 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Linguistics Will Thrive in the 21st Century: A Reply to Piantadosi
Aug 06, 2023
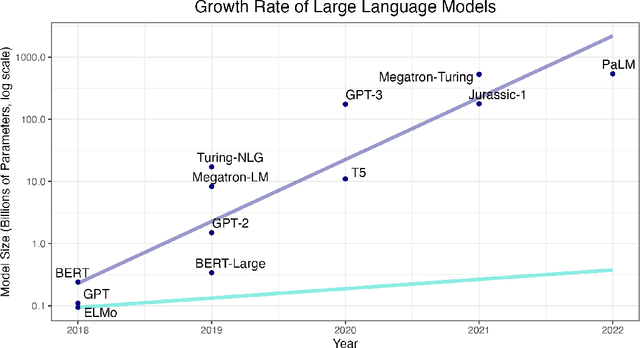
We present a critical assessment of Piantadosi's (2023) claim that "Modern language models refute Chomsky's approach to language," focusing on four main points. First, despite the impressive performance and utility of large language models (LLMs), humans achieve their capacity for language after exposure to several orders of magnitude less data. The fact that young children become competent, fluent speakers of their native languages with relatively little exposure to them is the central mystery of language learning to which Chomsky initially drew attention, and LLMs currently show little promise of solving this mystery. Second, what can the artificial reveal about the natural? Put simply, the implications of LLMs for our understanding of the cognitive structures and mechanisms underlying language and its acquisition are like the implications of airplanes for understanding how birds fly. Third, LLMs cannot constitute scientific theories of language for several reasons, not least of which is that scientific theories must provide interpretable explanations, not just predictions. This leads to our final point: to even determine whether the linguistic and cognitive capabilities of LLMs rival those of humans requires explicating what humans' capacities actually are. In other words, it requires a separate theory of language and cognition; generative linguistics provides precisely such a theory. As such, we conclude that generative linguistics as a scientific discipline will remain indispensable throughout the 21st century and beyond.
MLRegTest: A Benchmark for the Machine Learning of Regular Languages
Apr 16, 2023
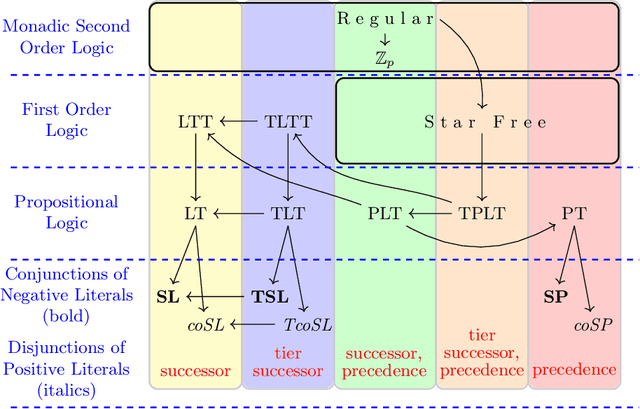
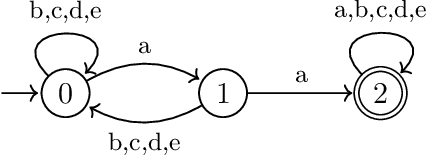
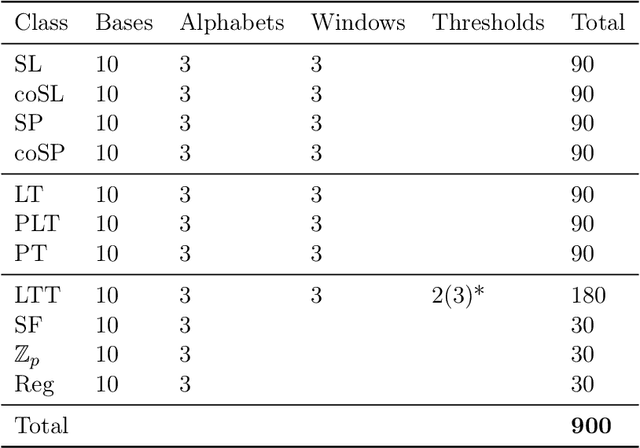
Evaluating machine learning (ML) systems on their ability to learn known classifiers allows fine-grained examination of the patterns they can learn, which builds confidence when they are applied to the learning of unknown classifiers. This article presents a new benchmark for ML systems on sequence classification called MLRegTest, which contains training, development, and test sets from 1,800 regular languages. Different kinds of formal languages represent different kinds of long-distance dependencies, and correctly identifying long-distance dependencies in sequences is a known challenge for ML systems to generalize successfully. MLRegTest organizes its languages according to their logical complexity (monadic second order, first order, propositional, or monomial expressions) and the kind of logical literals (string, tier-string, subsequence, or combinations thereof). The logical complexity and choice of literal provides a systematic way to understand different kinds of long-distance dependencies in regular languages, and therefore to understand the capacities of different ML systems to learn such long-distance dependencies. Finally, the performance of different neural networks (simple RNN, LSTM, GRU, transformer) on MLRegTest is examined. The main conclusion is that their performance depends significantly on the kind of test set, the class of language, and the neural network architecture.
The SIGMORPHON 2019 Shared Task: Morphological Analysis in Context and Cross-Lingual Transfer for Inflection
Oct 25, 2019
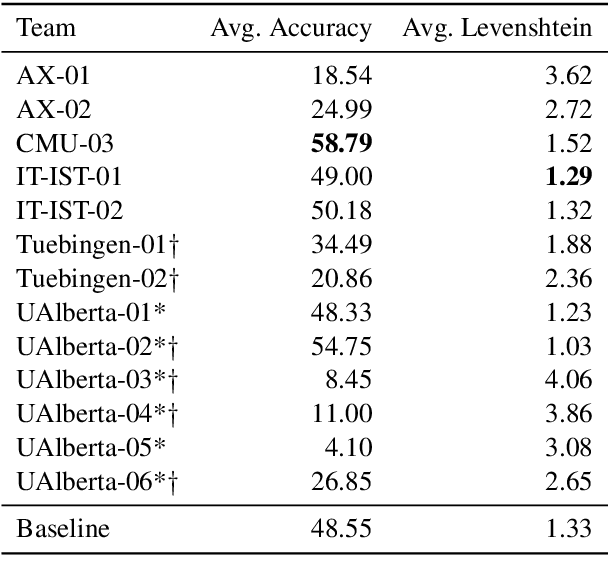
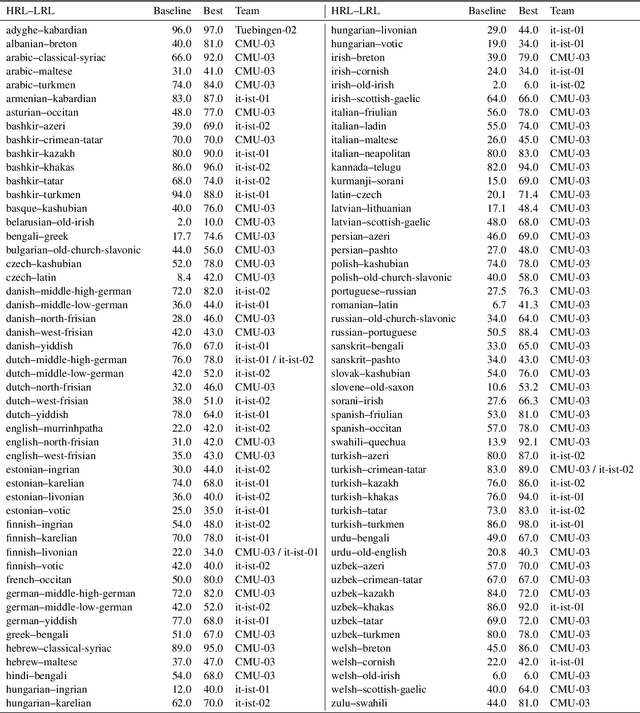
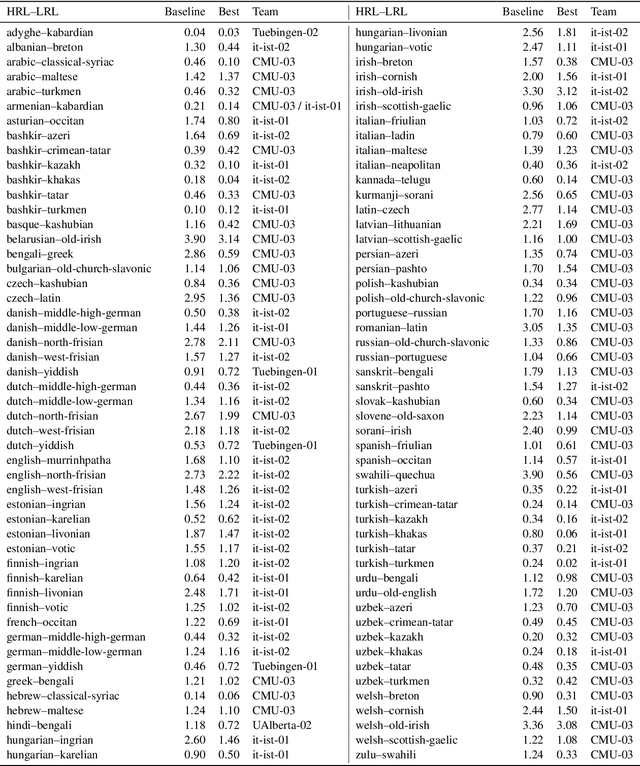
The SIGMORPHON 2019 shared task on cross-lingual transfer and contextual analysis in morphology examined transfer learning of inflection between 100 language pairs, as well as contextual lemmatization and morphosyntactic description in 66 languages. The first task evolves past years' inflection tasks by examining transfer of morphological inflection knowledge from a high-resource language to a low-resource language. This year also presents a new second challenge on lemmatization and morphological feature analysis in context. All submissions featured a neural component and built on either this year's strong baselines or highly ranked systems from previous years' shared tasks. Every participating team improved in accuracy over the baselines for the inflection task (though not Levenshtein distance), and every team in the contextual analysis task improved on both state-of-the-art neural and non-neural baselines.
* Presented at SIGMORPHON 2019
Learning with Partially Ordered Representations
Jun 23, 2019
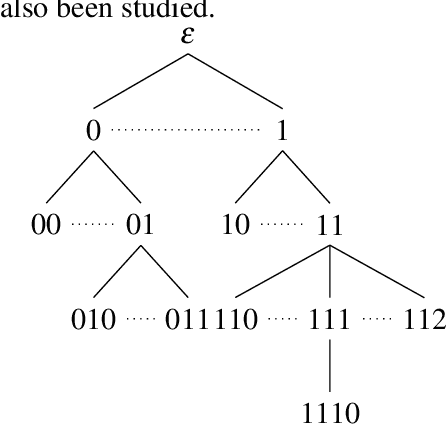
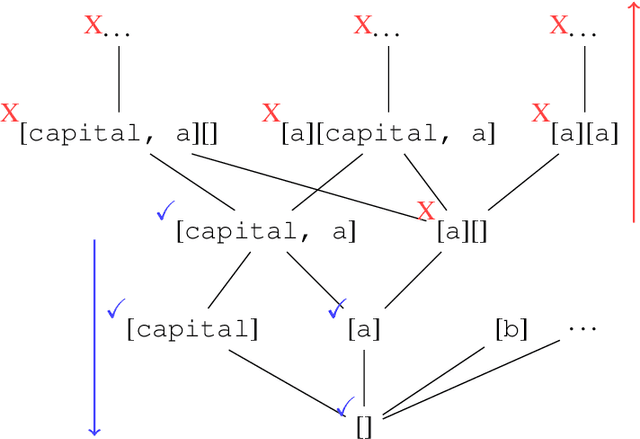
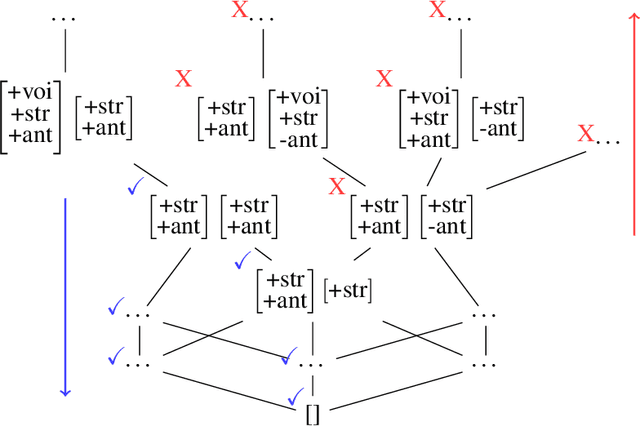
This paper examines the characterization and learning of grammars defined with enriched representational models. Model-theoretic approaches to formal language theory traditionally assume that each position in a string belongs to exactly one unary relation. We consider unconventional string models where positions can have multiple, shared properties, which are arguably useful in many applications. We show the structures given by these models are partially ordered, and present a learning algorithm that exploits this ordering relation to effectively prune the hypothesis space. We prove this learning algorithm, which takes positive examples as input, finds the most general grammar which covers the data.
Subregular Complexity and Deep Learning
Oct 14, 2017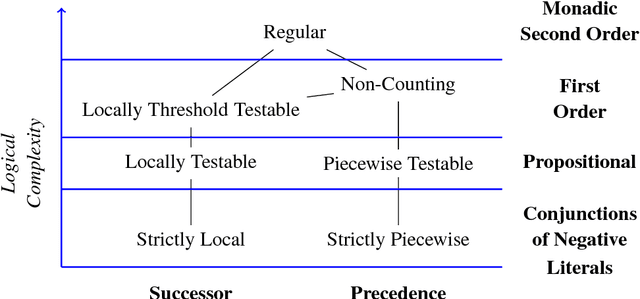

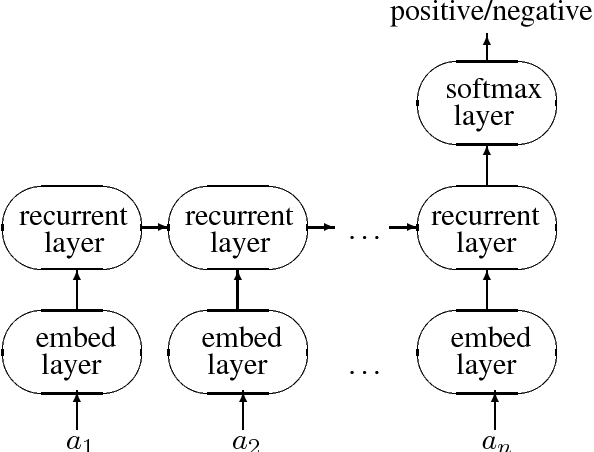
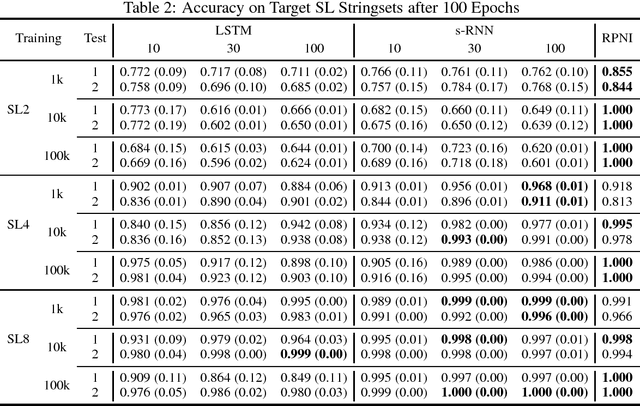
This paper argues that the judicial use of formal language theory and grammatical inference are invaluable tools in understanding how deep neural networks can and cannot represent and learn long-term dependencies in temporal sequences. Learning experiments were conducted with two types of Recurrent Neural Networks (RNNs) on six formal languages drawn from the Strictly Local (SL) and Strictly Piecewise (SP) classes. The networks were Simple RNNs (s-RNNs) and Long Short-Term Memory RNNs (LSTMs) of varying sizes. The SL and SP classes are among the simplest in a mathematically well-understood hierarchy of subregular classes. They encode local and long-term dependencies, respectively. The grammatical inference algorithm Regular Positive and Negative Inference (RPNI) provided a baseline. According to earlier research, the LSTM architecture should be capable of learning long-term dependencies and should outperform s-RNNs. The results of these experiments challenge this narrative. First, the LSTMs' performance was generally worse in the SP experiments than in the SL ones. Second, the s-RNNs out-performed the LSTMs on the most complex SP experiment and performed comparably to them on the others.
Symbolic Planning and Control Using Game Theory and Grammatical Inference
Oct 05, 2012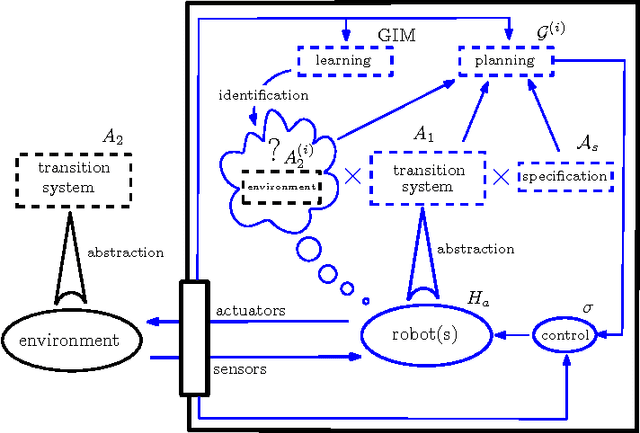



This paper presents an approach that brings together game theory with grammatical inference and discrete abstractions in order to synthesize control strategies for hybrid dynamical systems performing tasks in partially unknown but rule-governed adversarial environments. The combined formulation guarantees that a system specification is met if (a) the true model of the environment is in the class of models inferable from a positive presentation, (b) a characteristic sample is observed, and (c) the task specification is satisfiable given the capabilities of the system (agent) and the environment.