 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Linguistic Probes for Morphological Generalization
Oct 20, 2023



Modern work on the cross-linguistic computational modeling of morphological inflection has typically employed language-independent data splitting algorithms. In this paper, we supplement that approach with language-specific probes designed to test aspects of morphological generalization. Testing these probes on three morphologically distinct languages, English, Spanish, and Swahili, we find evidence that three leading morphological inflection systems employ distinct generalization strategies over conjugational classes and feature sets on both orthographic and phonologically transcribed inputs.
Why Linguistics Will Thrive in the 21st Century: A Reply to Piantadosi
Aug 06, 2023
We present a critical assessment of Piantadosi's (2023) claim that "Modern language models refute Chomsky's approach to language," focusing on four main points. First, despite the impressive performance and utility of large language models (LLMs), humans achieve their capacity for language after exposure to several orders of magnitude less data. The fact that young children become competent, fluent speakers of their native languages with relatively little exposure to them is the central mystery of language learning to which Chomsky initially drew attention, and LLMs currently show little promise of solving this mystery. Second, what can the artificial reveal about the natural? Put simply, the implications of LLMs for our understanding of the cognitive structures and mechanisms underlying language and its acquisition are like the implications of airplanes for understanding how birds fly. Third, LLMs cannot constitute scientific theories of language for several reasons, not least of which is that scientific theories must provide interpretable explanations, not just predictions. This leads to our final point: to even determine whether the linguistic and cognitive capabilities of LLMs rival those of humans requires explicating what humans' capacities actually are. In other words, it requires a separate theory of language and cognition; generative linguistics provides precisely such a theory. As such, we conclude that generative linguistics as a scientific discipline will remain indispensable throughout the 21st century and beyond.
Morphological Inflection: A Reality Check
May 25, 2023



Morphological inflection is a popular task in sub-word NLP with both practical and cognitive applications. For years now, state-of-the-art systems have reported high, but also highly variable, performance across data sets and languages. We investigate the causes of this high performance and high variability; we find several aspects of data set creation and evaluation which systematically inflate performance and obfuscate differences between languages. To improve generalizability and reliability of results, we propose new data sampling and evaluation strategies that better reflect likely use-cases. Using these new strategies, we make new observations on the generalization abilities of current inflection systems.
The Greedy and Recursive Search for Morphological Productivity
May 12, 2021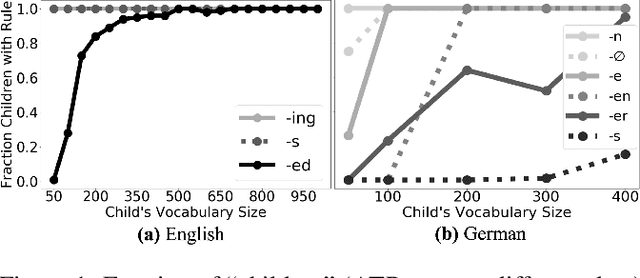
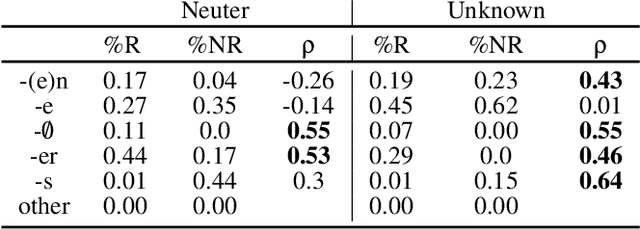
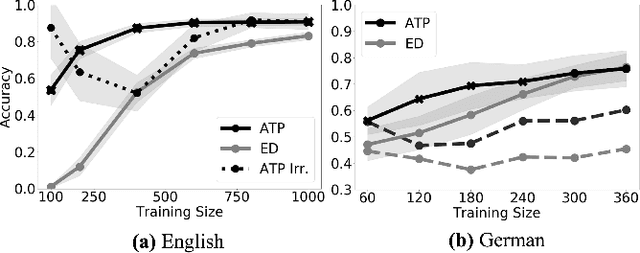
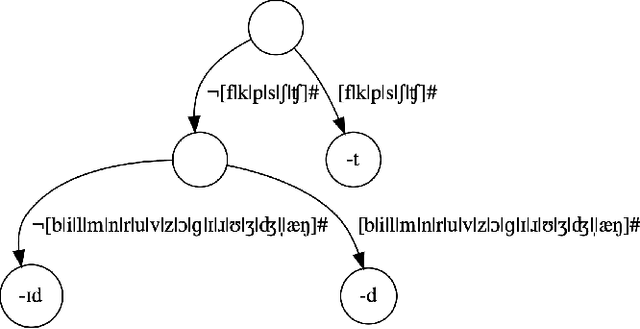
As children acquire the knowledge of their language's morphology, they invariably discover the productive processes that can generalize to new words. Morphological learning is made challenging by the fact that even fully productive rules have exceptions, as in the well-known case of English past tense verbs, which features the -ed rule against the irregular verbs. The Tolerance Principle is a recent proposal that provides a precise threshold of exceptions that a productive rule can withstand. Its empirical application so far, however, requires the researcher to fully specify rules defined over a set of words. We propose a greedy search model that automatically hypothesizes rules and evaluates their productivity over a vocabulary. When the search for broader productivity fails, the model recursively subdivides the vocabulary and continues the search for productivity over narrower rules. Trained on psychologically realistic data from child-directed input, our model displays developmental patterns observed in child morphology acquisition, including the notoriously complex case of German noun pluralization. It also produces responses to nonce words that, despite receiving only a fraction of the training data, are more similar to those of human subjects than current neural network models' responses are.
A Grounded Approach to Modeling Generic Knowledge Acquisition
May 07, 2021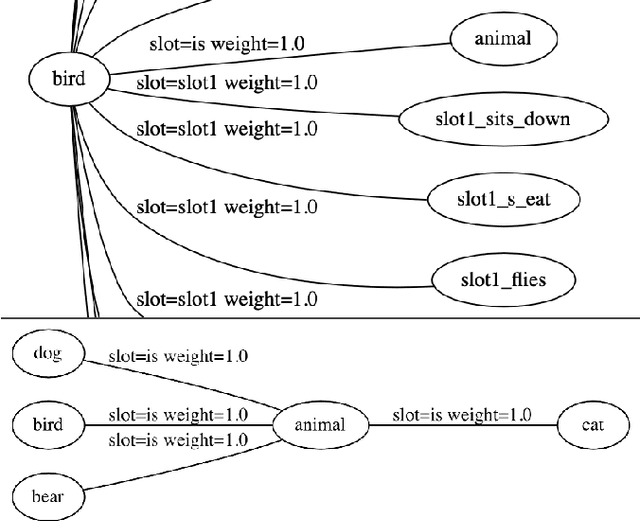
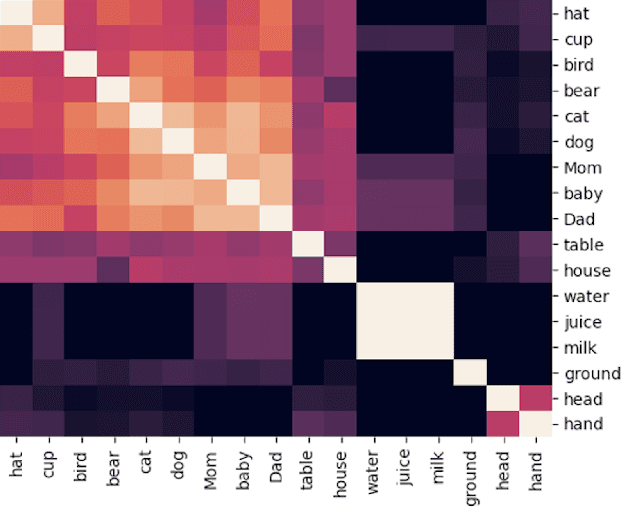

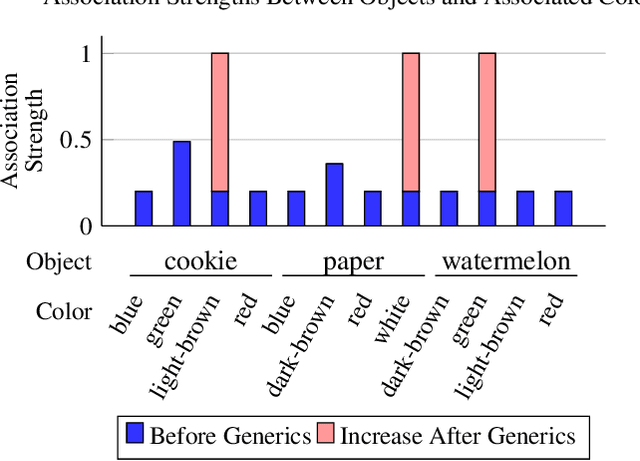
We introduce and implement a cognitively plausible model for learning from generic language, statements that express generalizations about members of a category and are an important aspect of concept development in language acquisition (Carlson & Pelletier, 1995; Gelman, 2009). We extend a computational framework designed to model grounded language acquisition by introducing the concept network. This new layer of abstraction enables the system to encode knowledge learned from generic statements and represent the associations between concepts learned by the system. Through three tasks that utilize the concept network, we demonstrate that our extensions to ADAM can acquire generic information and provide an example of how ADAM can be used to model language acquisition.
ADAM: A Sandbox for Implementing Language Learning
May 05, 2021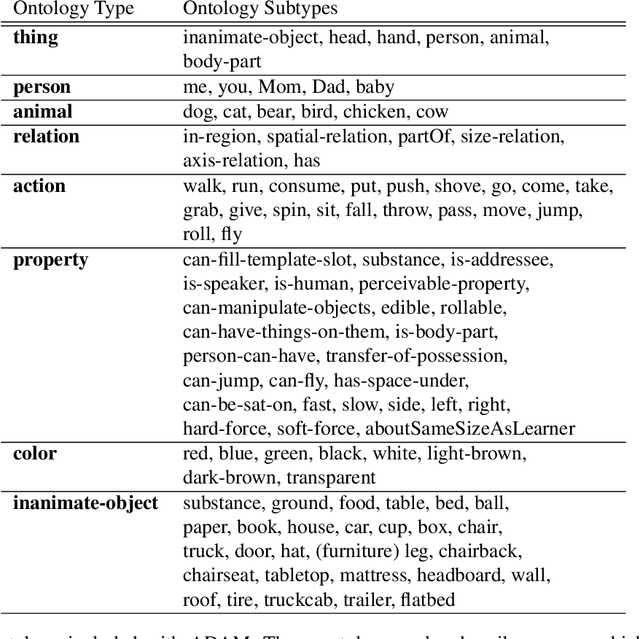

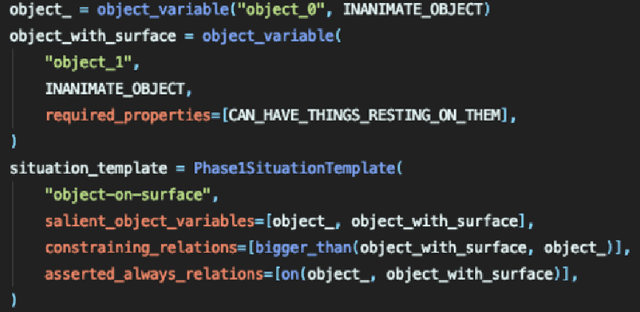
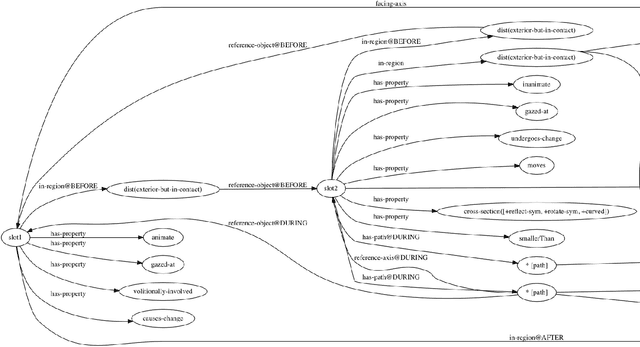
We present ADAM, a software system for designing and running child language learning experiments in Python. The system uses a virtual world to simulate a grounded language acquisition process in which the language learner utilizes cognitively plausible learning algorithms to form perceptual and linguistic representations of the observed world. The modular nature of ADAM makes it easy to design and test different language learning curricula as well as learning algorithms. In this report, we describe the architecture of the ADAM system in detail, and illustrate its components with examples. We provide our code.