 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUD-English-CHILDES: A Collected Resource of Gold and Silver Universal Dependencies Trees for Child Language Interactions
Apr 28, 2025CHILDES is a widely used resource of transcribed child and child-directed speech. This paper introduces UD-English-CHILDES, the first officially released Universal Dependencies (UD) treebank derived from previously dependency-annotated CHILDES data with consistent and unified annotation guidelines. Our corpus harmonizes annotations from 11 children and their caregivers, totaling over 48k sentences. We validate existing gold-standard annotations under the UD v2 framework and provide an additional 1M silver-standard sentences, offering a consistent resource for computational and linguistic research.
Advancing Auto-Regressive Continuation for Video Frames
Dec 04, 2024



Recent advances in auto-regressive large language models (LLMs) have shown their potential in generating high-quality text, inspiring researchers to apply them to image and video generation. This paper explores the application of LLMs to video continuation, a task essential for building world models and predicting future frames. In this paper, we tackle challenges including preventing degeneration in long-term frame generation and enhancing the quality of generated images. We design a scheme named ARCON, which involves training our model to alternately generate semantic tokens and RGB tokens, enabling the LLM to explicitly learn and predict the high-level structural information of the video. We find high consistency in the RGB images and semantic maps generated without special design. Moreover, we employ an optical flow-based texture stitching method to enhance the visual quality of the generated videos. Quantitative and qualitative experiments in autonomous driving scenarios demonstrate our model can consistently generate long videos.
A Survey on Video Prediction: From Deterministic to Generative Approaches
Jan 31, 2024
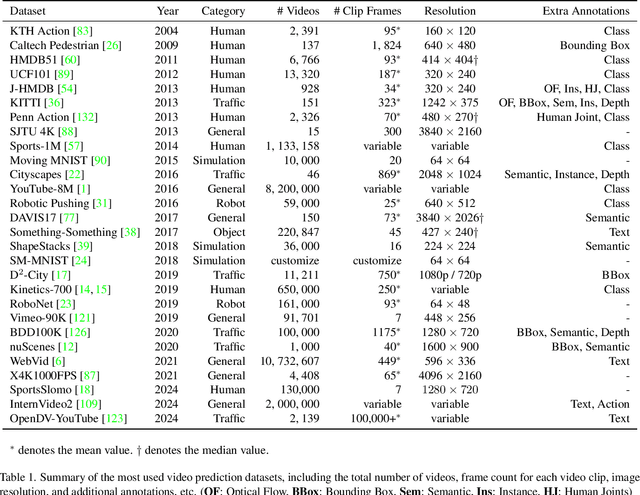
Video prediction, a fundamental task in computer vision, aims to enable models to generate sequences of future frames based on existing video content. This task has garnered widespread application across various domains. In this paper, we comprehensively survey both historical and contemporary works in this field, encompassing the most widely used datasets and algorithms. Our survey scrutinizes the challenges and evolving landscape of video prediction within the realm of computer vision. We propose a novel taxonomy centered on the stochastic nature of video prediction algorithms. This taxonomy accentuates the gradual transition from deterministic to generative prediction methodologies, underlining significant advancements and shifts in approach.