 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Auto-Regressive Continuation for Video Frames
Dec 04, 2024



Recent advances in auto-regressive large language models (LLMs) have shown their potential in generating high-quality text, inspiring researchers to apply them to image and video generation. This paper explores the application of LLMs to video continuation, a task essential for building world models and predicting future frames. In this paper, we tackle challenges including preventing degeneration in long-term frame generation and enhancing the quality of generated images. We design a scheme named ARCON, which involves training our model to alternately generate semantic tokens and RGB tokens, enabling the LLM to explicitly learn and predict the high-level structural information of the video. We find high consistency in the RGB images and semantic maps generated without special design. Moreover, we employ an optical flow-based texture stitching method to enhance the visual quality of the generated videos. Quantitative and qualitative experiments in autonomous driving scenarios demonstrate our model can consistently generate long videos.
OccTransformer: Improving BEVFormer for 3D camera-only occupancy prediction
Feb 28, 2024
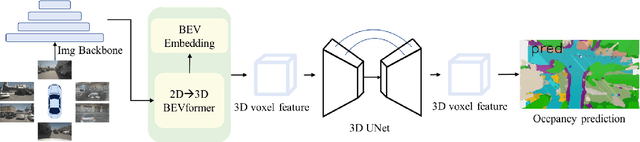

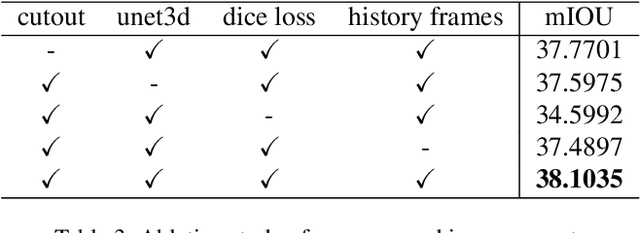
This technical report presents our solution, "occTransformer" for the 3D occupancy prediction track in the autonomous driving challenge at CVPR 2023. Our method builds upon the strong baseline BEVFormer and improves its performance through several simple yet effective techniques. Firstly, we employed data augmentation to increase the diversity of the training data and improve the model's generalization ability. Secondly, we used a strong image backbone to extract more informative features from the input data. Thirdly, we incorporated a 3D unet head to better capture the spatial information of the scene. Fourthly, we added more loss functions to better optimize the model. Additionally, we used an ensemble approach with the occ model BevDet and SurroundOcc to further improve the performance. Most importantly, we integrated 3D detection model StreamPETR to enhance the model's ability to detect objects in the scene. Using these methods, our solution achieved 49.23 miou on the 3D occupancy prediction track in the autonomous driving challenge.
A Survey on Video Prediction: From Deterministic to Generative Approaches
Jan 31, 2024
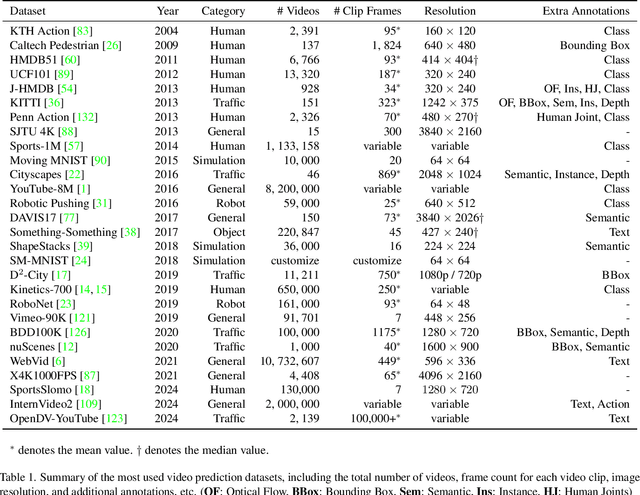
Video prediction, a fundamental task in computer vision, aims to enable models to generate sequences of future frames based on existing video content. This task has garnered widespread application across various domains. In this paper, we comprehensively survey both historical and contemporary works in this field, encompassing the most widely used datasets and algorithms. Our survey scrutinizes the challenges and evolving landscape of video prediction within the realm of computer vision. We propose a novel taxonomy centered on the stochastic nature of video prediction algorithms. This taxonomy accentuates the gradual transition from deterministic to generative prediction methodologies, underlining significant advancements and shifts in approach.
Synthetic Datasets for Autonomous Driving: A Survey
Apr 24, 2023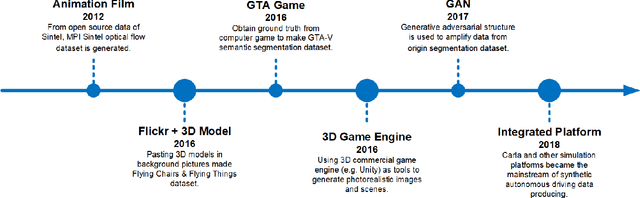



Autonomous driving techniques have been flourishing in recent years while thirsting for huge amounts of high-quality data. However, it is difficult for real-world datasets to keep up with the pace of changing requirements due to their expensive and time-consuming experimental and labeling costs. Therefore, more and more researchers are turning to synthetic datasets to easily generate rich and changeable data as an effective complement to the real world and to improve the performance of algorithms. In this paper, we summarize the evolution of synthetic dataset generation methods and review the work to date in synthetic datasets related to single and multi-task categories for to autonomous driving study. We also discuss the role that synthetic dataset plays the evaluation, gap test, and positive effect in autonomous driving related algorithm testing, especially on trustworthiness and safety aspects. Finally, we discuss general trends and possible development directions. To the best of our knowledge, this is the first survey focusing on the application of synthetic datasets in autonomous driving. This survey also raises awareness of the problems of real-world deployment of autonomous driving technology and provides researchers with a possible solution.
RaBit: Parametric Modeling of 3D Biped Cartoon Characters with a Topological-consistent Dataset
Mar 24, 2023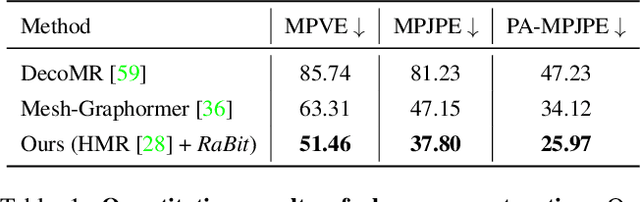


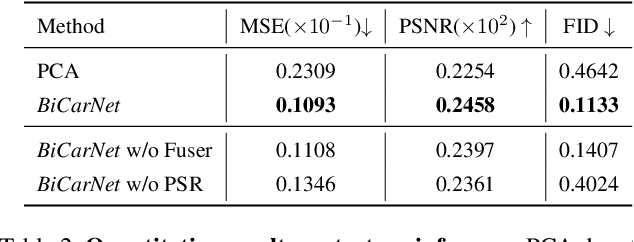
Assisting people in efficiently producing visually plausible 3D characters has always been a fundamental research topic in computer vision and computer graphics. Recent learning-based approaches have achieved unprecedented accuracy and efficiency in the area of 3D real human digitization. However, none of the prior works focus on modeling 3D biped cartoon characters, which are also in great demand in gaming and filming. In this paper, we introduce 3DBiCar, the first large-scale dataset of 3D biped cartoon characters, and RaBit, the corresponding parametric model. Our dataset contains 1,500 topologically consistent high-quality 3D textured models which are manually crafted by professional artists. Built upon the data, RaBit is thus designed with a SMPL-like linear blend shape model and a StyleGAN-based neural UV-texture generator, simultaneously expressing the shape, pose, and texture. To demonstrate the practicality of 3DBiCar and RaBit, various applications are conducted, including single-view reconstruction, sketch-based modeling, and 3D cartoon animation. For the single-view reconstruction setting, we find a straightforward global mapping from input images to the output UV-based texture maps tends to lose detailed appearances of some local parts (e.g., nose, ears). Thus, a part-sensitive texture reasoner is adopted to make all important local areas perceived. Experiments further demonstrate the effectiveness of our method both qualitatively and quantitatively. 3DBiCar and RaBit are available at gaplab.cuhk.edu.cn/projects/RaBit.