 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Parsing Evaluation for Child-Parent Interactions
Paper and Code
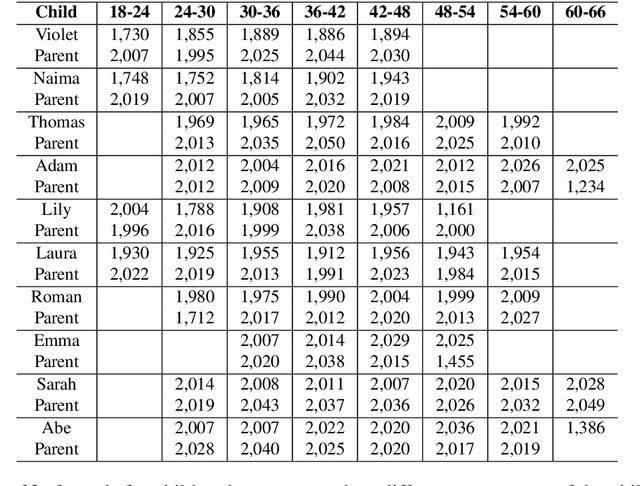
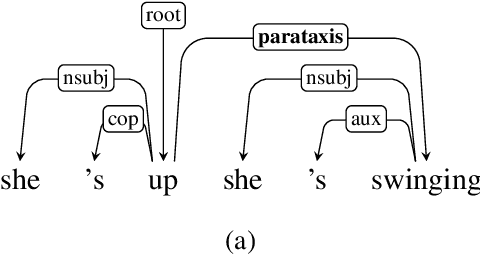
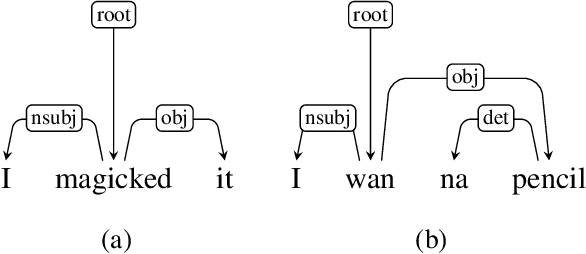
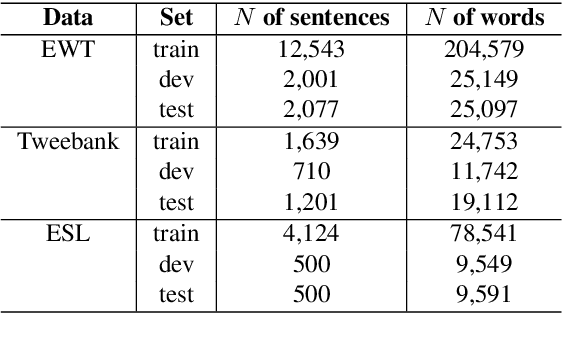
We present a syntactic dependency treebank for naturalistic child and child-directed speech in English (MacWhinney, 2000). Our annotations largely followed the guidelines of the Universal Dependencies project (UD (Zeman et al., 2022)), with detailed extensions to lexical/syntactic structures unique to conversational speech (in opposition to written texts). Compared to existing UD-style spoken treebanks as well as other dependency corpora of child-parent interactions specifically, our dataset is of (much) larger size (N of utterances = 44,744; N of words = 233, 907) and contains speech from a total of 10 children covering a wide age range (18-66 months). With this dataset, we ask: (1) How well would state-of-the-art dependency parsers, tailored for the written domain, perform for speech of different interlocutors in spontaneous conversations? (2) What is the relationship between parser performance and the developmental stage of the child? To address these questions, in ongoing work, we are conducting thorough dependency parser evaluations using both graph-based and transition-based parsers with different hyperparameterization, trained from three different types of out-of-domain written texts: news, tweets, and learner data.