 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemand Layering for Real-Time DNN Inference with Minimized Memory Usage
Oct 08, 2022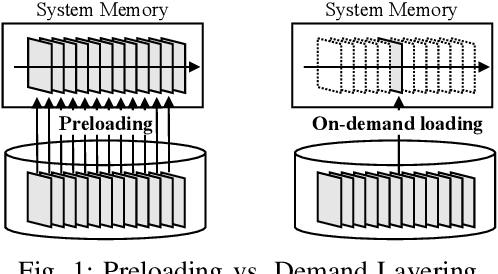
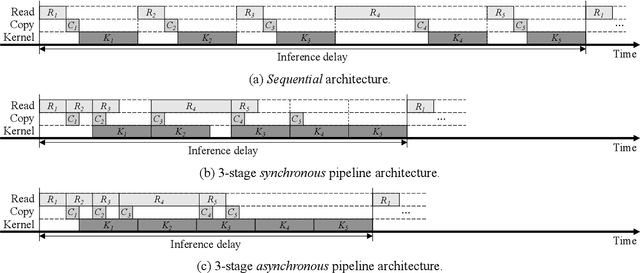
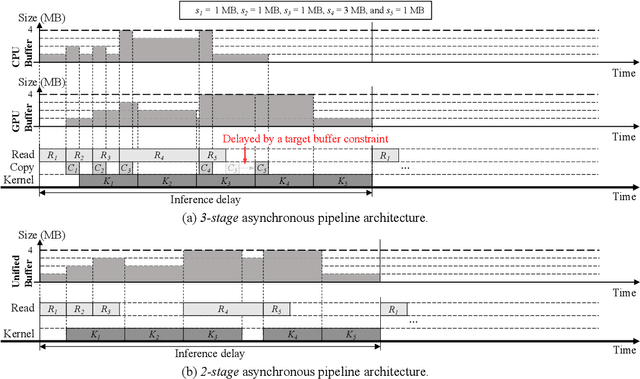
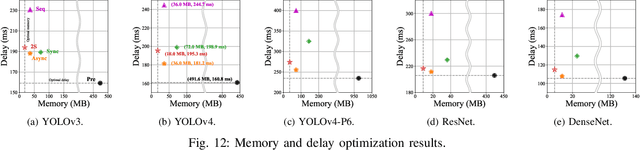
When executing a deep neural network (DNN), its model parameters are loaded into GPU memory before execution, incurring a significant GPU memory burden. There are studies that reduce GPU memory usage by exploiting CPU memory as a swap device. However, this approach is not applicable in most embedded systems with integrated GPUs where CPU and GPU share a common memory. In this regard, we present Demand Layering, which employs a fast solid-state drive (SSD) as a co-running partner of a GPU and exploits the layer-by-layer execution of DNNs. In our approach, a DNN is loaded and executed in a layer-by-layer manner, minimizing the memory usage to the order of a single layer. Also, we developed a pipeline architecture that hides most additional delays caused by the interleaved parameter loadings alongside layer executions. Our implementation shows a 96.5% memory reduction with just 14.8% delay overhead on average for representative DNNs. Furthermore, by exploiting the memory-delay tradeoff, near-zero delay overhead (under 1 ms) can be achieved with a slightly increased memory usage (still an 88.4% reduction), showing the great potential of Demand Layering.
Hybrid Learning for Orchestrating Deep Learning Inference in Multi-user Edge-cloud Networks
Feb 21, 2022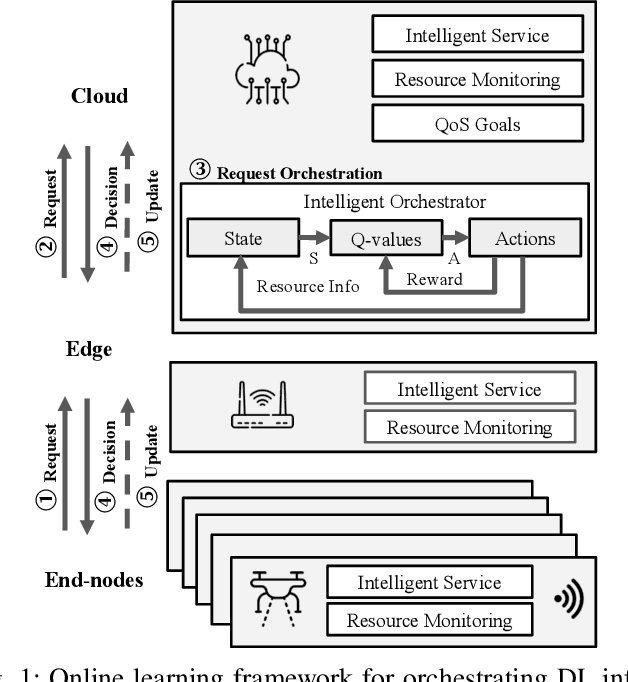
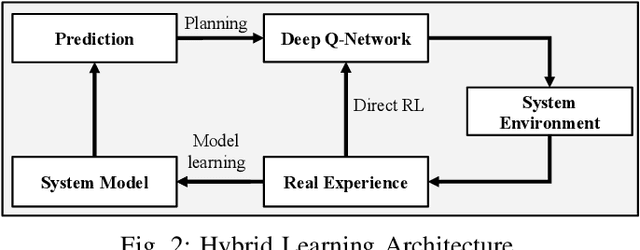
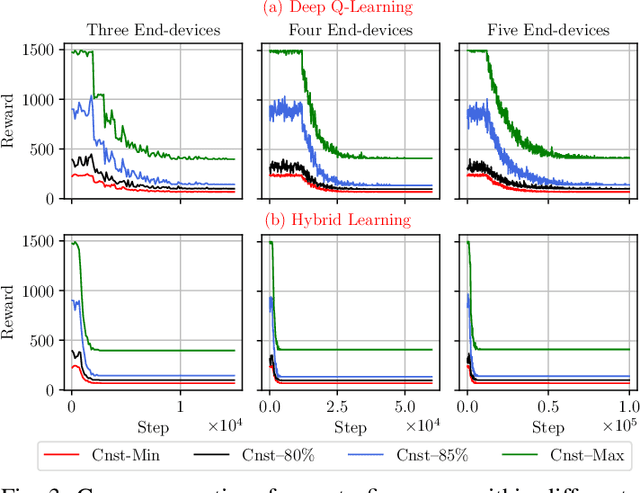
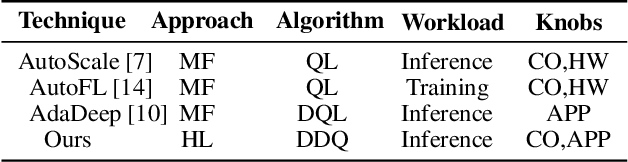
Deep-learning-based intelligent services have become prevalent in cyber-physical applications including smart cities and health-care. Collaborative end-edge-cloud computing for deep learning provides a range of performance and efficiency that can address application requirements through computation offloading. The decision to offload computation is a communication-computation co-optimization problem that varies with both system parameters (e.g., network condition) and workload characteristics (e.g., inputs). Identifying optimal orchestration considering the cross-layer opportunities and requirements in the face of varying system dynamics is a challenging multi-dimensional problem. While Reinforcement Learning (RL) approaches have been proposed earlier, they suffer from a large number of trial-and-errors during the learning process resulting in excessive time and resource consumption. We present a Hybrid Learning orchestration framework that reduces the number of interactions with the system environment by combining model-based and model-free reinforcement learning. Our Deep Learning inference orchestration strategy employs reinforcement learning to find the optimal orchestration policy. Furthermore, we deploy Hybrid Learning (HL) to accelerate the RL learning process and reduce the number of direct samplings. We demonstrate efficacy of our HL strategy through experimental comparison with state-of-the-art RL-based inference orchestration, demonstrating that our HL strategy accelerates the learning process by up to 166.6x.
Online Learning for Orchestration of Inference in Multi-User End-Edge-Cloud Networks
Feb 21, 2022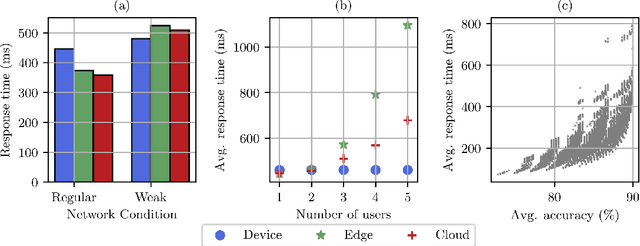

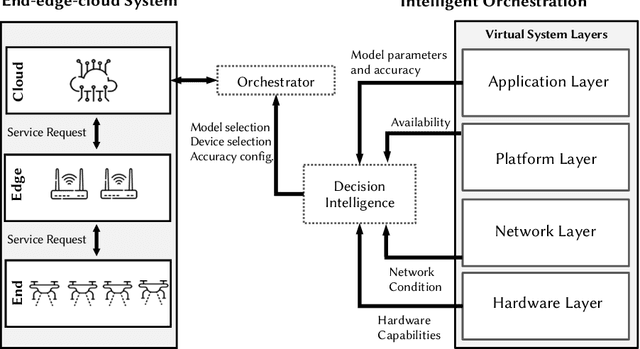

Deep-learning-based intelligent services have become prevalent in cyber-physical applications including smart cities and health-care. Deploying deep-learning-based intelligence near the end-user enhances privacy protection, responsiveness, and reliability. Resource-constrained end-devices must be carefully managed in order to meet the latency and energy requirements of computationally-intensive deep learning services. Collaborative end-edge-cloud computing for deep learning provides a range of performance and efficiency that can address application requirements through computation offloading. The decision to offload computation is a communication-computation co-optimization problem that varies with both system parameters (e.g., network condition) and workload characteristics (e.g., inputs). On the other hand, deep learning model optimization provides another source of tradeoff between latency and model accuracy. An end-to-end decision-making solution that considers such computation-communication problem is required to synergistically find the optimal offloading policy and model for deep learning services. To this end, we propose a reinforcement-learning-based computation offloading solution that learns optimal offloading policy considering deep learning model selection techniques to minimize response time while providing sufficient accuracy. We demonstrate the effectiveness of our solution for edge devices in an end-edge-cloud system and evaluate with a real-setup implementation using multiple AWS and ARM core configurations. Our solution provides 35% speedup in the average response time compared to the state-of-the-art with less than 0.9% accuracy reduction, demonstrating the promise of our online learning framework for orchestrating DL inference in end-edge-cloud systems.
NSML: Meet the MLaaS platform with a real-world case study
Oct 08, 2018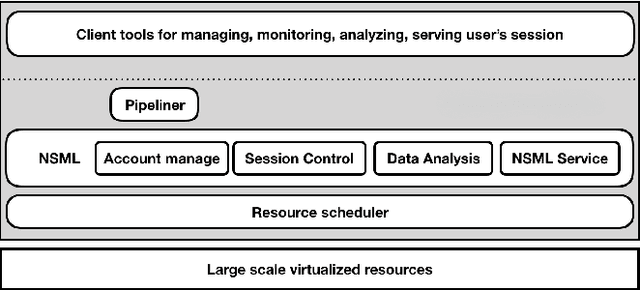
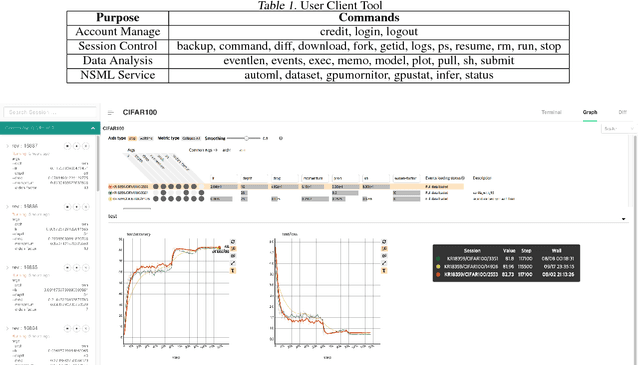
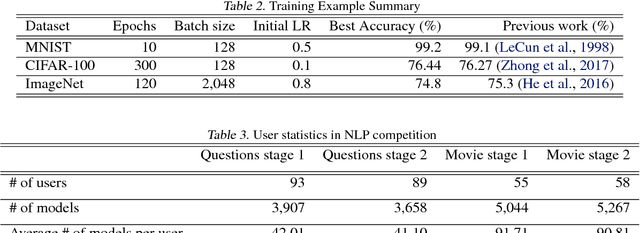
The boom of deep learning induced many industries and academies to introduce machine learning based approaches into their concern, competitively. However, existing machine learning frameworks are limited to sufficiently fulfill the collaboration and management for both data and models. We proposed NSML, a machine learning as a service (MLaaS) platform, to meet these demands. NSML helps machine learning work be easily launched on a NSML cluster and provides a collaborative environment which can afford development at enterprise scale. Finally, NSML users can deploy their own commercial services with NSML cluster. In addition, NSML furnishes convenient visualization tools which assist the users in analyzing their work. To verify the usefulness and accessibility of NSML, we performed some experiments with common examples. Furthermore, we examined the collaborative advantages of NSML through three competitions with real-world use cases.