
May 09, 2023Decentralized multi-agent reinforcement learning (MARL) algorithms have become popular in the literature since it allows heterogeneous agents to have their own reward functions as opposed to canonical multi-agent Markov Decision Process (MDP) settings which assume common reward functions over all agents. In this work, we follow the existing work on collaborative MARL where agents in a connected time varying network can exchange information among each other in order to reach a consensus. We introduce vulnerabilities in the consensus updates of existing MARL algorithms where agents can deviate from their usual consensus update, who we term as adversarial agents. We then proceed to provide an algorithm that allows non-adversarial agents to reach a consensus in the presence of adversaries under a constrained setting.
Parameter and Data Efficient Continual Pre-training for Robustness to Dialectal Variance in Arabic
Nov 08, 2022The use of multilingual language models for tasks in low and high-resource languages has been a success story in deep learning. In recent times, Arabic has been receiving widespread attention on account of its dialectal variance. While prior research studies have tried to adapt these multilingual models for dialectal variants of Arabic, it still remains a challenging problem owing to the lack of sufficient monolingual dialectal data and parallel translation data of such dialectal variants. It remains an open problem on whether the limited dialectical data can be used to improve the models trained in Arabic on its dialectal variants. First, we show that multilingual-BERT (mBERT) incrementally pretrained on Arabic monolingual data takes less training time and yields comparable accuracy when compared to our custom monolingual Arabic model and beat existing models (by an avg metric of +$6.41$). We then explore two continual pre-training methods -- (1) using small amounts of dialectical data for continual finetuning and (2) parallel Arabic to English data and a Translation Language Modeling loss function. We show that both approaches help improve performance on dialectal classification tasks ($+4.64$ avg. gain) when used on monolingual models.
Bandit based centralized matching in two-sided markets for peer to peer lending
May 06, 2021
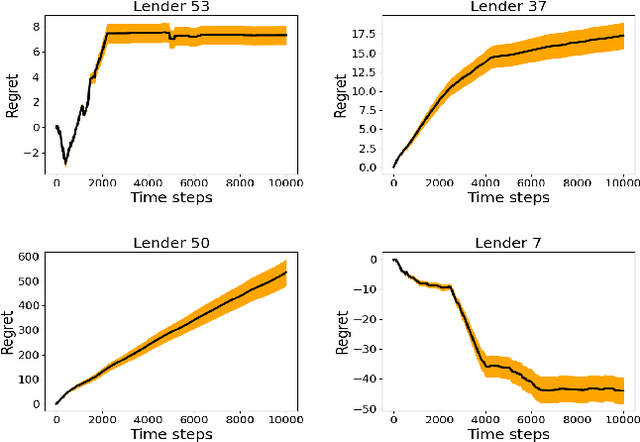
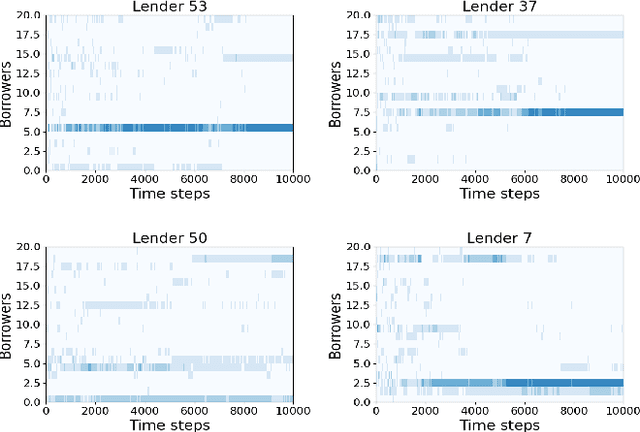
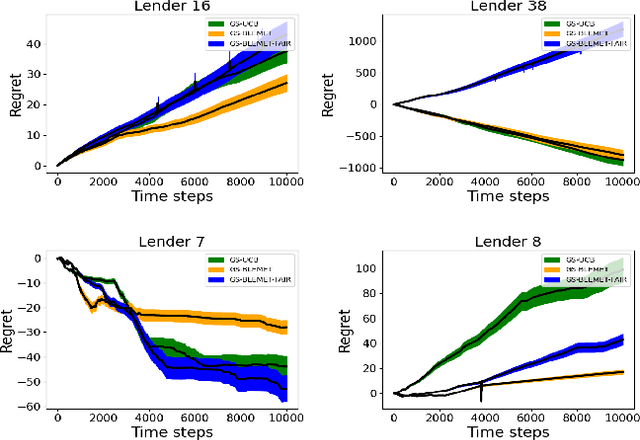
Sequential fundraising in two sided online platforms enable peer to peer lending by sequentially bringing potential contributors, each of whose decisions impact other contributors in the market. However, understanding the dynamics of sequential contributions in online platforms for peer lending has been an open ended research question. The centralized investment mechanism in these platforms makes it difficult to understand the implicit competition that borrowers face from a single lender at any point in time. Matching markets are a model of pairing agents where the preferences of agents from both sides in terms of their preferred pairing for transactions can allow to decentralize the market. We study investment designs in two sided platforms using matching markets when the investors or lenders also face restrictions on the investments based on borrower preferences. This situation creates an implicit competition among the lenders in addition to the existing borrower competition, especially when the lenders are uncertain about their standing in the market and thereby the probability of their investments being accepted or the borrower loan requests for projects reaching the reserve price. We devise a technique based on sequential decision making that allows the lenders to adjust their choices based on the dynamics of uncertainty from competition over time. We simulate two sided market matchings in a sequential decision framework and show the dynamics of the lender regret amassed compared to the optimal borrower-lender matching and find that the lender regret depends on the initial preferences set by the lenders which could affect their learning over decision making steps.
Bandits in Matching Markets: Ideas and Proposals for Peer Lending
Oct 30, 2020Motivated by recent applications of sequential decision making in matching markets, in this paper we attempt at formulating and abstracting market designs in peer lending. In the rest of this paper, what will follow is a paradigm to set the stage for how peer lending can be conceived from a matching market perspective with sequential design making embedded in it. We attempt at laying the stepping stones toward understanding how sequential decision making can be made more flexible in peer lending platforms and as a way to devise more fair and equitable outcomes for both borrowers and lenders. The goal of this paper is to provide some ideas on how and why lending platforms conceived from the perspective of matching markets can allow for incorporating fairness and equitable outcomes when we design lending platforms.
Mitigating Bias in Online Microfinance Platforms: A Case Study on Kiva.org
Jun 20, 2020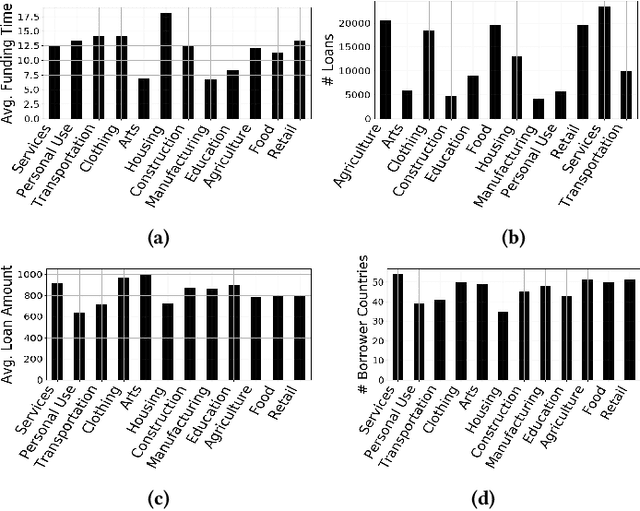

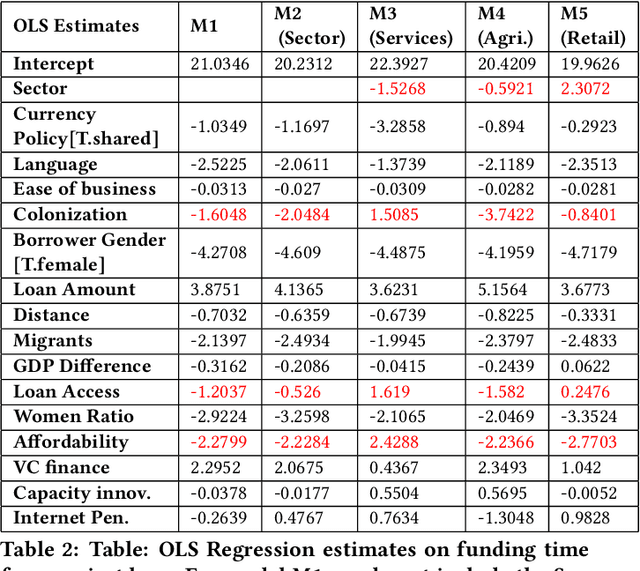
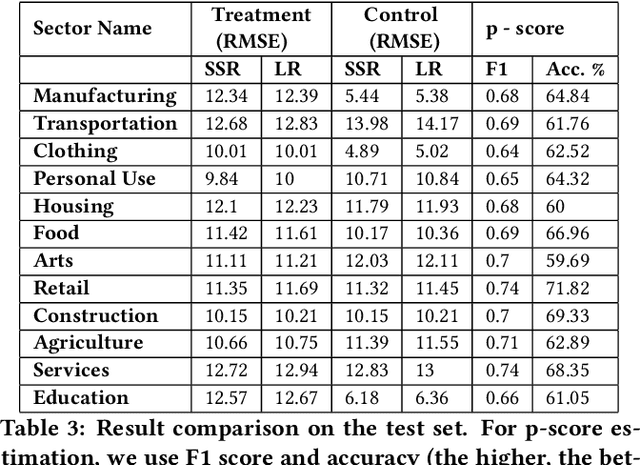
Over the last couple of decades in the lending industry, financial disintermediation has occurred on a global scale. Traditionally, even for small supply of funds, banks would act as the conduit between the funds and the borrowers. It has now been possible to overcome some of the obstacles associated with such supply of funds with the advent of online platforms like Kiva, Prosper, LendingClub. Kiva for example, works with Micro Finance Institutions (MFIs) in developing countries to build Internet profiles of borrowers with a brief biography, loan requested, loan term, and purpose. Kiva, in particular, allows lenders to fund projects in different sectors through group or individual funding. Traditional research studies have investigated various factors behind lender preferences purely from the perspective of loan attributes and only until recently have some cross-country cultural preferences been investigated. In this paper, we investigate lender perceptions of economic factors of the borrower countries in relation to their preferences towards loans associated with different sectors. We find that the influence from economic factors and loan attributes can have substantially different roles to play for different sectors in achieving faster funding. We formally investigate and quantify the hidden biases prevalent in different loan sectors using recent tools from causal inference and regression models that rely on Bayesian variable selection methods. We then extend these models to incorporate fairness constraints based on our empirical analysis and find that such models can still achieve near comparable results with respect to baseline regression models.