 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Critical Testing Scenarios for Decision-Making Policies: An LLM Approach
Dec 09, 2024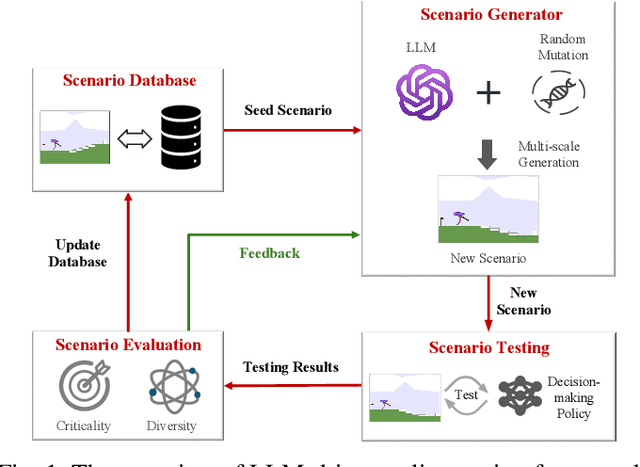
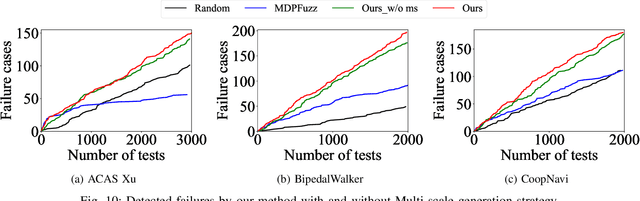
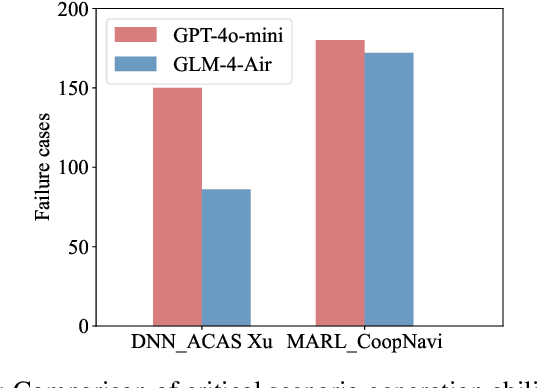

Recent years have witnessed surprising achievements of decision-making policies across various fields, such as autonomous driving and robotics. Testing for decision-making policies is crucial with the existence of critical scenarios that may threaten their reliability. Numerous research efforts have been dedicated to testing these policies. However, there are still significant challenges, such as low testing efficiency and diversity due to the complexity of the policies and environments under test. Inspired by the remarkable capabilities of large language models (LLMs), in this paper, we propose an LLM-driven online testing framework for efficiently testing decision-making policies. The main idea is to employ an LLM-based test scenario generator to intelligently generate challenging test cases through contemplation and reasoning. Specifically, we first design a "generate-test-feedback" pipeline and apply templated prompt engineering to fully leverage the knowledge and reasoning abilities of LLMs. Then, we introduce a multi-scale scenario generation strategy to address the inherent challenges LLMs face in making fine adjustments, further enhancing testing efficiency. Finally, we evaluate the LLM-driven approach on five widely used benchmarks. The experimental results demonstrate that our method significantly outperforms baseline approaches in uncovering both critical and diverse scenarios.
Towards Fault Tolerance in Multi-Agent Reinforcement Learning
Nov 30, 2024



Agent faults pose a significant threat to the performance of multi-agent reinforcement learning (MARL) algorithms, introducing two key challenges. First, agents often struggle to extract critical information from the chaotic state space created by unexpected faults. Second, transitions recorded before and after faults in the replay buffer affect training unevenly, leading to a sample imbalance problem. To overcome these challenges, this paper enhances the fault tolerance of MARL by combining optimized model architecture with a tailored training data sampling strategy. Specifically, an attention mechanism is incorporated into the actor and critic networks to automatically detect faults and dynamically regulate the attention given to faulty agents. Additionally, a prioritization mechanism is introduced to selectively sample transitions critical to current training needs. To further support research in this area, we design and open-source a highly decoupled code platform for fault-tolerant MARL, aimed at improving the efficiency of studying related problems. Experimental results demonstrate the effectiveness of our method in handling various types of faults, faults occurring in any agent, and faults arising at random times.
Synthetic Datasets for Autonomous Driving: A Survey
Apr 24, 2023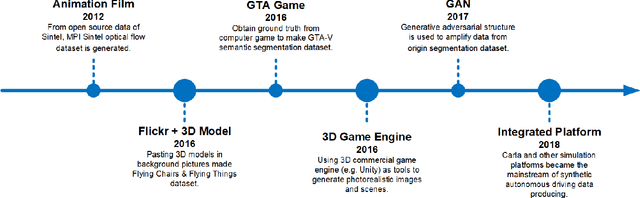



Autonomous driving techniques have been flourishing in recent years while thirsting for huge amounts of high-quality data. However, it is difficult for real-world datasets to keep up with the pace of changing requirements due to their expensive and time-consuming experimental and labeling costs. Therefore, more and more researchers are turning to synthetic datasets to easily generate rich and changeable data as an effective complement to the real world and to improve the performance of algorithms. In this paper, we summarize the evolution of synthetic dataset generation methods and review the work to date in synthetic datasets related to single and multi-task categories for to autonomous driving study. We also discuss the role that synthetic dataset plays the evaluation, gap test, and positive effect in autonomous driving related algorithm testing, especially on trustworthiness and safety aspects. Finally, we discuss general trends and possible development directions. To the best of our knowledge, this is the first survey focusing on the application of synthetic datasets in autonomous driving. This survey also raises awareness of the problems of real-world deployment of autonomous driving technology and provides researchers with a possible solution.