 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Robotic Policy Learning via Latent Space Backward Planning
May 11, 2025Current robotic planning methods often rely on predicting multi-frame images with full pixel details. While this fine-grained approach can serve as a generic world model, it introduces two significant challenges for downstream policy learning: substantial computational costs that hinder real-time deployment, and accumulated inaccuracies that can mislead action extraction. Planning with coarse-grained subgoals partially alleviates efficiency issues. However, their forward planning schemes can still result in off-task predictions due to accumulation errors, leading to misalignment with long-term goals. This raises a critical question: Can robotic planning be both efficient and accurate enough for real-time control in long-horizon, multi-stage tasks? To address this, we propose a Latent Space Backward Planning scheme (LBP), which begins by grounding the task into final latent goals, followed by recursively predicting intermediate subgoals closer to the current state. The grounded final goal enables backward subgoal planning to always remain aware of task completion, facilitating on-task prediction along the entire planning horizon. The subgoal-conditioned policy incorporates a learnable token to summarize the subgoal sequences and determines how each subgoal guides action extraction. Through extensive simulation and real-robot long-horizon experiments, we show that LBP outperforms existing fine-grained and forward planning methods, achieving SOTA performance. Project Page: https://lbp-authors.github.io
Are Expressive Models Truly Necessary for Offline RL?
Dec 15, 2024



Among various branches of offline reinforcement learning (RL) methods, goal-conditioned supervised learning (GCSL) has gained increasing popularity as it formulates the offline RL problem as a sequential modeling task, therefore bypassing the notoriously difficult credit assignment challenge of value learning in conventional RL paradigm. Sequential modeling, however, requires capturing accurate dynamics across long horizons in trajectory data to ensure reasonable policy performance. To meet this requirement, leveraging large, expressive models has become a popular choice in recent literature, which, however, comes at the cost of significantly increased computation and inference latency. Contradictory yet promising, we reveal that lightweight models as simple as shallow 2-layer MLPs, can also enjoy accurate dynamics consistency and significantly reduced sequential modeling errors against large expressive models by adopting a simple recursive planning scheme: recursively planning coarse-grained future sub-goals based on current and target information, and then executes the action with a goal-conditioned policy learned from data rela-beled with these sub-goal ground truths. We term our method Recursive Skip-Step Planning (RSP). Simple yet effective, RSP enjoys great efficiency improvements thanks to its lightweight structure, and substantially outperforms existing methods, reaching new SOTA performances on the D4RL benchmark, especially in multi-stage long-horizon tasks.
Timealign: A multi-modal object detection method for time misalignment fusing in autonomous driving
Dec 13, 2024



The multi-modal perception methods are thriving in the autonomous driving field due to their better usage of complementary data from different sensors. Such methods depend on calibration and synchronization between sensors to get accurate environmental information. There have already been studies about space-alignment robustness in autonomous driving object detection process, however, the research for time-alignment is relatively few. As in reality experiments, LiDAR point clouds are more challenging for real-time data transfer, our study used historical frames of LiDAR to better align features when the LiDAR data lags exist. We designed a Timealign module to predict and combine LiDAR features with observation to tackle such time misalignment based on SOTA GraphBEV framework.
xTED: Cross-Domain Policy Adaptation via Diffusion-Based Trajectory Editing
Sep 13, 2024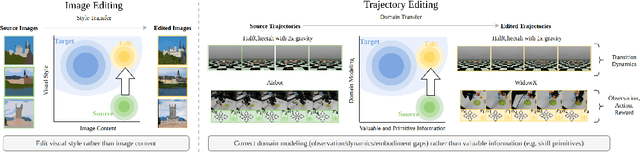
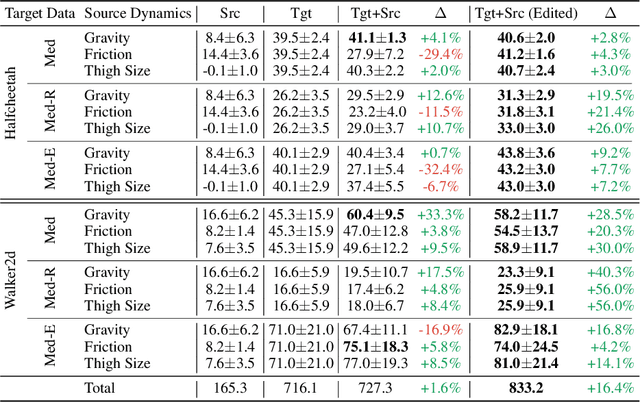
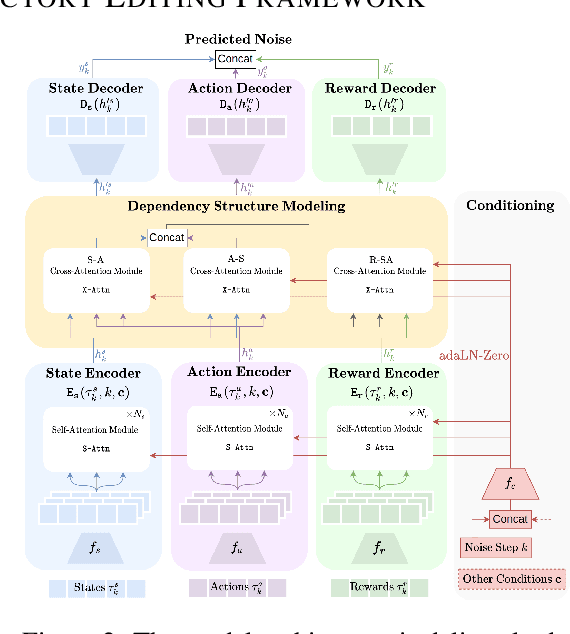

Reusing pre-collected data from different domains is an attractive solution in decision-making tasks where the accessible data is insufficient in the target domain but relatively abundant in other related domains. Existing cross-domain policy transfer methods mostly aim at learning domain correspondences or corrections to facilitate policy learning, which requires learning domain/task-specific model components, representations, or policies that are inflexible or not fully reusable to accommodate arbitrary domains and tasks. These issues make us wonder: can we directly bridge the domain gap at the data (trajectory) level, instead of devising complicated, domain-specific policy transfer models? In this study, we propose a Cross-Domain Trajectory EDiting (xTED) framework with a new diffusion transformer model (Decision Diffusion Transformer, DDiT) that captures the trajectory distribution from the target dataset as a prior. The proposed diffusion transformer backbone captures the intricate dependencies among state, action, and reward sequences, as well as the transition dynamics within the target data trajectories. With the above pre-trained diffusion prior, source data trajectories with domain gaps can be transformed into edited trajectories that closely resemble the target data distribution through the diffusion-based editing process, which implicitly corrects the underlying domain gaps, enhancing the state realism and dynamics reliability in source trajectory data, while enabling flexible choices of downstream policy learning methods. Despite its simplicity, xTED demonstrates superior performance against other baselines in extensive simulation and real-robot experiments.
Dynamically Expanding Capacity of Autonomous Driving with Near-Miss Focused Training Framework
Jun 05, 2024The long-tail distribution of real driving data poses challenges for training and testing autonomous vehicles (AV), where rare yet crucial safety-critical scenarios are infrequent. And virtual simulation offers a low-cost and efficient solution. This paper proposes a near-miss focused training framework for AV. Utilizing the driving scenario information provided by sensors in the simulator, we design novel reward functions, which enable background vehicles (BV) to generate near-miss scenarios and ensure gradients exist not only in collision-free scenes but also in collision scenarios. And then leveraging the Robust Adversarial Reinforcement Learning (RARL) framework for simultaneous training of AV and BV to gradually enhance AV and BV capabilities, as well as generating near-miss scenarios tailored to different levels of AV capabilities. Results from three testing strategies indicate that the proposed method generates scenarios closer to near-miss, thus enhancing the capabilities of both AVs and BVs throughout training.
A re-calibration method for object detection with multi-modal alignment bias in autonomous driving
May 27, 2024



Multi-modal object detection in autonomous driving has achieved great breakthroughs due to the usage of fusing complementary information from different sensors. The calibration in fusion between sensors such as LiDAR and camera is always supposed to be precise in previous work. However, in reality, calibration matrices are fixed when the vehicles leave the factory, but vibration, bumps, and data lags may cause calibration bias. As the research on the calibration influence on fusion detection performance is relatively few, flexible calibration dependency multi-sensor detection method has always been attractive. In this paper, we conducted experiments on SOTA detection method EPNet++ and proved slight bias on calibration can reduce the performance seriously. We also proposed a re-calibration model based on semantic segmentation which can be combined with a detection algorithm to improve the performance and robustness of multi-modal calibration bias.
Adaptive Testing Environment Generation for Connected and Automated Vehicles with Dense Reinforcement Learning
Feb 29, 2024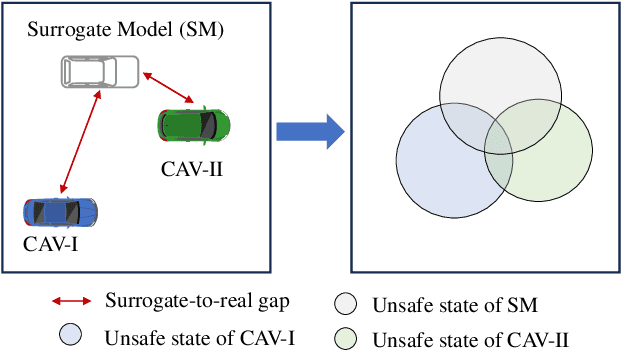
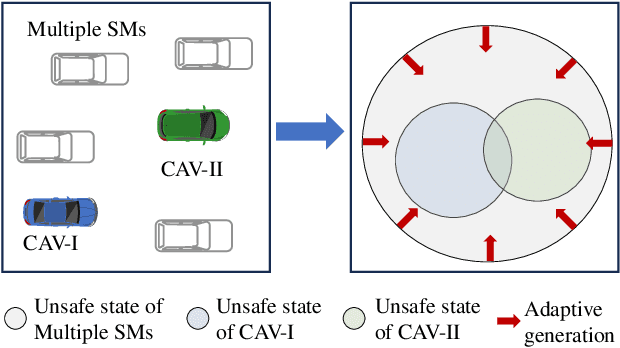
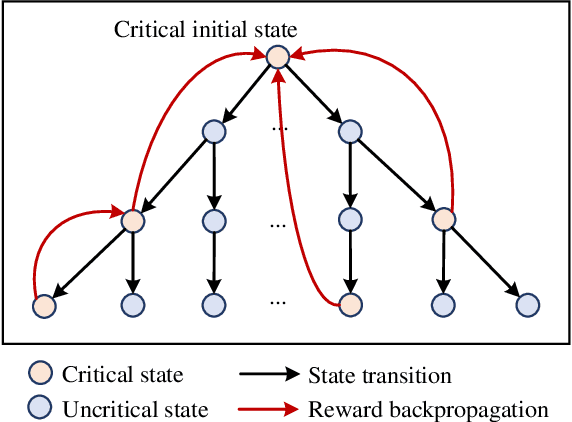
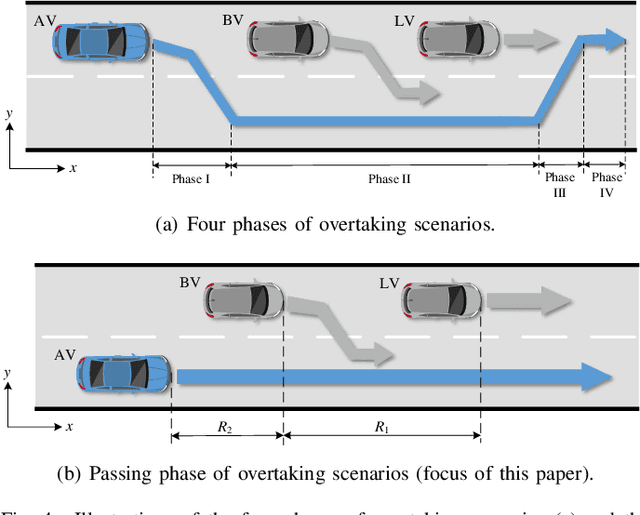
The assessment of safety performance plays a pivotal role in the development and deployment of connected and automated vehicles (CAVs). A common approach involves designing testing scenarios based on prior knowledge of CAVs (e.g., surrogate models), conducting tests in these scenarios, and subsequently evaluating CAVs' safety performances. However, substantial differences between CAVs and the prior knowledge can significantly diminish the evaluation efficiency. In response to this issue, existing studies predominantly concentrate on the adaptive design of testing scenarios during the CAV testing process. Yet, these methods have limitations in their applicability to high-dimensional scenarios. To overcome this challenge, we develop an adaptive testing environment that bolsters evaluation robustness by incorporating multiple surrogate models and optimizing the combination coefficients of these surrogate models to enhance evaluation efficiency. We formulate the optimization problem as a regression task utilizing quadratic programming. To efficiently obtain the regression target via reinforcement learning, we propose the dense reinforcement learning method and devise a new adaptive policy with high sample efficiency. Essentially, our approach centers on learning the values of critical scenes displaying substantial surrogate-to-real gaps. The effectiveness of our method is validated in high-dimensional overtaking scenarios, demonstrating that our approach achieves notable evaluation efficiency.
A Comprehensive Survey of Cross-Domain Policy Transfer for Embodied Agents
Feb 07, 2024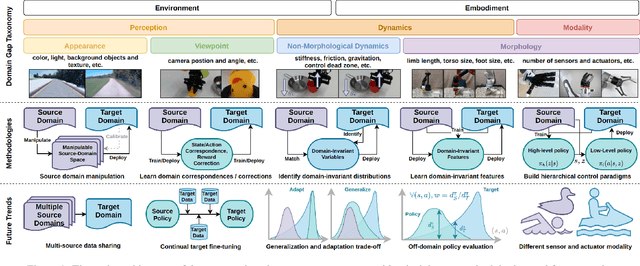
The burgeoning fields of robot learning and embodied AI have triggered an increasing demand for large quantities of data. However, collecting sufficient unbiased data from the target domain remains a challenge due to costly data collection processes and stringent safety requirements. Consequently, researchers often resort to data from easily accessible source domains, such as simulation and laboratory environments, for cost-effective data acquisition and rapid model iteration. Nevertheless, the environments and embodiments of these source domains can be quite different from their target domain counterparts, underscoring the need for effective cross-domain policy transfer approaches. In this paper, we conduct a systematic review of existing cross-domain policy transfer methods. Through a nuanced categorization of domain gaps, we encapsulate the overarching insights and design considerations of each problem setting. We also provide a high-level discussion about the key methodologies used in cross-domain policy transfer problems. Lastly, we summarize the open challenges that lie beyond the capabilities of current paradigms and discuss potential future directions in this field.
Few-Shot Scenario Testing for Autonomous Vehicles Based on Neighborhood Coverage and Similarity
Feb 02, 2024Testing and evaluating the safety performance of autonomous vehicles (AVs) is essential before the large-scale deployment. Practically, the acceptable cost of testing specific AV model can be restricted within an extremely small limit because of testing cost or time. With existing testing methods, the limitations imposed by strictly restricted testing numbers often result in significant uncertainties or challenges in quantifying testing results. In this paper, we formulate this problem for the first time the "few-shot testing" (FST) problem and propose a systematic FST framework to address this challenge. To alleviate the considerable uncertainty inherent in a small testing scenario set and optimize scenario utilization, we frame the FST problem as an optimization problem and search for a small scenario set based on neighborhood coverage and similarity. By leveraging the prior information on surrogate models (SMs), we dynamically adjust the testing scenario set and the contribution of each scenario to the testing result under the guidance of better generalization ability on AVs. With certain hypotheses on SMs, a theoretical upper bound of testing error is established to verify the sufficiency of testing accuracy within given limited number of tests. The experiments of the cut-in scenario using FST method demonstrate a notable reduction in testing error and variance compared to conventional testing methods, especially for situations with a strict limitation on the number of scenarios.
A Survey on Video Prediction: From Deterministic to Generative Approaches
Jan 31, 2024
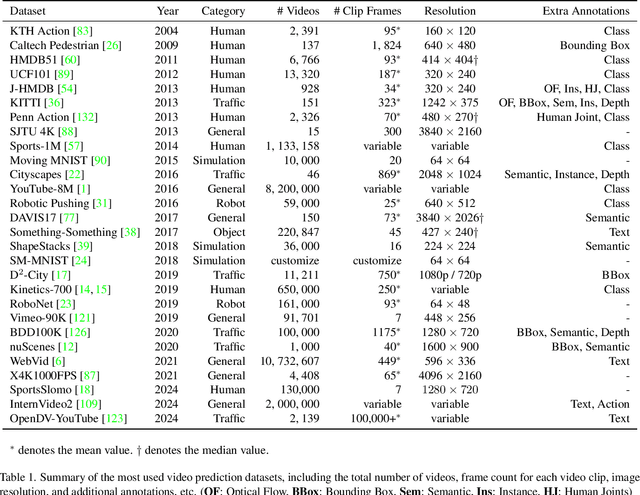
Video prediction, a fundamental task in computer vision, aims to enable models to generate sequences of future frames based on existing video content. This task has garnered widespread application across various domains. In this paper, we comprehensively survey both historical and contemporary works in this field, encompassing the most widely used datasets and algorithms. Our survey scrutinizes the challenges and evolving landscape of video prediction within the realm of computer vision. We propose a novel taxonomy centered on the stochastic nature of video prediction algorithms. This taxonomy accentuates the gradual transition from deterministic to generative prediction methodologies, underlining significant advancements and shifts in approach.