 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDIOLEX: Unified and Continuous Representations for Idiolectal and Stylistic Variation
Apr 06, 2026Existing sentence representations primarily encode what a sentence says, rather than how it is expressed, even though the latter is important for many applications. In contrast, we develop sentence representations that capture style and dialect, decoupled from semantic content. We call this the task of idiolectal representation learning. We introduce IDIOLEX, a framework for training models that combines supervision from a sentence's provenance with linguistic features of a sentence's content, to learn a continuous representation of each sentence's style and dialect. We evaluate the approach on dialects of both Arabic and Spanish. The learned representations capture meaningful variation and transfer across domains for analysis and classification. We further explore the use of these representations as training objectives for stylistically aligning language models. Our results suggest that jointly modeling individual and community-level variation provides a useful perspective for studying idiolect and supports downstream applications requiring sensitivity to stylistic differences, such as developing diverse and accessible LLMs.
Automatic Speech Recognition for Documenting Endangered Languages: Case Study of Ikema Miyakoan
Mar 27, 2026Language endangerment poses a major challenge to linguistic diversity worldwide, and technological advances have opened new avenues for documentation and revitalization. Among these, automatic speech recognition (ASR) has shown increasing potential to assist in the transcription of endangered language data. This study focuses on Ikema, a severely endangered Ryukyuan language spoken in Okinawa, Japan, with approximately 1,300 remaining speakers, most of whom are over 60 years old. We present an ongoing effort to develop an ASR system for Ikema based on field recordings. Specifically, we (1) construct a {\totaldatasethours}-hour speech corpus from field recordings, (2) train an ASR model that achieves a character error rate as low as 15\%, and (3) evaluate the impact of ASR assistance on the efficiency of speech transcription. Our results demonstrate that ASR integration can substantially reduce transcription time and cognitive load, offering a practical pathway toward scalable, technology-supported documentation of endangered languages.
Dialect Matters: Cross-Lingual ASR Transfer for Low-Resource Indic Language Varieties
Jan 07, 2026We conduct an empirical study of cross-lingual transfer using spontaneous, noisy, and code-mixed speech across a wide range of Indic dialects and language varieties. Our results indicate that although ASR performance is generally improved with reduced phylogenetic distance between languages, this factor alone does not fully explain performance in dialectal settings. Often, fine-tuning on smaller amounts of dialectal data yields performance comparable to fine-tuning on larger amounts of phylogenetically-related, high-resource standardized languages. We also present a case study on Garhwali, a low-resource Pahari language variety, and evaluate multiple contemporary ASR models. Finally, we analyze transcription errors to examine bias toward pre-training languages, providing additional insight into challenges faced by ASR systems on dialectal and non-standardized speech.
Probability Distributions Computed by Hard-Attention Transformers
Oct 31, 2025
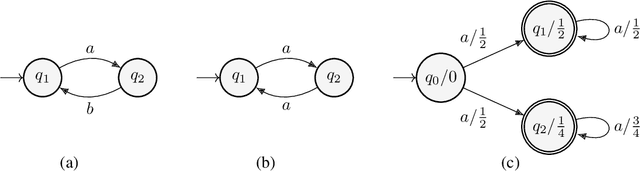
Most expressivity results for transformers treat them as language recognizers (which accept or reject strings), and not as they are used in practice, as language models (which generate strings autoregressively and probabilistically). Here, we characterize the probability distributions that transformer language models can express. We show that making transformer language recognizers autoregressive can sometimes increase their expressivity, and that making them probabilistic can break equivalences that hold in the non-probabilistic case. Our overall contribution is to tease apart what functions transformers are capable of expressing, in their most common use-case as language models.
Frustratingly Easy Data Augmentation for Low-Resource ASR
Sep 18, 2025This paper introduces three self-contained data augmentation methods for low-resource Automatic Speech Recognition (ASR). Our techniques first generate novel text--using gloss-based replacement, random replacement, or an LLM-based approach--and then apply Text-to-Speech (TTS) to produce synthetic audio. We apply these methods, which leverage only the original annotated data, to four languages with extremely limited resources (Vatlongos, Nashta, Shinekhen Buryat, and Kakabe). Fine-tuning a pretrained Wav2Vec2-XLSR-53 model on a combination of the original audio and generated synthetic data yields significant performance gains, including a 14.3% absolute WER reduction for Nashta. The methods prove effective across all four low-resource languages and also show utility for high-resource languages like English, demonstrating their broad applicability.
Using Source-Side Confidence Estimation for Reliable Translation into Unfamiliar Languages
Mar 30, 2025



We present an interactive machine translation (MT) system designed for users who are not proficient in the target language. It aims to improve trustworthiness and explainability by identifying potentially mistranslated words and allowing the user to intervene to correct mistranslations. However, confidence estimation in machine translation has traditionally focused on the target side. Whereas the conventional approach to source-side confidence estimation would have been to project target word probabilities to the source side via word alignments, we propose a direct, alignment-free approach that measures how sensitive the target word probabilities are to changes in the source embeddings. Experimental results show that our method outperforms traditional alignment-based methods at detection of mistranslations.
Simulating Hard Attention Using Soft Attention
Dec 13, 2024

We study conditions under which transformers using soft attention can simulate hard attention, that is, effectively focus all attention on a subset of positions. First, we examine several variants of linear temporal logic, whose formulas have been previously been shown to be computable using hard attention transformers. We demonstrate how soft attention transformers can compute formulas of these logics using unbounded positional embeddings or temperature scaling. Second, we demonstrate how temperature scaling allows softmax transformers to simulate a large subclass of average-hard attention transformers, those that have what we call the uniform-tieless property.
Improving Rare Word Translation With Dictionaries and Attention Masking
Aug 17, 2024



In machine translation, rare words continue to be a problem for the dominant encoder-decoder architecture, especially in low-resource and out-of-domain translation settings. Human translators solve this problem with monolingual or bilingual dictionaries. In this paper, we propose appending definitions from a bilingual dictionary to source sentences and using attention masking to link together rare words with their definitions. We find that including definitions for rare words improves performance by up to 1.0 BLEU and 1.6 MacroF1.
Language Complexity and Speech Recognition Accuracy: Orthographic Complexity Hurts, Phonological Complexity Doesn't
Jun 13, 2024



We investigate what linguistic factors affect the performance of Automatic Speech Recognition (ASR) models. We hypothesize that orthographic and phonological complexities both degrade accuracy. To examine this, we fine-tune the multilingual self-supervised pretrained model Wav2Vec2-XLSR-53 on 25 languages with 15 writing systems, and we compare their ASR accuracy, number of graphemes, unigram grapheme entropy, logographicity (how much word/morpheme-level information is encoded in the writing system), and number of phonemes. The results demonstrate that orthographic complexities significantly correlate with low ASR accuracy, while phonological complexity shows no significant correlation.
PILA: A Historical-Linguistic Dataset of Proto-Italic and Latin
Apr 25, 2024Computational historical linguistics seeks to systematically understand processes of sound change, including during periods at which little to no formal recording of language is attested. At the same time, few computational resources exist which deeply explore phonological and morphological connections between proto-languages and their descendants. This is particularly true for the family of Italic languages. To assist historical linguists in the study of Italic sound change, we introduce the Proto-Italic to Latin (PILA) dataset, which consists of roughly 3,000 pairs of forms from Proto-Italic and Latin. We provide a detailed description of how our dataset was created and organized. Then, we exhibit PILA's value in two ways. First, we present baseline results for PILA on a pair of traditional computational historical linguistics tasks. Second, we demonstrate PILA's capability for enhancing other historical-linguistic datasets through a dataset compatibility study.