 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Scale Feature Fusion Framework Integrating Frequency Domain and Cross-View Attention for Dual-View X-ray Security Inspections
Feb 03, 2025With the rapid development of modern transportation systems and the exponential growth of logistics volumes, intelligent X-ray-based security inspection systems play a crucial role in public safety. Although single-view X-ray equipment is widely deployed, it struggles to accurately identify contraband in complex stacking scenarios due to strong viewpoint dependency and inadequate feature representation. To address this, we propose an innovative multi-scale interactive feature fusion framework tailored for dual-view X-ray security inspection image classification. The framework comprises three core modules: the Frequency Domain Interaction Module (FDIM) enhances frequency-domain features through Fourier transform; the Multi-Scale Cross-View Feature Enhancement (MSCFE) leverages cross-view attention mechanisms to strengthen feature interactions; and the Convolutional Attention Fusion Module (CAFM) efficiently fuses features by integrating channel attention with depthwise-separable convolutions. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches across multiple backbone architectures, particularly excelling in complex scenarios with occlusions and object stacking.
Exploring Critical Testing Scenarios for Decision-Making Policies: An LLM Approach
Dec 09, 2024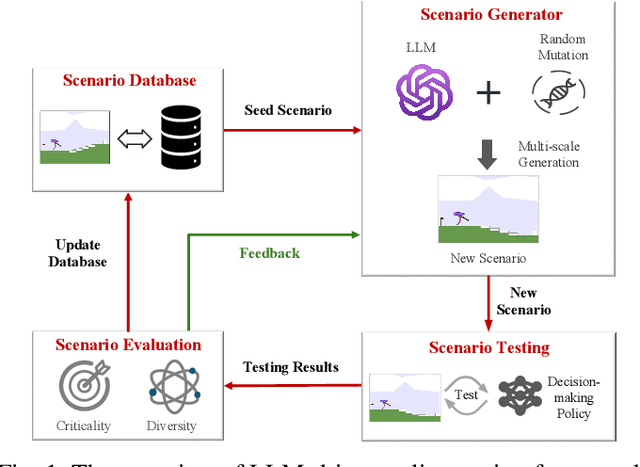
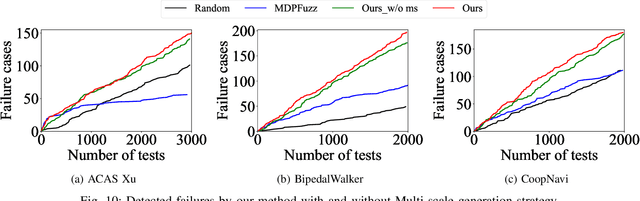
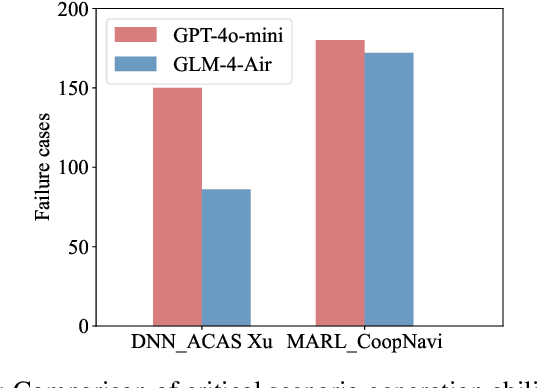

Recent years have witnessed surprising achievements of decision-making policies across various fields, such as autonomous driving and robotics. Testing for decision-making policies is crucial with the existence of critical scenarios that may threaten their reliability. Numerous research efforts have been dedicated to testing these policies. However, there are still significant challenges, such as low testing efficiency and diversity due to the complexity of the policies and environments under test. Inspired by the remarkable capabilities of large language models (LLMs), in this paper, we propose an LLM-driven online testing framework for efficiently testing decision-making policies. The main idea is to employ an LLM-based test scenario generator to intelligently generate challenging test cases through contemplation and reasoning. Specifically, we first design a "generate-test-feedback" pipeline and apply templated prompt engineering to fully leverage the knowledge and reasoning abilities of LLMs. Then, we introduce a multi-scale scenario generation strategy to address the inherent challenges LLMs face in making fine adjustments, further enhancing testing efficiency. Finally, we evaluate the LLM-driven approach on five widely used benchmarks. The experimental results demonstrate that our method significantly outperforms baseline approaches in uncovering both critical and diverse scenarios.