 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe're Calling an Intervention: Taking a Closer Look at Language Model Adaptation to Different Types of Linguistic Variation
Paper and Code
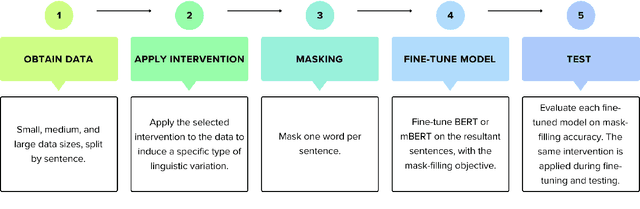
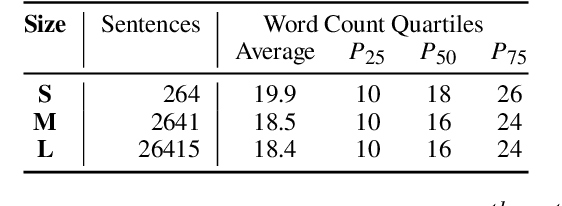

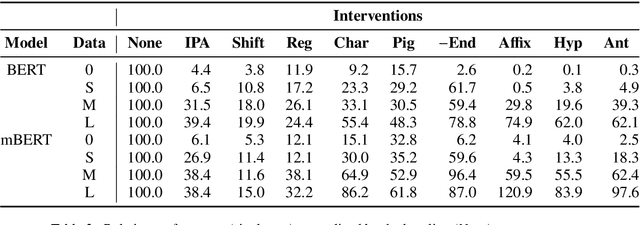
We present a suite of interventions and experiments that allow us to understand language model adaptation to text with linguistic variation (e.g., nonstandard or dialectal text). Our interventions address several features of linguistic variation, resulting in character, subword, and word-level changes. Applying our interventions during language model adaptation with varying size and nature of training data, we gain important insights into what makes linguistic variation particularly difficult for language models to deal with. For instance, on text with character-level variation, performance improves with even a few training examples but approaches a plateau, suggesting that more data is not the solution. In contrast, on text with variation involving new words or meanings, far more data is needed, but it leads to a massive breakthrough in performance. Our findings inform future work on dialectal NLP and making language models more robust to linguistic variation overall. We make the code for our interventions, which can be applied to any English text data, publicly available.