 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
NSML: Meet the MLaaS platform with a real-world case study
Oct 08, 2018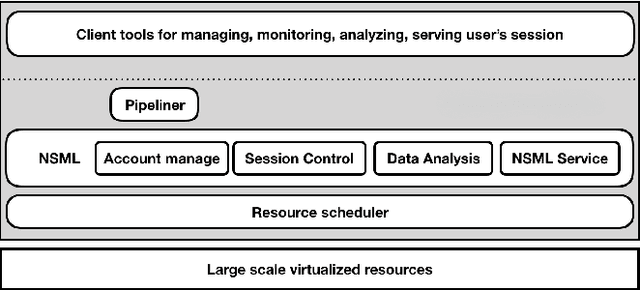
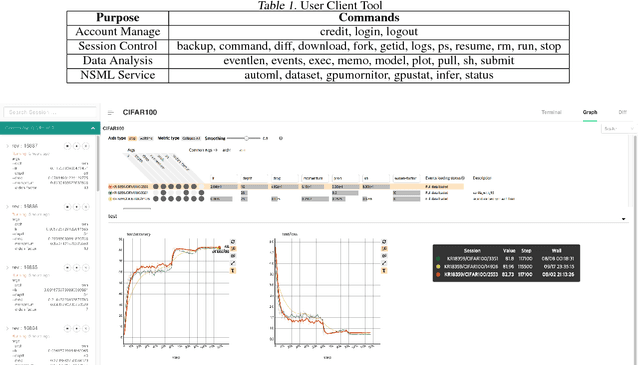
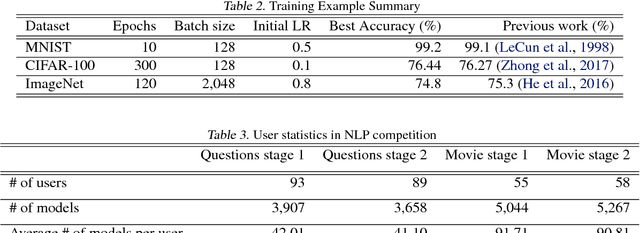
The boom of deep learning induced many industries and academies to introduce machine learning based approaches into their concern, competitively. However, existing machine learning frameworks are limited to sufficiently fulfill the collaboration and management for both data and models. We proposed NSML, a machine learning as a service (MLaaS) platform, to meet these demands. NSML helps machine learning work be easily launched on a NSML cluster and provides a collaborative environment which can afford development at enterprise scale. Finally, NSML users can deploy their own commercial services with NSML cluster. In addition, NSML furnishes convenient visualization tools which assist the users in analyzing their work. To verify the usefulness and accessibility of NSML, we performed some experiments with common examples. Furthermore, we examined the collaborative advantages of NSML through three competitions with real-world use cases.
NSML: A Machine Learning Platform That Enables You to Focus on Your Models
Dec 16, 2017
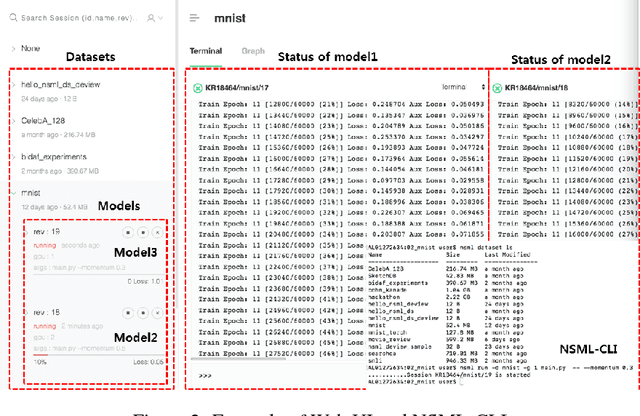

Machine learning libraries such as TensorFlow and PyTorch simplify model implementation. However, researchers are still required to perform a non-trivial amount of manual tasks such as GPU allocation, training status tracking, and comparison of models with different hyperparameter settings. We propose a system to handle these tasks and help researchers focus on models. We present the requirements of the system based on a collection of discussions from an online study group comprising 25k members. These include automatic GPU allocation, learning status visualization, handling model parameter snapshots as well as hyperparameter modification during learning, and comparison of performance metrics between models via a leaderboard. We describe the system architecture that fulfills these requirements and present a proof-of-concept implementation, NAVER Smart Machine Learning (NSML). We test the system and confirm substantial efficiency improvements for model development.