 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Silent Data Corruption in LLM Training
Feb 17, 2025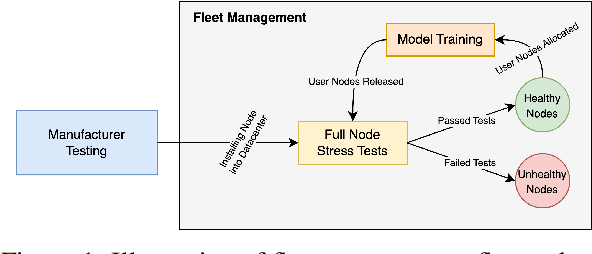



As the scale of training large language models (LLMs) increases, one emergent failure is silent data corruption (SDC), where hardware produces incorrect computations without explicit failure signals. In this work, we are the first to investigate the impact of real-world SDCs on LLM training by comparing model training between healthy production nodes and unhealthy nodes exhibiting SDCs. With the help from a cloud computing platform, we access the unhealthy nodes that were swept out from production by automated fleet management. Using deterministic execution via XLA compiler and our proposed synchronization mechanisms, we isolate and analyze the impact of SDC errors on these nodes at three levels: at each submodule computation, at a single optimizer step, and at a training period. Our results reveal that the impact of SDCs on computation varies on different unhealthy nodes. Although in most cases the perturbations from SDCs on submodule computation and gradients are relatively small, SDCs can lead models to converge to different optima with different weights and even cause spikes in the training loss. Our analysis sheds light on further understanding and mitigating the impact of SDCs.
Revisiting SMoE Language Models by Evaluating Inefficiencies with Task Specific Expert Pruning
Sep 02, 2024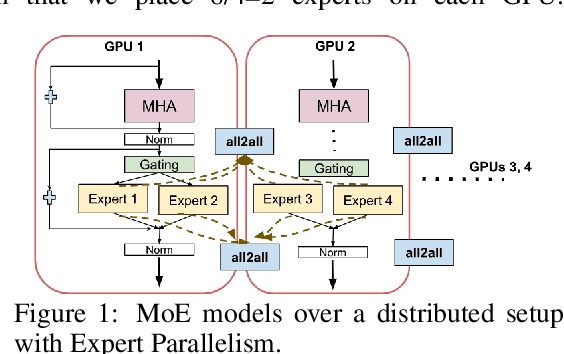

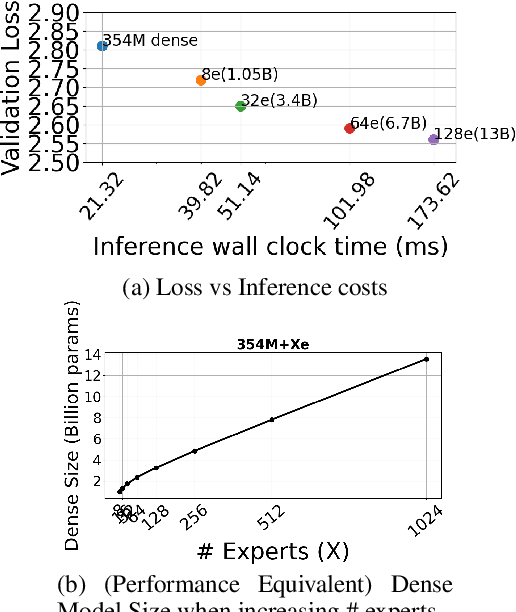
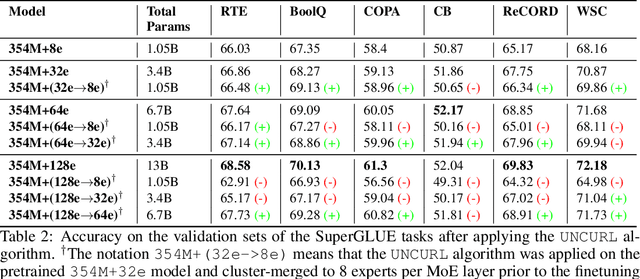
Sparse Mixture of Expert (SMoE) models have emerged as a scalable alternative to dense models in language modeling. These models use conditionally activated feedforward subnetworks in transformer blocks, allowing for a separation between total model parameters and per-example computation. However, large token-routed SMoE models face a significant challenge: during inference, the entire model must be used for a sequence or a batch, resulting in high latencies in a distributed setting that offsets the advantages of per-token sparse activation. Our research explores task-specific model pruning to inform decisions about designing SMoE architectures, mainly modulating the choice of expert counts in pretraining. We investigate whether such pruned models offer advantages over smaller SMoE models trained from scratch, when evaluating and comparing them individually on tasks. To that end, we introduce an adaptive task-aware pruning technique UNCURL to reduce the number of experts per MoE layer in an offline manner post-training. Our findings reveal a threshold pruning factor for the reduction that depends on the number of experts used in pretraining, above which, the reduction starts to degrade model performance. These insights contribute to our understanding of model design choices when pretraining with SMoE architectures, particularly useful when considering task-specific inference optimization for later stages.
Testing the Limits of Unified Sequence to Sequence LLM Pretraining on Diverse Table Data Tasks
Oct 01, 2023
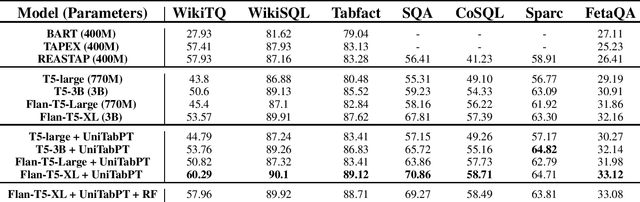
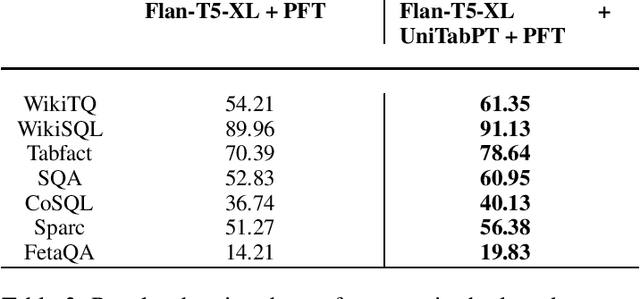
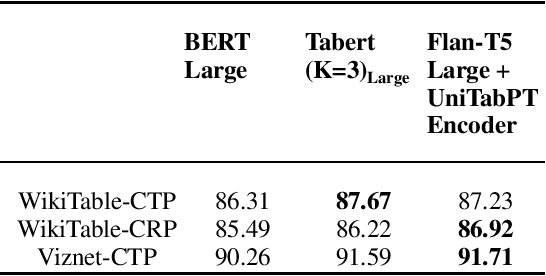
Tables stored in databases and tables which are present in web pages and articles account for a large part of semi-structured data that is available on the internet. It then becomes pertinent to develop a modeling approach with large language models (LLMs) that can be used to solve diverse table tasks such as semantic parsing, question answering as well as classification problems. Traditionally, there existed separate models specialized for each task individually. It raises the question of how far can we go to build a unified model that works well on some table tasks without significant degradation on others. To that end, we attempt at creating a shared modeling approach in the pretraining stage with encoder-decoder style LLMs that can cater to diverse tasks. We evaluate our approach that continually pretrains and finetunes different model families of T5 with data from tables and surrounding context, on these downstream tasks at different model scales. Through multiple ablation studies, we observe that our pretraining with self-supervised objectives can significantly boost the performance of the models on these tasks. As an example of one improvement, we observe that the instruction finetuned public models which come specialized on text question answering (QA) and have been trained on table data still have room for improvement when it comes to table specific QA. Our work is the first attempt at studying the advantages of a unified approach to table specific pretraining when scaled from 770M to 11B sequence to sequence models while also comparing the instruction finetuned variants of the models.
HYTREL: Hypergraph-enhanced Tabular Data Representation Learning
Jul 14, 2023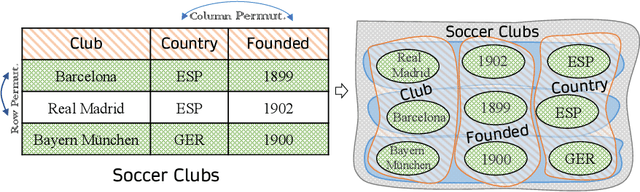
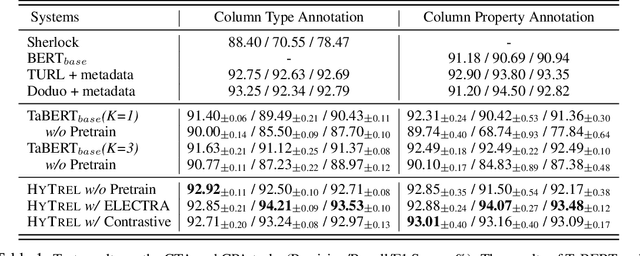
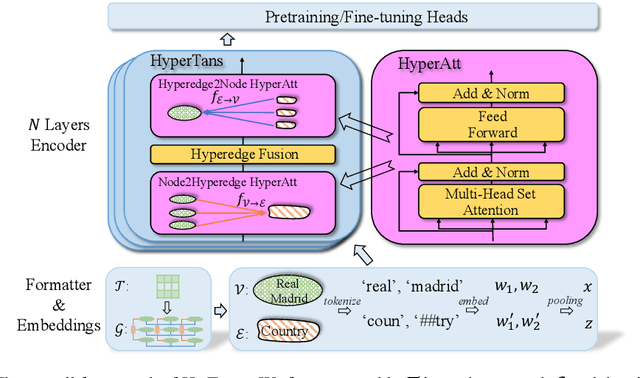
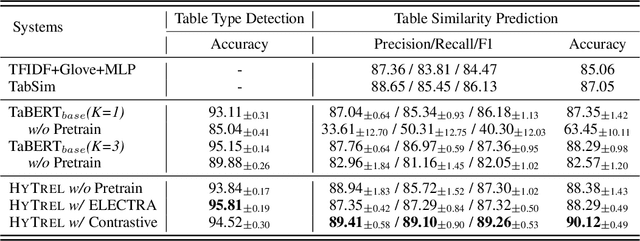
Language models pretrained on large collections of tabular data have demonstrated their effectiveness in several downstream tasks. However, many of these models do not take into account the row/column permutation invariances, hierarchical structure, etc. that exist in tabular data. To alleviate these limitations, we propose HYTREL, a tabular language model, that captures the permutation invariances and three more structural properties of tabular data by using hypergraphs - where the table cells make up the nodes and the cells occurring jointly together in each row, column, and the entire table are used to form three different types of hyperedges. We show that HYTREL is maximally invariant under certain conditions for tabular data, i.e., two tables obtain the same representations via HYTREL iff the two tables are identical up to permutations. Our empirical results demonstrate that HYTREL consistently outperforms other competitive baselines on four downstream tasks with minimal pretraining, illustrating the advantages of incorporating the inductive biases associated with tabular data into the representations. Finally, our qualitative analyses showcase that HYTREL can assimilate the table structures to generate robust representations for the cells, rows, columns, and the entire table.
Large Language Models of Code Fail at Completing Code with Potential Bugs
Jun 06, 2023



Large language models of code (Code-LLMs) have recently brought tremendous advances to code completion, a fundamental feature of programming assistance and code intelligence. However, most existing works ignore the possible presence of bugs in the code context for generation, which are inevitable in software development. Therefore, we introduce and study the buggy-code completion problem, inspired by the realistic scenario of real-time code suggestion where the code context contains potential bugs -- anti-patterns that can become bugs in the completed program. To systematically study the task, we introduce two datasets: one with synthetic bugs derived from semantics-altering operator changes (buggy-HumanEval) and one with realistic bugs derived from user submissions to coding problems (buggy-FixEval). We find that the presence of potential bugs significantly degrades the generation performance of the high-performing Code-LLMs. For instance, the passing rates of CodeGen-2B-mono on test cases of buggy-HumanEval drop more than 50% given a single potential bug in the context. Finally, we investigate several post-hoc methods for mitigating the adverse effect of potential bugs and find that there remains a large gap in post-mitigation performance.
Better Context Makes Better Code Language Models: A Case Study on Function Call Argument Completion
Jun 01, 2023



Pretrained code language models have enabled great progress towards program synthesis. However, common approaches only consider in-file local context and thus miss information and constraints imposed by other parts of the codebase and its external dependencies. Existing code completion benchmarks also lack such context. To resolve these restrictions we curate a new dataset of permissively licensed Python packages that includes full projects and their dependencies and provide tools to extract non-local information with the help of program analyzers. We then focus on the task of function call argument completion which requires predicting the arguments to function calls. We show that existing code completion models do not yield good results on our completion task. To better solve this task, we query a program analyzer for information relevant to a given function call, and consider ways to provide the analyzer results to different code completion models during inference and training. Our experiments show that providing access to the function implementation and function usages greatly improves the argument completion performance. Our ablation study provides further insights on how different types of information available from the program analyzer and different ways of incorporating the information affect the model performance.
Parameter and Data Efficient Continual Pre-training for Robustness to Dialectal Variance in Arabic
Nov 08, 2022The use of multilingual language models for tasks in low and high-resource languages has been a success story in deep learning. In recent times, Arabic has been receiving widespread attention on account of its dialectal variance. While prior research studies have tried to adapt these multilingual models for dialectal variants of Arabic, it still remains a challenging problem owing to the lack of sufficient monolingual dialectal data and parallel translation data of such dialectal variants. It remains an open problem on whether the limited dialectical data can be used to improve the models trained in Arabic on its dialectal variants. First, we show that multilingual-BERT (mBERT) incrementally pretrained on Arabic monolingual data takes less training time and yields comparable accuracy when compared to our custom monolingual Arabic model and beat existing models (by an avg metric of +$6.41$). We then explore two continual pre-training methods -- (1) using small amounts of dialectical data for continual finetuning and (2) parallel Arabic to English data and a Translation Language Modeling loss function. We show that both approaches help improve performance on dialectal classification tasks ($+4.64$ avg. gain) when used on monolingual models.
Exploring the Role of Task Transferability in Large-Scale Multi-Task Learning
Apr 23, 2022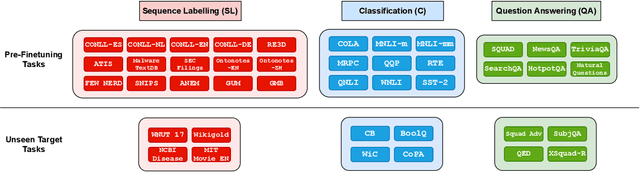
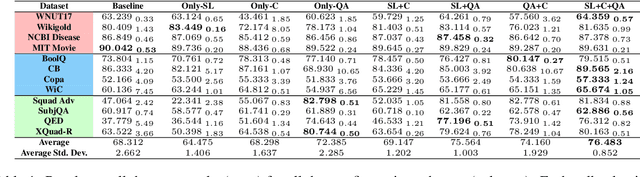
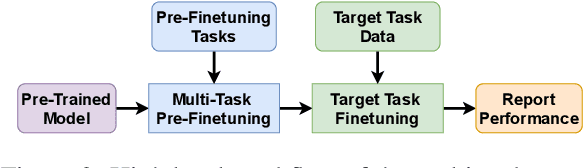

Recent work has found that multi-task training with a large number of diverse tasks can uniformly improve downstream performance on unseen target tasks. In contrast, literature on task transferability has established that the choice of intermediate tasks can heavily affect downstream task performance. In this work, we aim to disentangle the effect of scale and relatedness of tasks in multi-task representation learning. We find that, on average, increasing the scale of multi-task learning, in terms of the number of tasks, indeed results in better learned representations than smaller multi-task setups. However, if the target tasks are known ahead of time, then training on a smaller set of related tasks is competitive to the large-scale multi-task training at a reduced computational cost.
GluonCV and GluonNLP: Deep Learning in Computer Vision and Natural Language Processing
Jul 09, 2019
We present GluonCV and GluonNLP, the deep learning toolkits for computer vision and natural language processing based on Apache MXNet (incubating). These toolkits provide state-of-the-art pre-trained models, training scripts, and training logs, to facilitate rapid prototyping and promote reproducible research. We also provide modular APIs with flexible building blocks to enable efficient customization. Leveraging the MXNet ecosystem, the deep learning models in GluonCV and GluonNLP can be deployed onto a variety of platforms with different programming languages. Benefiting from open source under the Apache 2.0 license, GluonCV and GluonNLP have attracted 100 contributors worldwide on GitHub. Models of GluonCV and GluonNLP have been downloaded for more than 1.6 million times in fewer than 10 months.
NSML: A Machine Learning Platform That Enables You to Focus on Your Models
Dec 16, 2017
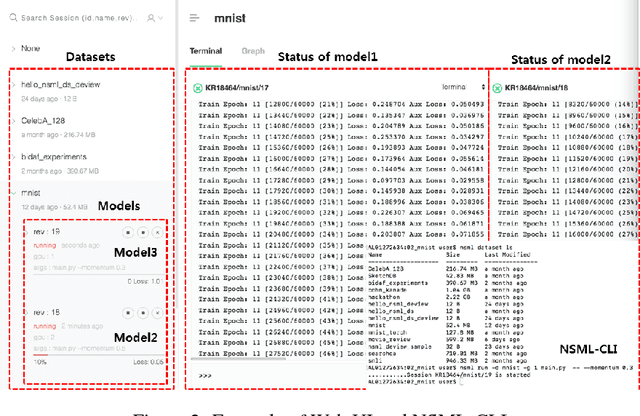

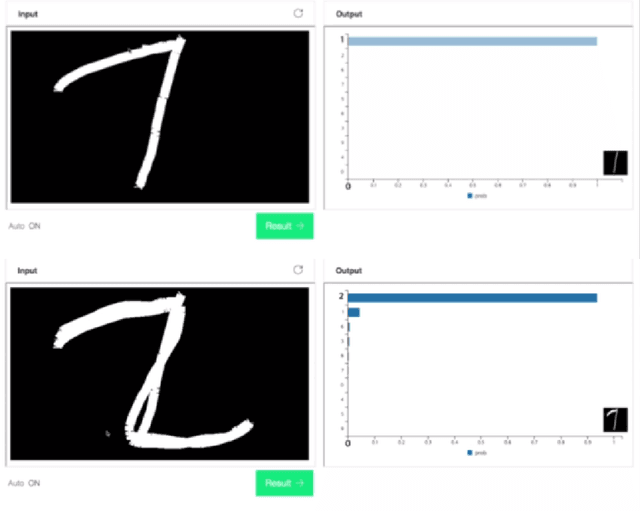
Machine learning libraries such as TensorFlow and PyTorch simplify model implementation. However, researchers are still required to perform a non-trivial amount of manual tasks such as GPU allocation, training status tracking, and comparison of models with different hyperparameter settings. We propose a system to handle these tasks and help researchers focus on models. We present the requirements of the system based on a collection of discussions from an online study group comprising 25k members. These include automatic GPU allocation, learning status visualization, handling model parameter snapshots as well as hyperparameter modification during learning, and comparison of performance metrics between models via a leaderboard. We describe the system architecture that fulfills these requirements and present a proof-of-concept implementation, NAVER Smart Machine Learning (NSML). We test the system and confirm substantial efficiency improvements for model development.