 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUD-English-CHILDES: A Collected Resource of Gold and Silver Universal Dependencies Trees for Child Language Interactions
Apr 28, 2025CHILDES is a widely used resource of transcribed child and child-directed speech. This paper introduces UD-English-CHILDES, the first officially released Universal Dependencies (UD) treebank derived from previously dependency-annotated CHILDES data with consistent and unified annotation guidelines. Our corpus harmonizes annotations from 11 children and their caregivers, totaling over 48k sentences. We validate existing gold-standard annotations under the UD v2 framework and provide an additional 1M silver-standard sentences, offering a consistent resource for computational and linguistic research.
Balancing Transparency and Accuracy: A Comparative Analysis of Rule-Based and Deep Learning Models in Political Bias Classification
Nov 07, 2024



The unchecked spread of digital information, combined with increasing political polarization and the tendency of individuals to isolate themselves from opposing political viewpoints, has driven researchers to develop systems for automatically detecting political bias in media. This trend has been further fueled by discussions on social media. We explore methods for categorizing bias in US news articles, comparing rule-based and deep learning approaches. The study highlights the sensitivity of modern self-learning systems to unconstrained data ingestion, while reconsidering the strengths of traditional rule-based systems. Applying both models to left-leaning (CNN) and right-leaning (FOX) news articles, we assess their effectiveness on data beyond the original training and test sets.This analysis highlights each model's accuracy, offers a framework for exploring deep-learning explainability, and sheds light on political bias in US news media. We contrast the opaque architecture of a deep learning model with the transparency of a linguistically informed rule-based model, showing that the rule-based model performs consistently across different data conditions and offers greater transparency, whereas the deep learning model is dependent on the training set and struggles with unseen data.
The Effect of Data Partitioning Strategy on Model Generalizability: A Case Study of Morphological Segmentation
Apr 14, 2024



Recent work to enhance data partitioning strategies for more realistic model evaluation face challenges in providing a clear optimal choice. This study addresses these challenges, focusing on morphological segmentation and synthesizing limitations related to language diversity, adoption of multiple datasets and splits, and detailed model comparisons. Our study leverages data from 19 languages, including ten indigenous or endangered languages across 10 language families with diverse morphological systems (polysynthetic, fusional, and agglutinative) and different degrees of data availability. We conduct large-scale experimentation with varying sized combinations of training and evaluation sets as well as new test data. Our results show that, when faced with new test data: (1) models trained from random splits are able to achieve higher numerical scores; (2) model rankings derived from random splits tend to generalize more consistently.
Morphological Inflection: A Reality Check
May 25, 2023



Morphological inflection is a popular task in sub-word NLP with both practical and cognitive applications. For years now, state-of-the-art systems have reported high, but also highly variable, performance across data sets and languages. We investigate the causes of this high performance and high variability; we find several aspects of data set creation and evaluation which systematically inflate performance and obfuscate differences between languages. To improve generalizability and reliability of results, we propose new data sampling and evaluation strategies that better reflect likely use-cases. Using these new strategies, we make new observations on the generalization abilities of current inflection systems.
Data-driven Parsing Evaluation for Child-Parent Interactions
Sep 28, 2022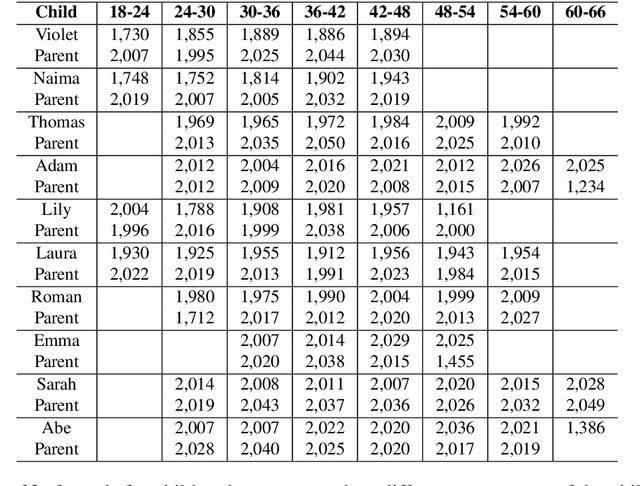
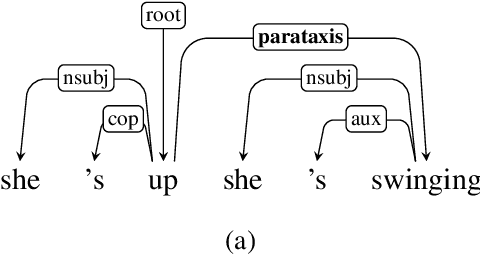
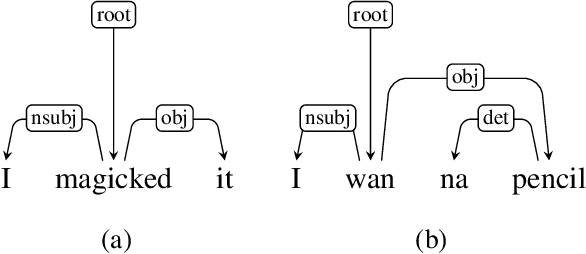
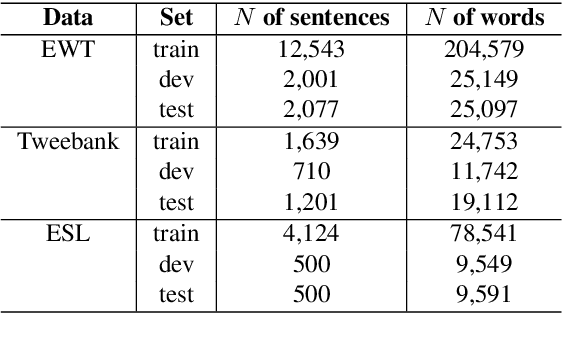
We present a syntactic dependency treebank for naturalistic child and child-directed speech in English (MacWhinney, 2000). Our annotations largely followed the guidelines of the Universal Dependencies project (UD (Zeman et al., 2022)), with detailed extensions to lexical/syntactic structures unique to conversational speech (in opposition to written texts). Compared to existing UD-style spoken treebanks as well as other dependency corpora of child-parent interactions specifically, our dataset is of (much) larger size (N of utterances = 44,744; N of words = 233, 907) and contains speech from a total of 10 children covering a wide age range (18-66 months). With this dataset, we ask: (1) How well would state-of-the-art dependency parsers, tailored for the written domain, perform for speech of different interlocutors in spontaneous conversations? (2) What is the relationship between parser performance and the developmental stage of the child? To address these questions, in ongoing work, we are conducting thorough dependency parser evaluations using both graph-based and transition-based parsers with different hyperparameterization, trained from three different types of out-of-domain written texts: news, tweets, and learner data.
Investigating data partitioning strategies for crosslinguistic low-resource ASR evaluation
Aug 26, 2022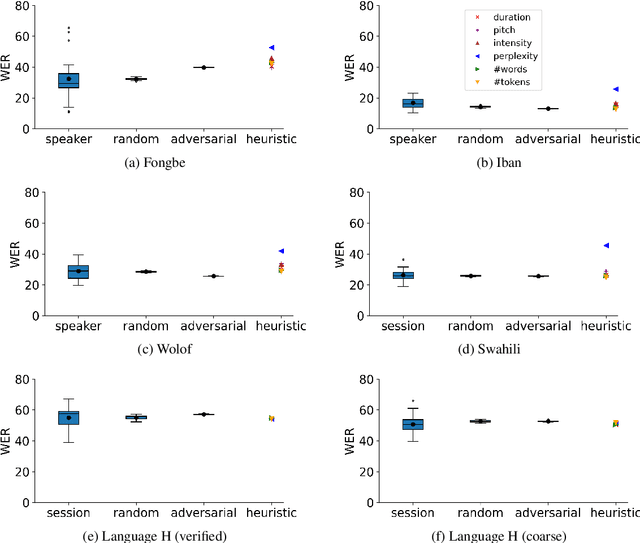
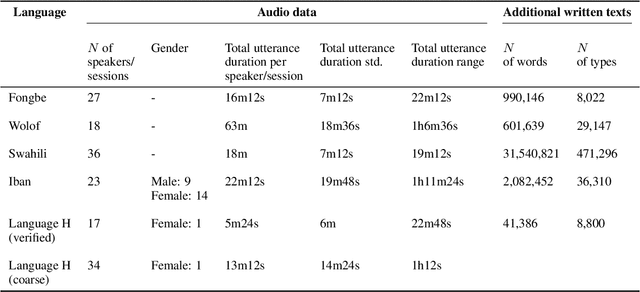
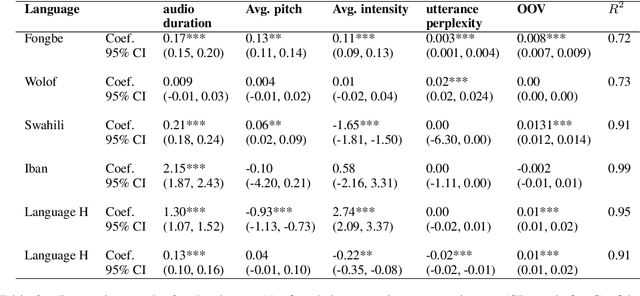
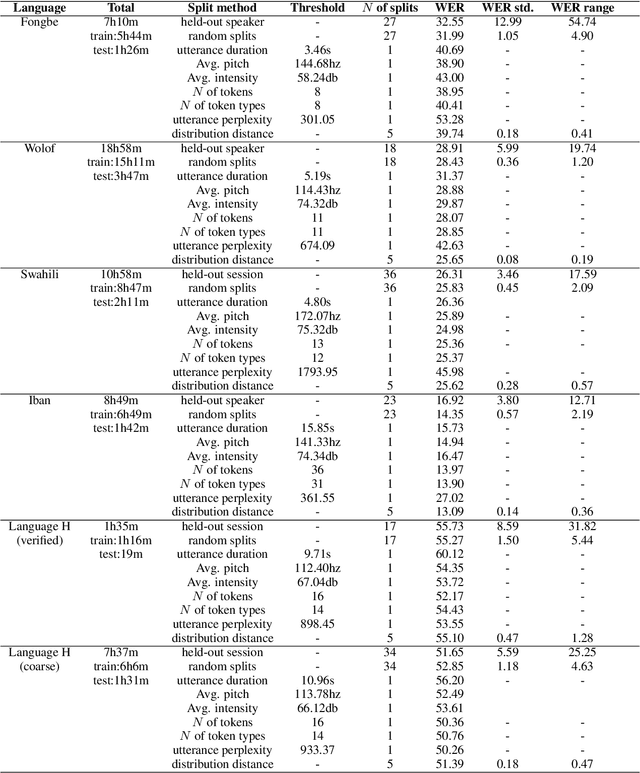
Many automatic speech recognition (ASR) data sets include a single pre-defined test set consisting of one or more speakers whose speech never appears in the training set. This "hold-speaker(s)-out" data partitioning strategy, however, may not be ideal for data sets in which the number of speakers is very small. This study investigates ten different data split methods for five languages with minimal ASR training resources. We find that (1) model performance varies greatly depending on which speaker is selected for testing; (2) the average word error rate (WER) across all held-out speakers is comparable not only to the average WER over multiple random splits but also to any given individual random split; (3) WER is also generally comparable when the data is split heuristically or adversarially; (4) utterance duration and intensity are comparatively more predictive factors of variability regardless of the data split. These results suggest that the widely used hold-speakers-out approach to ASR data partitioning can yield results that do not reflect model performance on unseen data or speakers. Random splits can yield more reliable and generalizable estimates when facing data sparsity.
UniMorph 4.0: Universal Morphology
May 10, 2022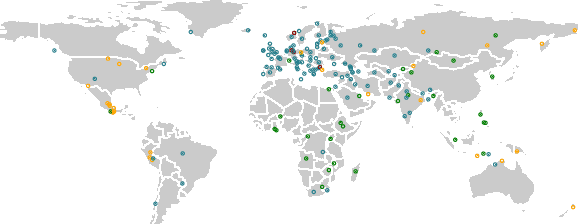

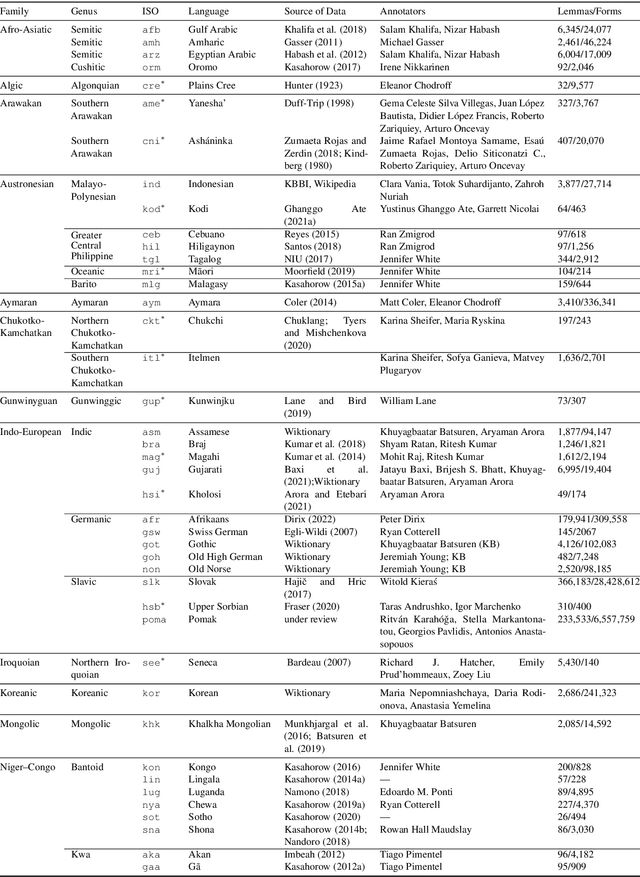
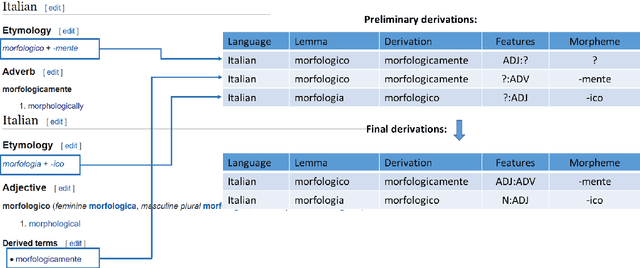
The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Not always about you: Prioritizing community needs when developing endangered language technology
Apr 12, 2022

Languages are classified as low-resource when they lack the quantity of data necessary for training statistical and machine learning tools and models. Causes of resource scarcity vary but can include poor access to technology for developing these resources, a relatively small population of speakers, or a lack of urgency for collecting such resources in bilingual populations where the second language is high-resource. As a result, the languages described as low-resource in the literature are as different as Finnish on the one hand, with millions of speakers using it in every imaginable domain, and Seneca, with only a small-handful of fluent speakers using the language primarily in a restricted domain. While issues stemming from the lack of resources necessary to train models unite this disparate group of languages, many other issues cut across the divide between widely-spoken low resource languages and endangered languages. In this position paper, we discuss the unique technological, cultural, practical, and ethical challenges that researchers and indigenous speech community members face when working together to develop language technology to support endangered language documentation and revitalization. We report the perspectives of language teachers, Master Speakers and elders from indigenous communities, as well as the point of view of academics. We describe an ongoing fruitful collaboration and make recommendations for future partnerships between academic researchers and language community stakeholders.
Data-driven Model Generalizability in Crosslinguistic Low-resource Morphological Segmentation
Jan 05, 2022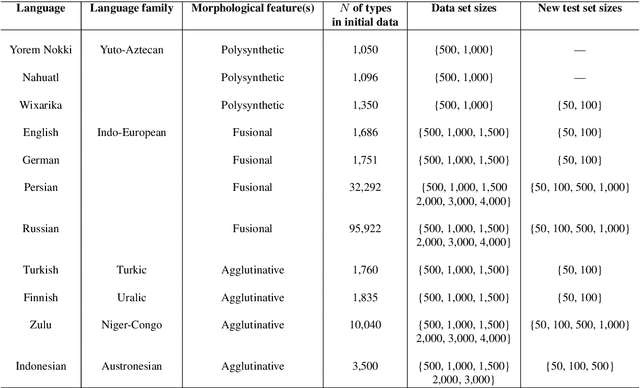
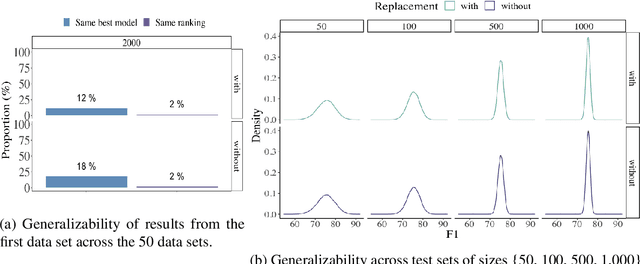
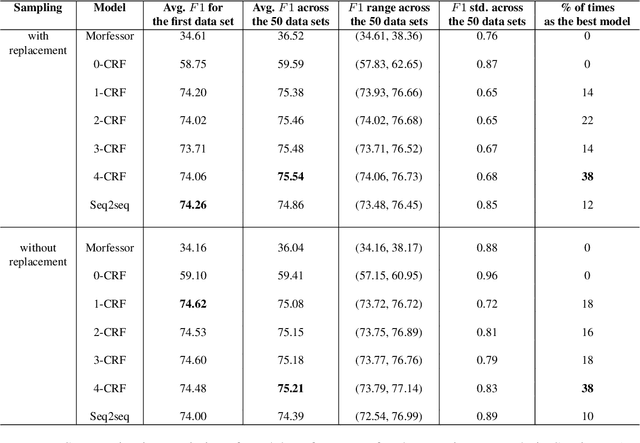
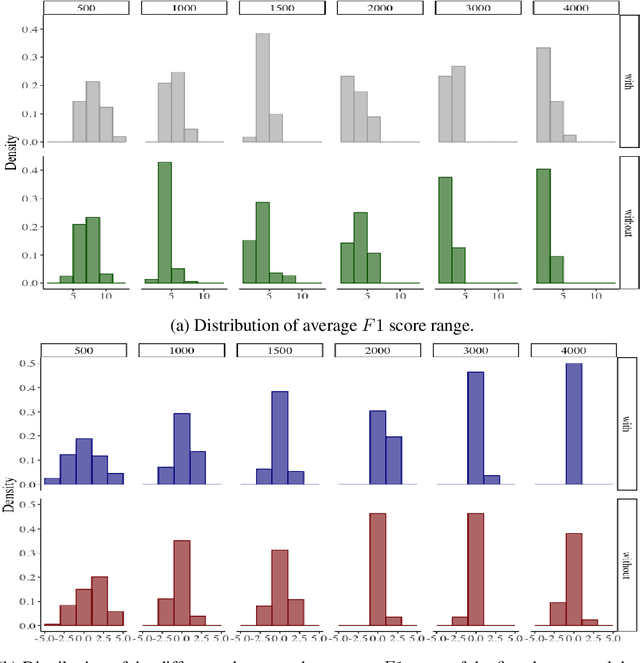
Common designs of model evaluation typically focus on monolingual settings, where different models are compared according to their performance on a single data set that is assumed to be representative of all possible data for the task at hand. While this may be reasonable for a large data set, this assumption is difficult to maintain in low-resource scenarios, where artifacts of the data collection can yield data sets that are outliers, potentially making conclusions about model performance coincidental. To address these concerns, we investigate model generalizability in crosslinguistic low-resource scenarios. Using morphological segmentation as the test case, we compare three broad classes of models with different parameterizations, taking data from 11 languages across 6 language families. In each experimental setting, we evaluate all models on a first data set, then examine their performance consistency when introducing new randomly sampled data sets with the same size and when applying the trained models to unseen test sets of varying sizes. The results demonstrate that the extent of model generalization depends on the characteristics of the data set, and does not necessarily rely heavily on the data set size. Among the characteristics that we studied, the ratio of morpheme overlap and that of the average number of morphemes per word between the training and test sets are the two most prominent factors. Our findings suggest that future work should adopt random sampling to construct data sets with different sizes in order to make more responsible claims about model evaluation.
Predicting cross-linguistic adjective order with information gain
Dec 30, 2020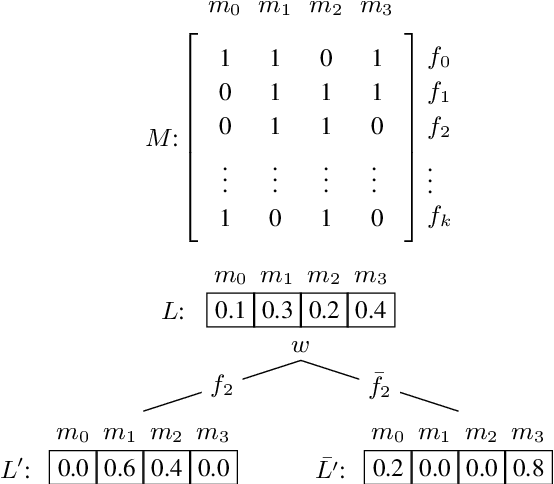
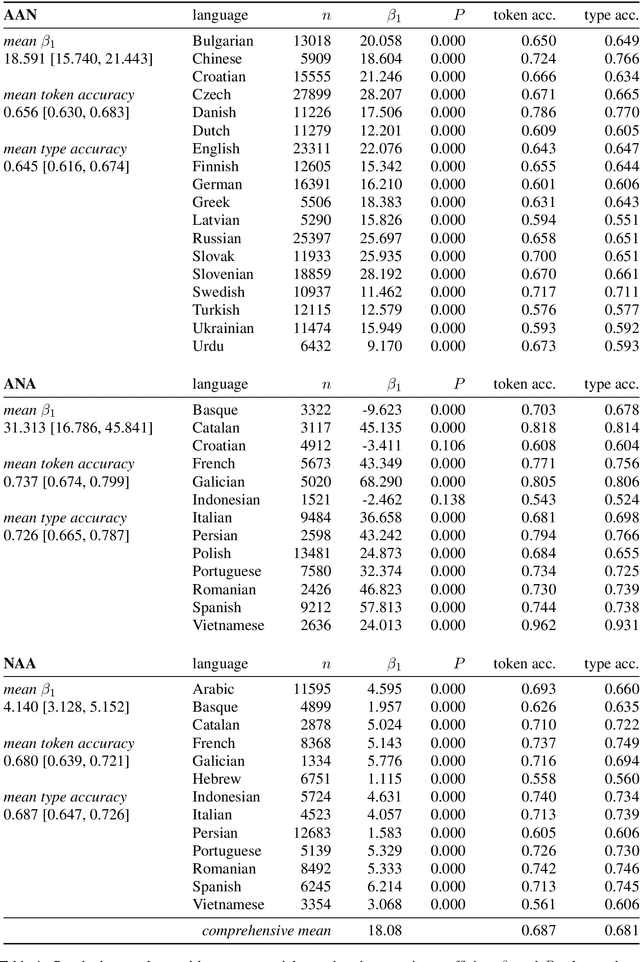
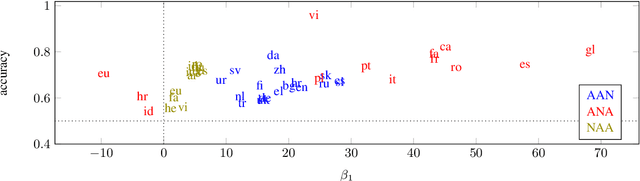
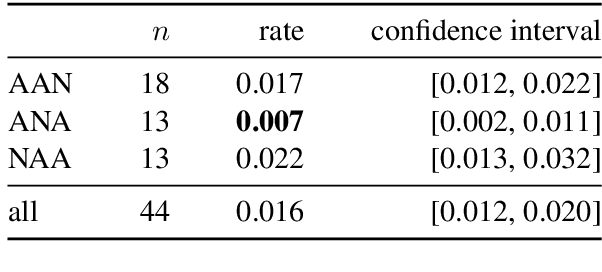
Languages vary in their placement of multiple adjectives before, after, or surrounding the noun, but they typically exhibit strong intra-language tendencies on the relative order of those adjectives (e.g., the preference for `big blue box' in English, `grande bo\^{i}te bleue' in French, and `alsund\={u}q al'azraq alkab\={\i}r' in Arabic). We advance a new quantitative account of adjective order across typologically-distinct languages based on maximizing information gain. Our model addresses the left-right asymmetry of French-type ANA sequences with the same approach as AAN and NAA orderings, without appeal to other mechanisms. We find that, across 32 languages, the preferred order of adjectives largely mirrors an efficient algorithm of maximizing information gain.