 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Performance and User Engagement in Everyday Stress Monitoring: A Context-Aware Active Reinforcement Learning Approach
Jul 11, 2024



In today's fast-paced world, accurately monitoring stress levels is crucial. Sensor-based stress monitoring systems often need large datasets for training effective models. However, individual-specific models are necessary for personalized and interactive scenarios. Traditional methods like Ecological Momentary Assessments (EMAs) assess stress but struggle with efficient data collection without burdening users. The challenge is to timely send EMAs, especially during stress, balancing monitoring efficiency and user convenience. This paper introduces a novel context-aware active reinforcement learning (RL) algorithm for enhanced stress detection using Photoplethysmography (PPG) data from smartwatches and contextual data from smartphones. Our approach dynamically selects optimal times for deploying EMAs, utilizing the user's immediate context to maximize label accuracy and minimize intrusiveness. Initially, the study was executed in an offline environment to refine the label collection process, aiming to increase accuracy while reducing user burden. Later, we integrated a real-time label collection mechanism, transitioning to an online methodology. This shift resulted in an 11% improvement in stress detection efficiency. Incorporating contextual data improved model accuracy by 4%. Personalization studies indicated a 10% enhancement in AUC-ROC scores, demonstrating better stress level differentiation. This research marks a significant move towards personalized, context-driven real-time stress monitoring methods.
Active Reinforcement Learning for Personalized Stress Monitoring in Everyday Settings
Apr 28, 2023



Most existing sensor-based monitoring frameworks presume that a large available labeled dataset is processed to train accurate detection models. However, in settings where personalization is necessary at deployment time to fine-tune the model, a person-specific dataset needs to be collected online by interacting with the users. Optimizing the collection of labels in such phase is instrumental to impose a tolerable burden on the users while maximizing personal improvement. In this paper, we consider a fine-grain stress detection problem based on wearable sensors targeting everyday settings, and propose a novel context-aware active learning strategy capable of jointly maximizing the meaningfulness of the signal samples we request the user to label and the response rate. We develop a multilayered sensor-edge-cloud platform to periodically capture physiological signals and process them in real-time, as well as to collect labels and retrain the detection model. We collect a large dataset and show that the context-aware active learning technique we propose achieves a desirable detection performance using 88\% and 32\% fewer queries from users compared to a randomized strategy and a traditional active learning strategy, respectively.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Data Collection and Labeling of Real-Time IoT-Enabled Bio-Signals in Everyday Settings for Mental Health Improvement
Aug 02, 2021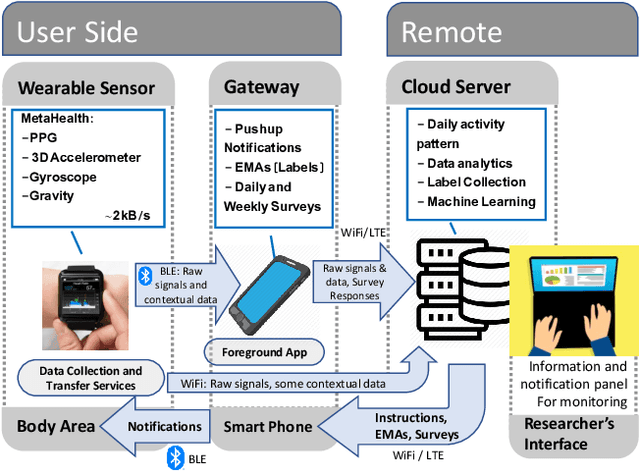
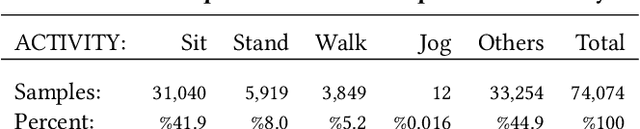
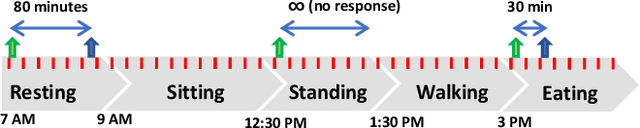

Real-time physiological data collection and analysis play a central role in modern well-being applications. Personalized classifiers and detectors have been shown to outperform general classifiers in many contexts. However, building effective personalized classifiers in everyday settings - as opposed to controlled settings - necessitates the online collection of a labeled dataset by interacting with the user. This need leads to several challenges, ranging from building an effective system for the collection of the signals and labels, to developing strategies to interact with the user and building a dataset that represents the many user contexts that occur in daily life. Based on a stress detection use case, this paper (1) builds a system for the real-time collection and analysis of photoplethysmogram, acceleration, gyroscope, and gravity data from a wearable sensor, as well as self-reported stress labels based on Ecological Momentary Assessment (EMA), and (2) collects and analyzes a dataset to extract statistics of users' response to queries and the quality of the collected signals as a function of the context, here defined as the user's activity and the time of the day.
Personalized Stress Monitoring using Wearable Sensors in Everyday Settings
Jul 31, 2021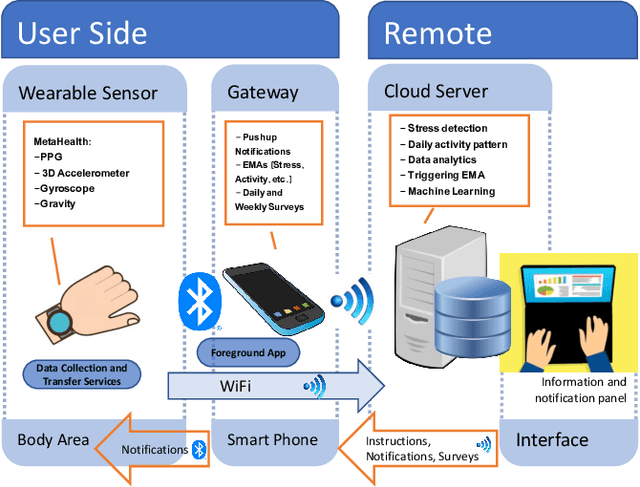
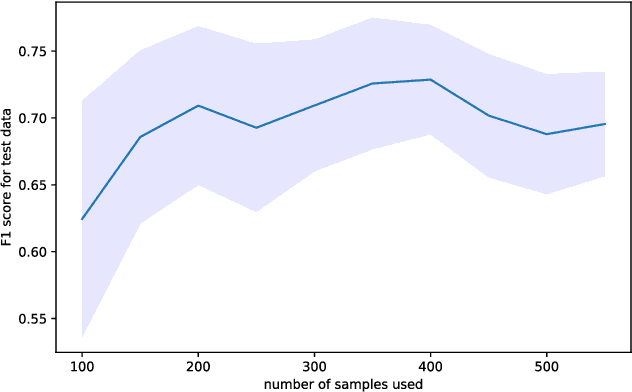
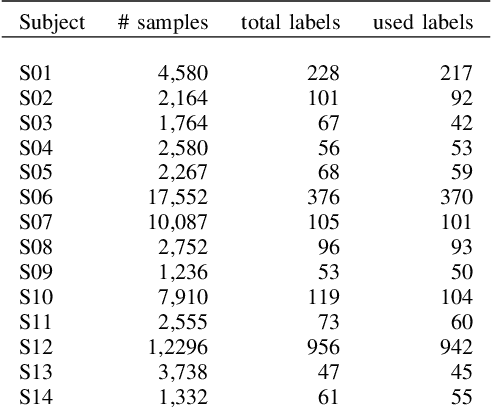

Since stress contributes to a broad range of mental and physical health problems, the objective assessment of stress is essential for behavioral and physiological studies. Although several studies have evaluated stress levels in controlled settings, objective stress assessment in everyday settings is still largely under-explored due to challenges arising from confounding contextual factors and limited adherence for self-reports. In this paper, we explore the objective prediction of stress levels in everyday settings based on heart rate (HR) and heart rate variability (HRV) captured via low-cost and easy-to-wear photoplethysmography (PPG) sensors that are widely available on newer smart wearable devices. We present a layered system architecture for personalized stress monitoring that supports a tunable collection of data samples for labeling, and present a method for selecting informative samples from the stream of real-time data for labeling. We captured the stress levels of fourteen volunteers through self-reported questionnaires over periods of between 1-3 months, and explored binary stress detection based on HR and HRV using Machine Learning Methods. We observe promising preliminary results given that the dataset is collected in the challenging environments of everyday settings. The binary stress detector is fairly accurate and can detect stressful vs non-stressful samples with a macro-F1 score of up to \%76. Our study lays the groundwork for more sophisticated labeling strategies that generate context-aware, personalized models that will empower health professionals to provide personalized interventions.
A Deep Learning Approach to Predict Blood Pressure from PPG Signals
Jul 30, 2021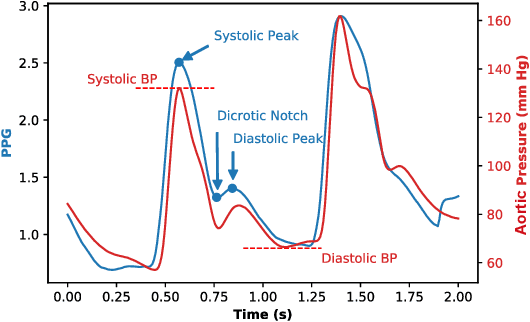
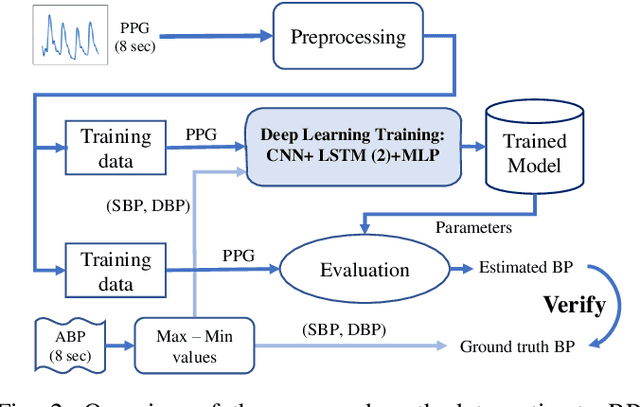
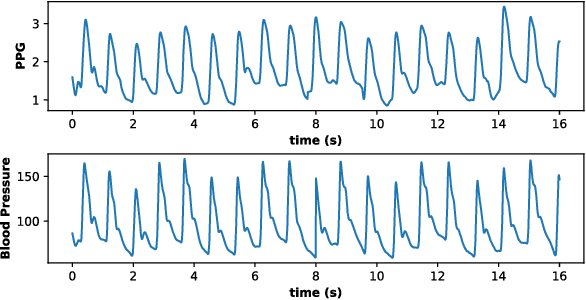
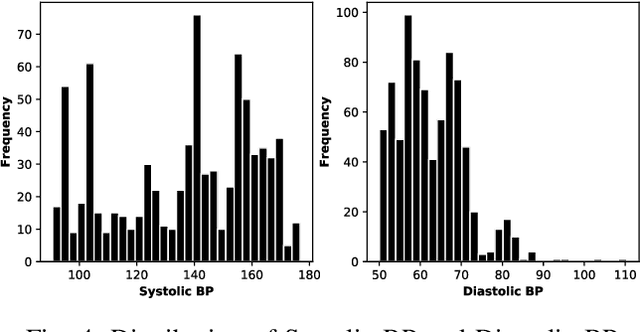
Blood Pressure (BP) is one of the four primary vital signs indicating the status of the body's vital (life-sustaining) functions. BP is difficult to continuously monitor using a sphygmomanometer (i.e. a blood pressure cuff), especially in everyday-setting. However, other health signals which can be easily and continuously acquired, such as photoplethysmography (PPG), show some similarities with the Aortic Pressure waveform. Based on these similarities, in recent years several methods were proposed to predict BP from the PPG signal. Building on these results, we propose an advanced personalized data-driven approach that uses a three-layer deep neural network to estimate BP based on PPG signals. Different from previous work, the proposed model analyzes the PPG signal in time-domain and automatically extracts the most critical features for this specific application, then uses a variation of recurrent neural networks called Long-Short-Term-Memory (LSTM) to map the extracted features to the BP value associated with that time window. Experimental results on two separate standard hospital datasets, yielded absolute errors mean and absolute error standard deviation for systolic and diastolic BP values outperforming prior works.
ParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
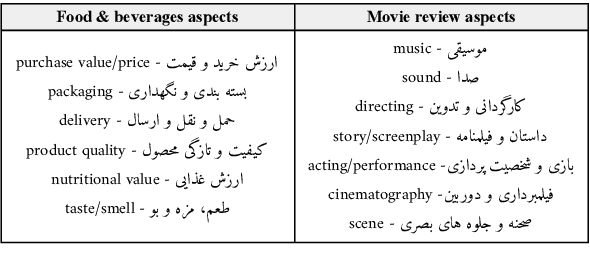
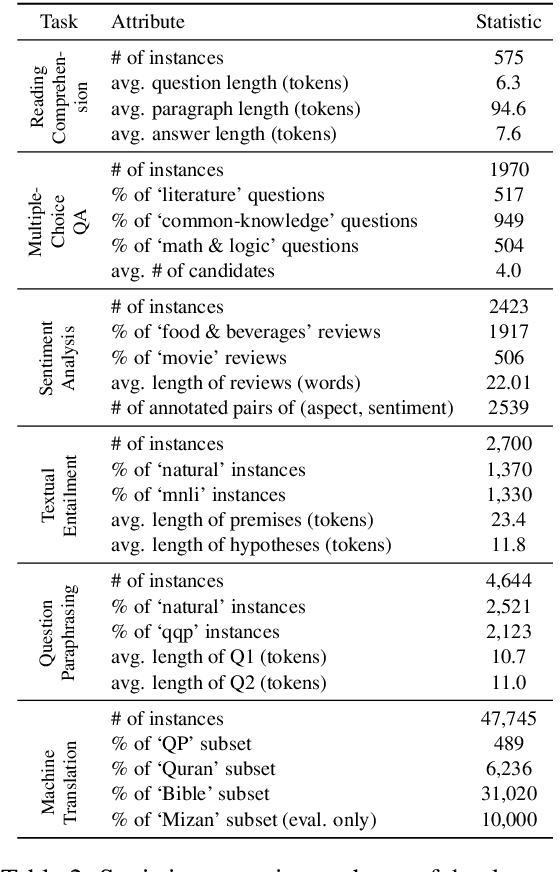
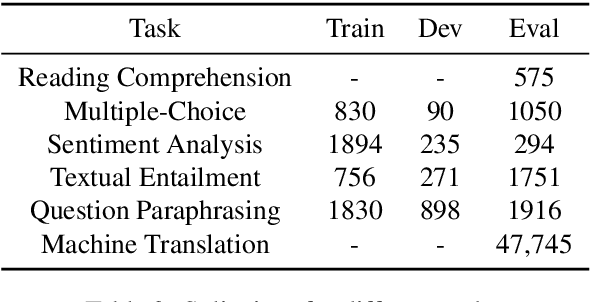
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.