 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDementiaBank-Emotion: A Multi-Rater Emotion Annotation Corpus for Alzheimer's Disease Speech (Version 1.0)
Feb 04, 2026We present DementiaBank-Emotion, the first multi-rater emotion annotation corpus for Alzheimer's disease (AD) speech. Annotating 1,492 utterances from 108 speakers for Ekman's six basic emotions and neutral, we find that AD patients express significantly more non-neutral emotions (16.9%) than healthy controls (5.7%; p < .001). Exploratory acoustic analysis suggests a possible dissociation: control speakers showed substantial F0 modulation for sadness (Delta = -3.45 semitones from baseline), whereas AD speakers showed minimal change (Delta = +0.11 semitones; interaction p = .023), though this finding is based on limited samples (sadness: n=5 control, n=15 AD) and requires replication. Within AD speech, loudness differentiates emotion categories, indicating partially preserved emotion-prosody mappings. We release the corpus, annotation guidelines, and calibration workshop materials to support research on emotion recognition in clinical populations.
MedSpeak: A Knowledge Graph-Aided ASR Error Correction Framework for Spoken Medical QA
Feb 01, 2026Spoken question-answering (SQA) systems relying on automatic speech recognition (ASR) often struggle with accurately recognizing medical terminology. To this end, we propose MedSpeak, a novel knowledge graph-aided ASR error correction framework that refines noisy transcripts and improves downstream answer prediction by leveraging both semantic relationships and phonetic information encoded in a medical knowledge graph, together with the reasoning power of LLMs. Comprehensive experimental results on benchmarks demonstrate that MedSpeak significantly improves the accuracy of medical term recognition and overall medical SQA performance, establishing MedSpeak as a state-of-the-art solution for medical SQA. The code is available at https://github.com/RainieLLM/MedSpeak.
Styles + Persona-plug = Customized LLMs
Jan 10, 2026We discover a previously overlooked challenge in personalized text generation: personalization methods are increasingly applied under explicit style instructions, yet their behavior under such constraints remains poorly understood. To balance implicit personalization and explicit style, we formulate personalization as a distributional residual and propose PsPLUG, a lightweight soft-prompt plug-in trained with style-conditioned preference contrasts. Across LaMP benchmark, our framework improves persona alignment, maintains stylistic fidelity, and outperforms retrieval-based and soft-prompt baselines with minimal computation. These results show that residual modeling provides a simple and principled foundation for controllable, style-aware LLM personalization.
CARD: Cluster-level Adaptation with Reward-guided Decoding for Personalized Text Generation
Jan 09, 2026Adapting large language models to individual users remains challenging due to the tension between fine-grained personalization and scalable deployment. We present CARD, a hierarchical framework that achieves effective personalization through progressive refinement. CARD first clusters users according to shared stylistic patterns and learns cluster-specific LoRA adapters, enabling robust generalization and strong low-resource performance. To capture individual differences within each cluster, we propose an implicit preference learning mechanism that contrasts user-authored text with cluster-level generations, allowing the model to infer user-specific style preferences without manual annotation. At inference time, CARD injects personalization exclusively at decoding via lightweight user preference vectors and low-rank logit corrections, while keeping the base model frozen. Experiments on the LaMP and LongLaMP benchmarks show that CARD achieves competitive or superior generation quality compared to state-of-the-art baselines, while significantly improving efficiency and scalability for practical personalized text generation.
T-SAR: A Full-Stack Co-design for CPU-Only Ternary LLM Inference via In-Place SIMD ALU Reorganization
Nov 17, 2025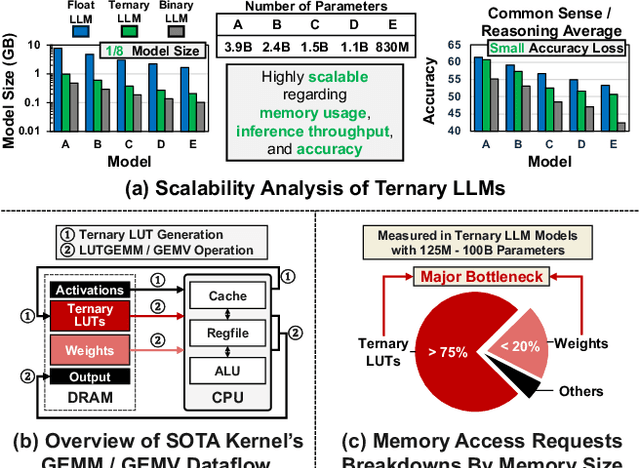
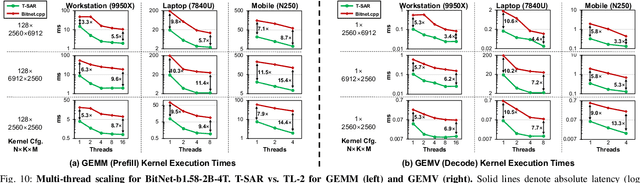
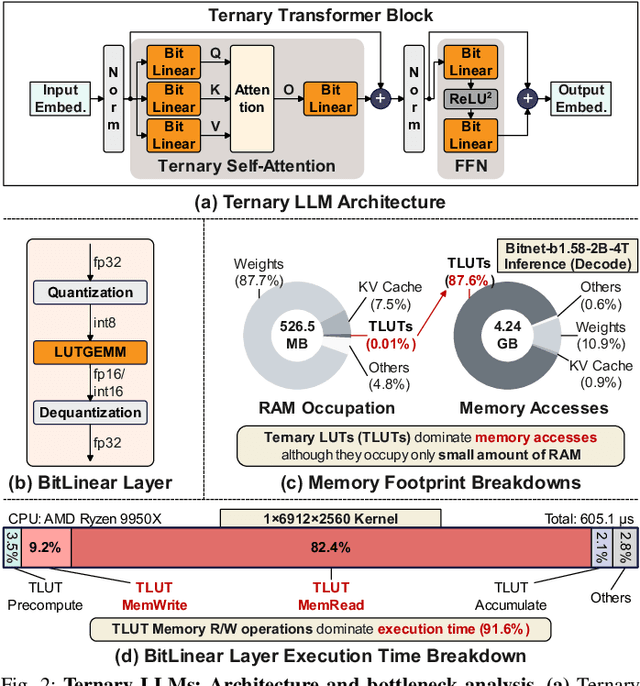
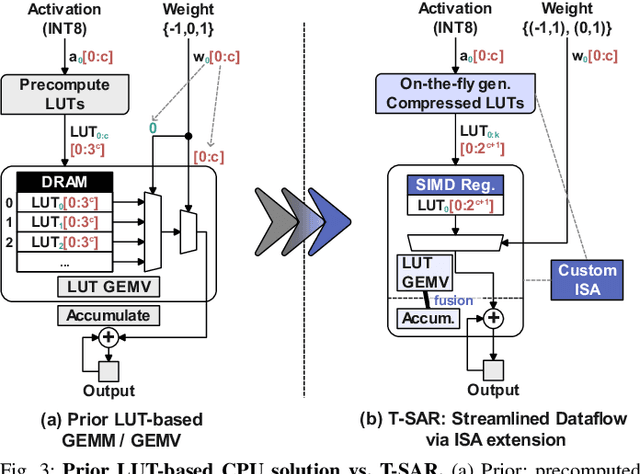
Recent advances in LLMs have outpaced the computational and memory capacities of edge platforms that primarily employ CPUs, thereby challenging efficient and scalable deployment. While ternary quantization enables significant resource savings, existing CPU solutions rely heavily on memory-based lookup tables (LUTs) which limit scalability, and FPGA or GPU accelerators remain impractical for edge use. This paper presents T-SAR, the first framework to achieve scalable ternary LLM inference on CPUs by repurposing the SIMD register file for dynamic, in-register LUT generation with minimal hardware modifications. T-SAR eliminates memory bottlenecks and maximizes data-level parallelism, delivering 5.6-24.5x and 1.1-86.2x improvements in GEMM latency and GEMV throughput, respectively, with only 3.2% power and 1.4% area overheads in SIMD units. T-SAR achieves up to 2.5-4.9x the energy efficiency of an NVIDIA Jetson AGX Orin, establishing a practical approach for efficient LLM inference on edge platforms.
ACCESS-AV: Adaptive Communication-Computation Codesign for Sustainable Autonomous Vehicle Localization in Smart Factories
Jul 27, 2025Autonomous Delivery Vehicles (ADVs) are increasingly used for transporting goods in 5G network-enabled smart factories, with the compute-intensive localization module presenting a significant opportunity for optimization. We propose ACCESS-AV, an energy-efficient Vehicle-to-Infrastructure (V2I) localization framework that leverages existing 5G infrastructure in smart factory environments. By opportunistically accessing the periodically broadcast 5G Synchronization Signal Blocks (SSBs) for localization, ACCESS-AV obviates the need for dedicated Roadside Units (RSUs) or additional onboard sensors to achieve energy efficiency as well as cost reduction. We implement an Angle-of-Arrival (AoA)-based estimation method using the Multiple Signal Classification (MUSIC) algorithm, optimized for resource-constrained ADV platforms through an adaptive communication-computation strategy that dynamically balances energy consumption with localization accuracy based on environmental conditions such as Signal-to-Noise Ratio (SNR) and vehicle velocity. Experimental results demonstrate that ACCESS-AV achieves an average energy reduction of 43.09% compared to non-adaptive systems employing AoA algorithms such as vanilla MUSIC, ESPRIT, and Root-MUSIC. It maintains sub-30 cm localization accuracy while also delivering substantial reductions in infrastructure and operational costs, establishing its viability for sustainable smart factory environments.
DEMENTIA-PLAN: An Agent-Based Framework for Multi-Knowledge Graph Retrieval-Augmented Generation in Dementia Care
Mar 26, 2025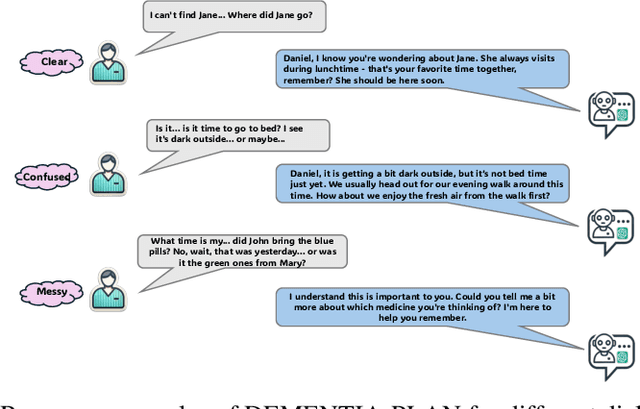

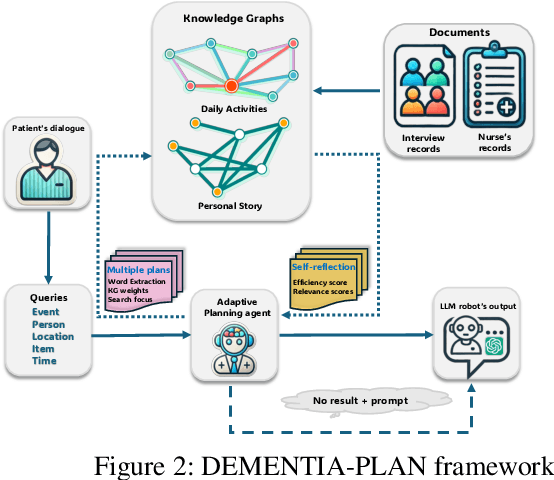

Mild-stage dementia patients primarily experience two critical symptoms: severe memory loss and emotional instability. To address these challenges, we propose DEMENTIA-PLAN, an innovative retrieval-augmented generation framework that leverages large language models to enhance conversational support. Our model employs a multiple knowledge graph architecture, integrating various dimensional knowledge representations including daily routine graphs and life memory graphs. Through this multi-graph architecture, DEMENTIA-PLAN comprehensively addresses both immediate care needs and facilitates deeper emotional resonance through personal memories, helping stabilize patient mood while providing reliable memory support. Our notable innovation is the self-reflection planning agent, which systematically coordinates knowledge retrieval and semantic integration across multiple knowledge graphs, while scoring retrieved content from daily routine and life memory graphs to dynamically adjust their retrieval weights for optimized response generation. DEMENTIA-PLAN represents a significant advancement in the clinical application of large language models for dementia care, bridging the gap between AI tools and caregivers interventions.
Enhancing Performance and User Engagement in Everyday Stress Monitoring: A Context-Aware Active Reinforcement Learning Approach
Jul 11, 2024



In today's fast-paced world, accurately monitoring stress levels is crucial. Sensor-based stress monitoring systems often need large datasets for training effective models. However, individual-specific models are necessary for personalized and interactive scenarios. Traditional methods like Ecological Momentary Assessments (EMAs) assess stress but struggle with efficient data collection without burdening users. The challenge is to timely send EMAs, especially during stress, balancing monitoring efficiency and user convenience. This paper introduces a novel context-aware active reinforcement learning (RL) algorithm for enhanced stress detection using Photoplethysmography (PPG) data from smartwatches and contextual data from smartphones. Our approach dynamically selects optimal times for deploying EMAs, utilizing the user's immediate context to maximize label accuracy and minimize intrusiveness. Initially, the study was executed in an offline environment to refine the label collection process, aiming to increase accuracy while reducing user burden. Later, we integrated a real-time label collection mechanism, transitioning to an online methodology. This shift resulted in an 11% improvement in stress detection efficiency. Incorporating contextual data improved model accuracy by 4%. Personalization studies indicated a 10% enhancement in AUC-ROC scores, demonstrating better stress level differentiation. This research marks a significant move towards personalized, context-driven real-time stress monitoring methods.
MUSIC-lite: Efficient MUSIC using Approximate Computing: An OFDM Radar Case Study
Jul 05, 2024Multiple Signal Classification (MUSIC) is a widely used Direction of Arrival (DoA)/Angle of Arrival (AoA) estimation algorithm applied to various application domains such as autonomous driving, medical imaging, and astronomy. However, MUSIC is computationally expensive and challenging to implement in low-power hardware, requiring exploration of trade-offs between accuracy, cost, and power. We present MUSIC-lite, which exploits approximate computing to generate a design space exploring accuracy-area-power trade-offs. This is specifically applied to the computationally intensive singular value decomposition (SVD) component of the MUSIC algorithm in an orthogonal frequency-division multiplexing (OFDM) radar use case. MUSIC-lite incorporates approximate adders into the iterative CORDIC algorithm that is used for hardware implementation of MUSIC, generating interesting accuracy-area-power trade-offs. Our experiments demonstrate MUSIC-lite's ability to save an average of 17.25% on-chip area and 19.4% power with a minimal 0.14% error for efficient MUSIC implementations.
Integrating Wearable Sensor Data and Self-reported Diaries for Personalized Affect Forecasting
Mar 23, 2024



Emotional states, as indicators of affect, are pivotal to overall health, making their accurate prediction before onset crucial. Current studies are primarily centered on immediate short-term affect detection using data from wearable and mobile devices. These studies typically focus on objective sensory measures, often neglecting other forms of self-reported information like diaries and notes. In this paper, we propose a multimodal deep learning model for affect status forecasting. This model combines a transformer encoder with a pre-trained language model, facilitating the integrated analysis of objective metrics and self-reported diaries. To validate our model, we conduct a longitudinal study, enrolling college students and monitoring them over a year, to collect an extensive dataset including physiological, environmental, sleep, metabolic, and physical activity parameters, alongside open-ended textual diaries provided by the participants. Our results demonstrate that the proposed model achieves predictive accuracy of 82.50% for positive affect and 82.76% for negative affect, a full week in advance. The effectiveness of our model is further elevated by its explainability.