 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialect Matters: Cross-Lingual ASR Transfer for Low-Resource Indic Language Varieties
Jan 07, 2026We conduct an empirical study of cross-lingual transfer using spontaneous, noisy, and code-mixed speech across a wide range of Indic dialects and language varieties. Our results indicate that although ASR performance is generally improved with reduced phylogenetic distance between languages, this factor alone does not fully explain performance in dialectal settings. Often, fine-tuning on smaller amounts of dialectal data yields performance comparable to fine-tuning on larger amounts of phylogenetically-related, high-resource standardized languages. We also present a case study on Garhwali, a low-resource Pahari language variety, and evaluate multiple contemporary ASR models. Finally, we analyze transcription errors to examine bias toward pre-training languages, providing additional insight into challenges faced by ASR systems on dialectal and non-standardized speech.
We're Calling an Intervention: Taking a Closer Look at Language Model Adaptation to Different Types of Linguistic Variation
Apr 10, 2024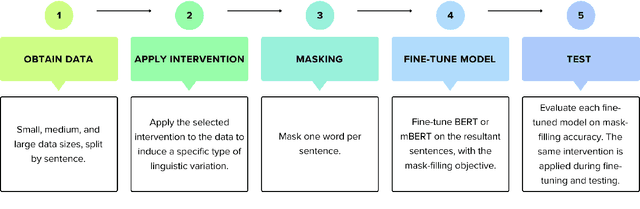
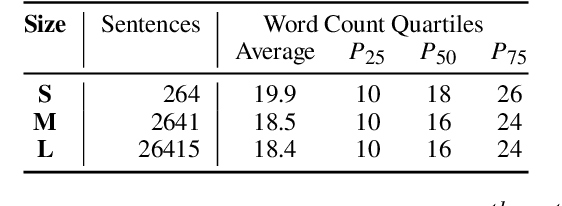

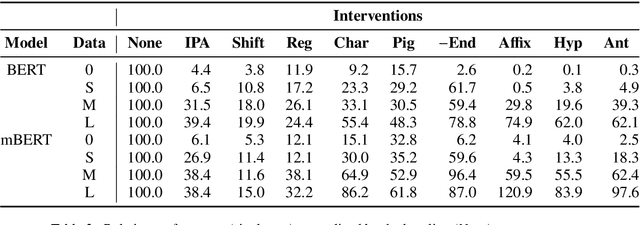
We present a suite of interventions and experiments that allow us to understand language model adaptation to text with linguistic variation (e.g., nonstandard or dialectal text). Our interventions address several features of linguistic variation, resulting in character, subword, and word-level changes. Applying our interventions during language model adaptation with varying size and nature of training data, we gain important insights into what makes linguistic variation particularly difficult for language models to deal with. For instance, on text with character-level variation, performance improves with even a few training examples but approaches a plateau, suggesting that more data is not the solution. In contrast, on text with variation involving new words or meanings, far more data is needed, but it leads to a massive breakthrough in performance. Our findings inform future work on dialectal NLP and making language models more robust to linguistic variation overall. We make the code for our interventions, which can be applied to any English text data, publicly available.
DIALECTBENCH: A NLP Benchmark for Dialects, Varieties, and Closely-Related Languages
Mar 16, 2024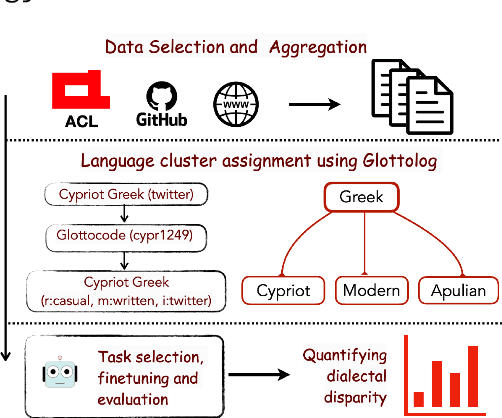
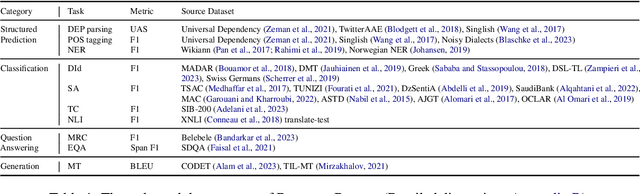
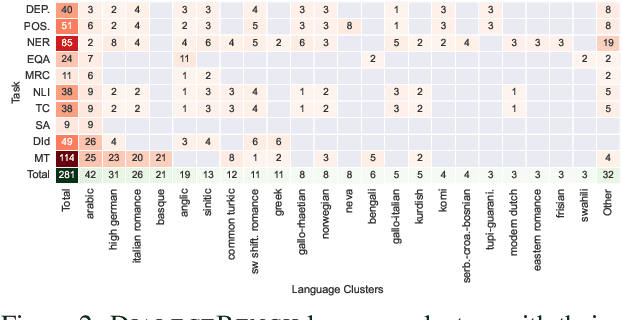

Language technologies should be judged on their usefulness in real-world use cases. An often overlooked aspect in natural language processing (NLP) research and evaluation is language variation in the form of non-standard dialects or language varieties (hereafter, varieties). Most NLP benchmarks are limited to standard language varieties. To fill this gap, we propose DIALECTBENCH, the first-ever large-scale benchmark for NLP on varieties, which aggregates an extensive set of task-varied variety datasets (10 text-level tasks covering 281 varieties). This allows for a comprehensive evaluation of NLP system performance on different language varieties. We provide substantial evidence of performance disparities between standard and non-standard language varieties, and we also identify language clusters with large performance divergence across tasks. We believe DIALECTBENCH provides a comprehensive view of the current state of NLP for language varieties and one step towards advancing it further. Code/data: https://github.com/ffaisal93/DialectBench
BERTwich: Extending BERT's Capabilities to Model Dialectal and Noisy Text
Oct 31, 2023Real-world NLP applications often deal with nonstandard text (e.g., dialectal, informal, or misspelled text). However, language models like BERT deteriorate in the face of dialect variation or noise. How do we push BERT's modeling capabilities to encompass nonstandard text? Fine-tuning helps, but it is designed for specializing a model to a task and does not seem to bring about the deeper, more pervasive changes needed to adapt a model to nonstandard language. In this paper, we introduce the novel idea of sandwiching BERT's encoder stack between additional encoder layers trained to perform masked language modeling on noisy text. We find that our approach, paired with recent work on including character-level noise in fine-tuning data, can promote zero-shot transfer to dialectal text, as well as reduce the distance in the embedding space between words and their noisy counterparts.
Fine-Tuning BERT with Character-Level Noise for Zero-Shot Transfer to Dialects and Closely-Related Languages
Mar 30, 2023In this work, we induce character-level noise in various forms when fine-tuning BERT to enable zero-shot cross-lingual transfer to unseen dialects and languages. We fine-tune BERT on three sentence-level classification tasks and evaluate our approach on an assortment of unseen dialects and languages. We find that character-level noise can be an extremely effective agent of cross-lingual transfer under certain conditions, while it is not as helpful in others. Specifically, we explore these differences in terms of the nature of the task and the relationships between source and target languages, finding that introduction of character-level noise during fine-tuning is particularly helpful when a task draws on surface level cues and the source-target cross-lingual pair has a relatively high lexical overlap with shorter (i.e., less meaningful) unseen tokens on average.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.