 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability Distributions Computed by Hard-Attention Transformers
Oct 31, 2025
Most expressivity results for transformers treat them as language recognizers (which accept or reject strings), and not as they are used in practice, as language models (which generate strings autoregressively and probabilistically). Here, we characterize the probability distributions that transformer language models can express. We show that making transformer language recognizers autoregressive can sometimes increase their expressivity, and that making them probabilistic can break equivalences that hold in the non-probabilistic case. Our overall contribution is to tease apart what functions transformers are capable of expressing, in their most common use-case as language models.
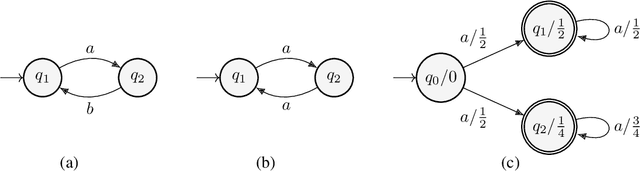
Transformers as Transducers
Apr 02, 2024We study the sequence-to-sequence mapping capacity of transformers by relating them to finite transducers, and find that they can express surprisingly large classes of transductions. We do so using variants of RASP, a programming language designed to help people "think like transformers," as an intermediate representation. We extend the existing Boolean variant B-RASP to sequence-to-sequence functions and show that it computes exactly the first-order rational functions (such as string rotation). Then, we introduce two new extensions. B-RASP[pos] enables calculations on positions (such as copying the first half of a string) and contains all first-order regular functions. S-RASP adds prefix sum, which enables additional arithmetic operations (such as squaring a string) and contains all first-order polyregular functions. Finally, we show that masked average-hard attention transformers can simulate S-RASP. A corollary of our results is a new proof that transformer decoders are Turing-complete.
Learning Transductions to Test Systematic Compositionality
Aug 17, 2022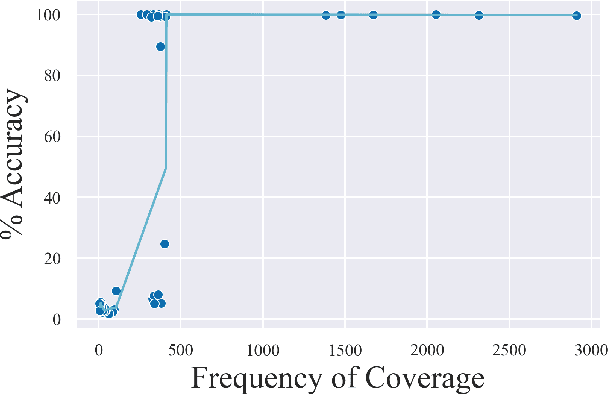
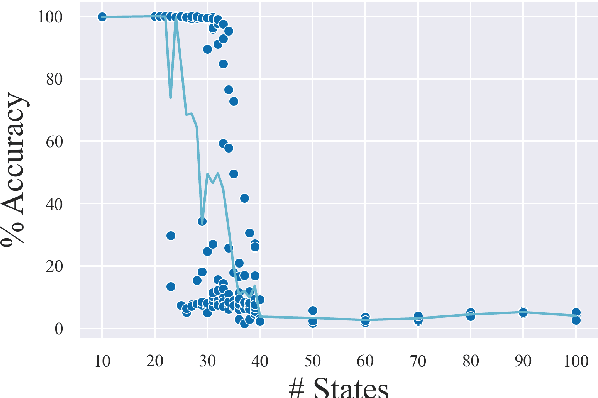

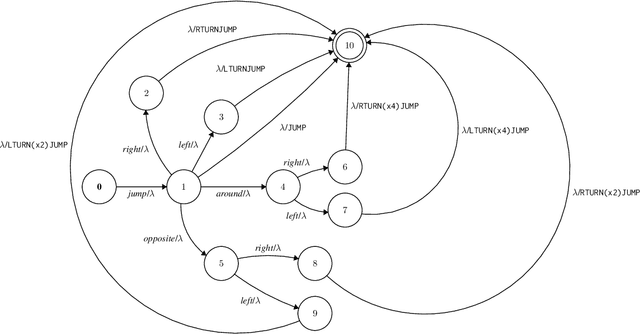
Recombining known primitive concepts into larger novel combinations is a quintessentially human cognitive capability. Whether large neural models in NLP acquire this ability while learning from data is an open question. In this paper, we look at this problem from the perspective of formal languages. We use deterministic finite-state transducers to make an unbounded number of datasets with controllable properties governing compositionality. By randomly sampling over many transducers, we explore which of their properties (number of states, alphabet size, number of transitions etc.) contribute to learnability of a compositional relation by a neural network. In general, we find that the models either learn the relations completely or not at all. The key is transition coverage, setting a soft learnability limit at 400 examples per transition.
Learning with Partially Ordered Representations
Jun 23, 2019
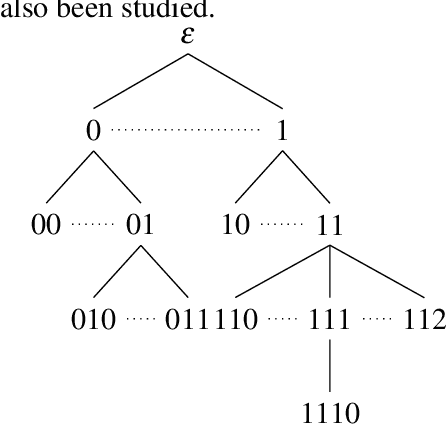
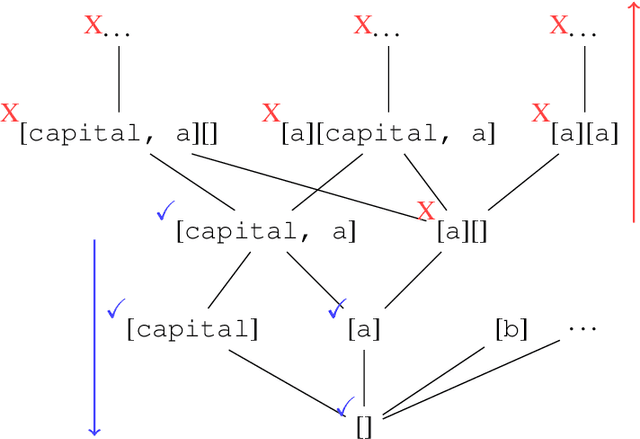
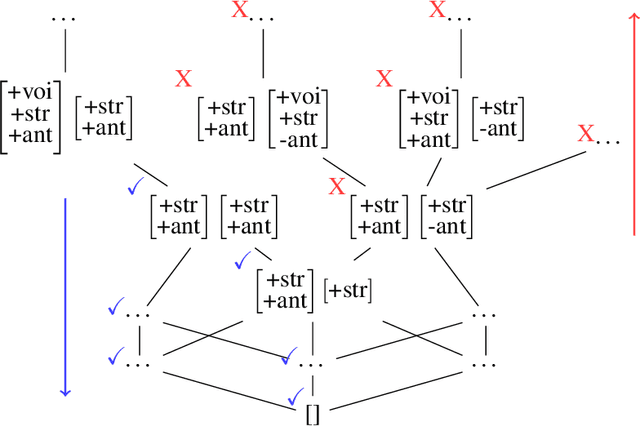
This paper examines the characterization and learning of grammars defined with enriched representational models. Model-theoretic approaches to formal language theory traditionally assume that each position in a string belongs to exactly one unary relation. We consider unconventional string models where positions can have multiple, shared properties, which are arguably useful in many applications. We show the structures given by these models are partially ordered, and present a learning algorithm that exploits this ordering relation to effectively prune the hypothesis space. We prove this learning algorithm, which takes positive examples as input, finds the most general grammar which covers the data.