 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Search with Hierarchical Meta-Cognitive Monitoring Inspired by Cognitive Neuroscience
Jan 30, 2026Deep search agents powered by large language models have demonstrated strong capabilities in multi-step retrieval, reasoning, and long-horizon task execution. However, their practical failures often stem from the lack of mechanisms to monitor and regulate reasoning and retrieval states as tasks evolve under uncertainty. Insights from cognitive neuroscience suggest that human metacognition is hierarchically organized, integrating fast anomaly detection with selectively triggered, experience-driven reflection. In this work, we propose Deep Search with Meta-Cognitive Monitoring (DS-MCM), a deep search framework augmented with an explicit hierarchical metacognitive monitoring mechanism. DS-MCM integrates a Fast Consistency Monitor, which performs lightweight checks on the alignment between external evidence and internal reasoning confidence, and a Slow Experience-Driven Monitor, which is selectively activated to guide corrective intervention based on experience memory from historical agent trajectories. By embedding monitoring directly into the reasoning-retrieval loop, DS-MCM determines both when intervention is warranted and how corrective actions should be informed by prior experience. Experiments across multiple deep search benchmarks and backbone models demonstrate that DS-MCM consistently improves performance and robustness.
Exploring Critical Testing Scenarios for Decision-Making Policies: An LLM Approach
Dec 09, 2024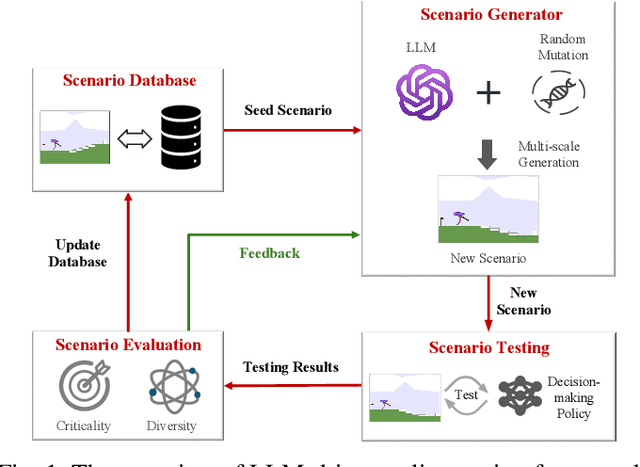
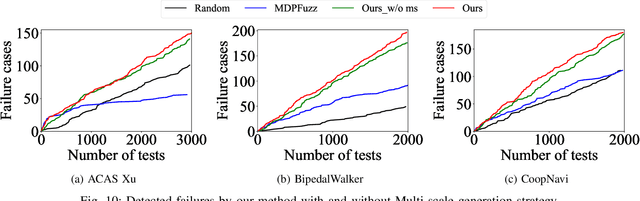
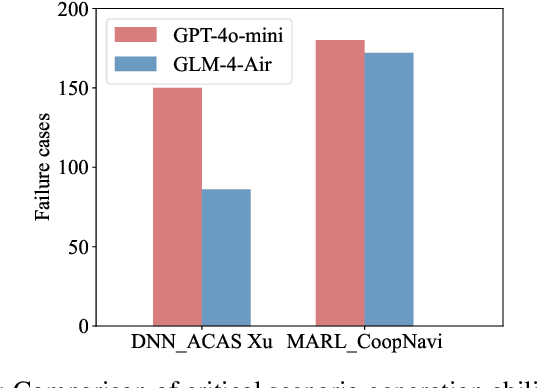

Recent years have witnessed surprising achievements of decision-making policies across various fields, such as autonomous driving and robotics. Testing for decision-making policies is crucial with the existence of critical scenarios that may threaten their reliability. Numerous research efforts have been dedicated to testing these policies. However, there are still significant challenges, such as low testing efficiency and diversity due to the complexity of the policies and environments under test. Inspired by the remarkable capabilities of large language models (LLMs), in this paper, we propose an LLM-driven online testing framework for efficiently testing decision-making policies. The main idea is to employ an LLM-based test scenario generator to intelligently generate challenging test cases through contemplation and reasoning. Specifically, we first design a "generate-test-feedback" pipeline and apply templated prompt engineering to fully leverage the knowledge and reasoning abilities of LLMs. Then, we introduce a multi-scale scenario generation strategy to address the inherent challenges LLMs face in making fine adjustments, further enhancing testing efficiency. Finally, we evaluate the LLM-driven approach on five widely used benchmarks. The experimental results demonstrate that our method significantly outperforms baseline approaches in uncovering both critical and diverse scenarios.
Accurately Predicting Probabilities of Safety-Critical Rare Events for Intelligent Systems
Mar 22, 2024



Intelligent systems are increasingly integral to our daily lives, yet rare safety-critical events present significant latent threats to their practical deployment. Addressing this challenge hinges on accurately predicting the probability of safety-critical events occurring within a given time step from the current state, a metric we define as 'criticality'. The complexity of predicting criticality arises from the extreme data imbalance caused by rare events in high dimensional variables associated with the rare events, a challenge we refer to as the curse of rarity. Existing methods tend to be either overly conservative or prone to overlooking safety-critical events, thus struggling to achieve both high precision and recall rates, which severely limits their applicability. This study endeavors to develop a criticality prediction model that excels in both precision and recall rates for evaluating the criticality of safety-critical autonomous systems. We propose a multi-stage learning framework designed to progressively densify the dataset, mitigating the curse of rarity across stages. To validate our approach, we evaluate it in two cases: lunar lander and bipedal walker scenarios. The results demonstrate that our method surpasses traditional approaches, providing a more accurate and dependable assessment of criticality in intelligent systems.
Adaptive Testing Environment Generation for Connected and Automated Vehicles with Dense Reinforcement Learning
Feb 29, 2024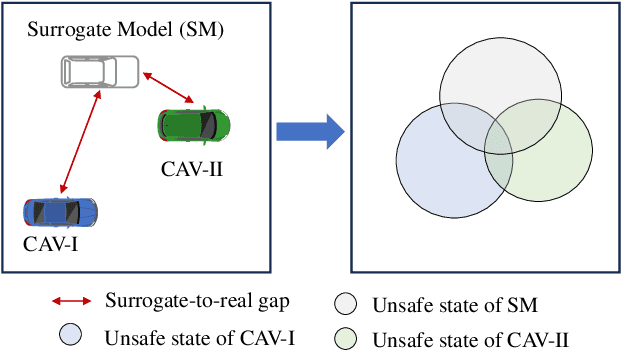
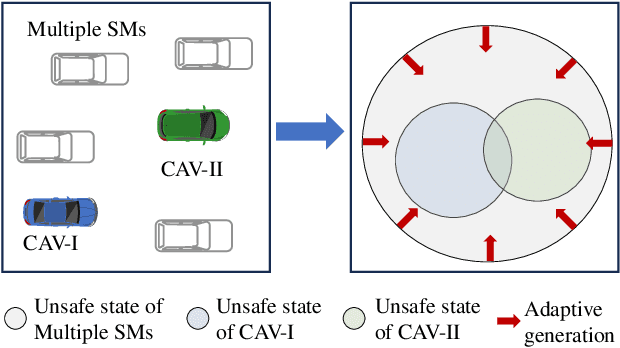
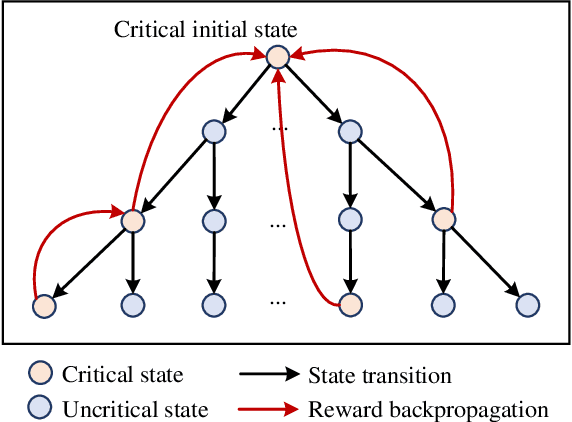
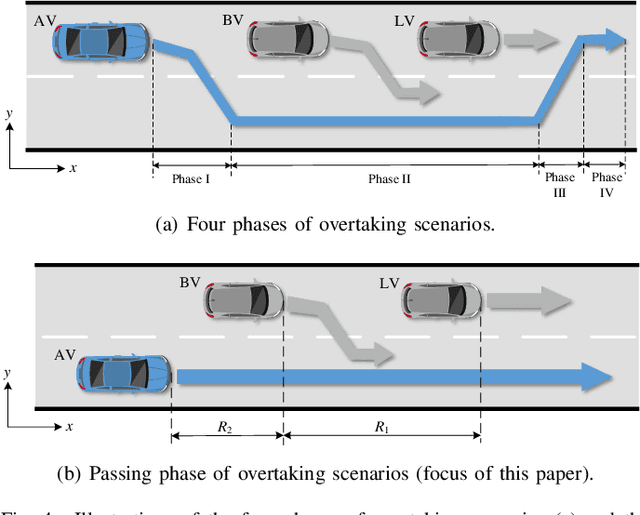
The assessment of safety performance plays a pivotal role in the development and deployment of connected and automated vehicles (CAVs). A common approach involves designing testing scenarios based on prior knowledge of CAVs (e.g., surrogate models), conducting tests in these scenarios, and subsequently evaluating CAVs' safety performances. However, substantial differences between CAVs and the prior knowledge can significantly diminish the evaluation efficiency. In response to this issue, existing studies predominantly concentrate on the adaptive design of testing scenarios during the CAV testing process. Yet, these methods have limitations in their applicability to high-dimensional scenarios. To overcome this challenge, we develop an adaptive testing environment that bolsters evaluation robustness by incorporating multiple surrogate models and optimizing the combination coefficients of these surrogate models to enhance evaluation efficiency. We formulate the optimization problem as a regression task utilizing quadratic programming. To efficiently obtain the regression target via reinforcement learning, we propose the dense reinforcement learning method and devise a new adaptive policy with high sample efficiency. Essentially, our approach centers on learning the values of critical scenes displaying substantial surrogate-to-real gaps. The effectiveness of our method is validated in high-dimensional overtaking scenarios, demonstrating that our approach achieves notable evaluation efficiency.
Few-Shot Scenario Testing for Autonomous Vehicles Based on Neighborhood Coverage and Similarity
Feb 02, 2024Testing and evaluating the safety performance of autonomous vehicles (AVs) is essential before the large-scale deployment. Practically, the acceptable cost of testing specific AV model can be restricted within an extremely small limit because of testing cost or time. With existing testing methods, the limitations imposed by strictly restricted testing numbers often result in significant uncertainties or challenges in quantifying testing results. In this paper, we formulate this problem for the first time the "few-shot testing" (FST) problem and propose a systematic FST framework to address this challenge. To alleviate the considerable uncertainty inherent in a small testing scenario set and optimize scenario utilization, we frame the FST problem as an optimization problem and search for a small scenario set based on neighborhood coverage and similarity. By leveraging the prior information on surrogate models (SMs), we dynamically adjust the testing scenario set and the contribution of each scenario to the testing result under the guidance of better generalization ability on AVs. With certain hypotheses on SMs, a theoretical upper bound of testing error is established to verify the sufficiency of testing accuracy within given limited number of tests. The experiments of the cut-in scenario using FST method demonstrate a notable reduction in testing error and variance compared to conventional testing methods, especially for situations with a strict limitation on the number of scenarios.
A Joint Model for Dropped Pronoun Recovery and Conversational Discourse Parsing in Chinese Conversational Speech
Jun 07, 2021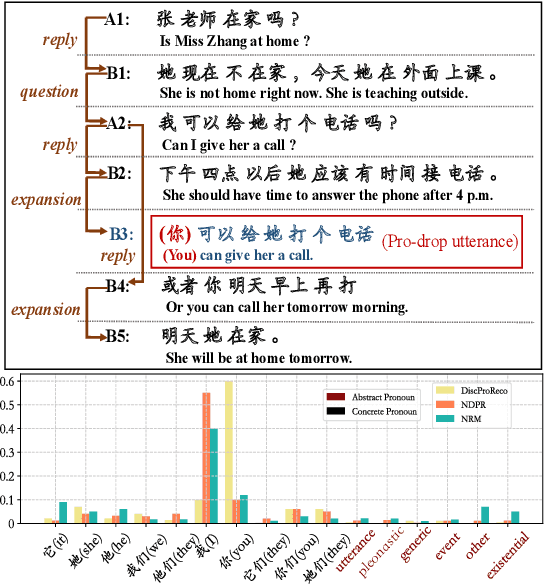
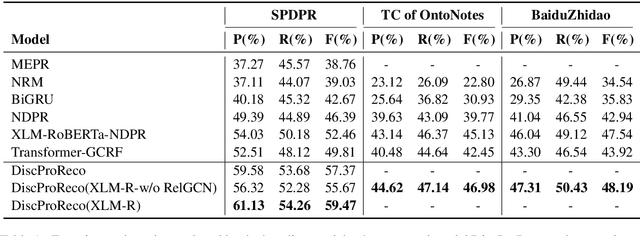
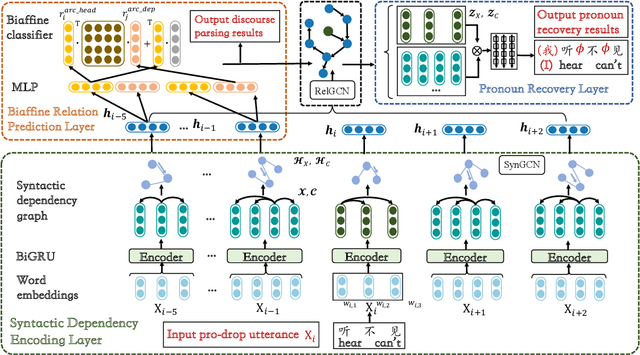
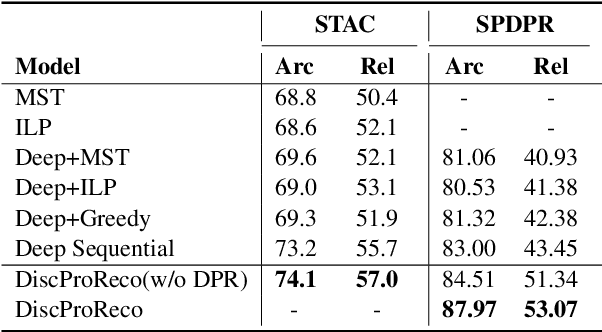
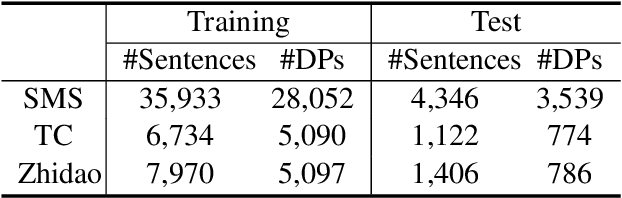
In this paper, we present a neural model for joint dropped pronoun recovery (DPR) and conversational discourse parsing (CDP) in Chinese conversational speech. We show that DPR and CDP are closely related, and a joint model benefits both tasks. We refer to our model as DiscProReco, and it first encodes the tokens in each utterance in a conversation with a directed Graph Convolutional Network (GCN). The token states for an utterance are then aggregated to produce a single state for each utterance. The utterance states are then fed into a biaffine classifier to construct a conversational discourse graph. A second (multi-relational) GCN is then applied to the utterance states to produce a discourse relation-augmented representation for the utterances, which are then fused together with token states in each utterance as input to a dropped pronoun recovery layer. The joint model is trained and evaluated on a new Structure Parsing-enhanced Dropped Pronoun Recovery (SPDPR) dataset that we annotated with both two types of information. Experimental results on the SPDPR dataset and other benchmarks show that DiscProReco significantly outperforms the state-of-the-art baselines of both tasks.
Transformer-GCRF: Recovering Chinese Dropped Pronouns with General Conditional Random Fields
Oct 07, 2020
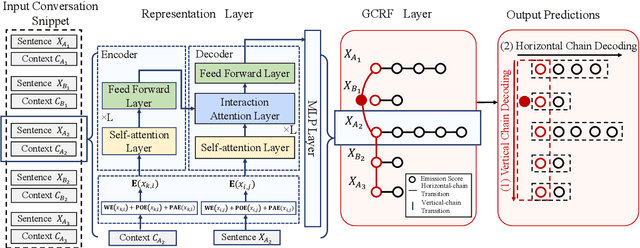
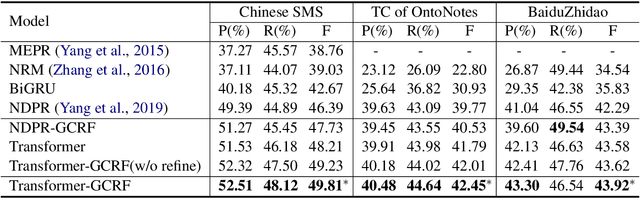
Pronouns are often dropped in Chinese conversations and recovering the dropped pronouns is important for NLP applications such as Machine Translation. Existing approaches usually formulate this as a sequence labeling task of predicting whether there is a dropped pronoun before each token and its type. Each utterance is considered to be a sequence and labeled independently. Although these approaches have shown promise, labeling each utterance independently ignores the dependencies between pronouns in neighboring utterances. Modeling these dependencies is critical to improving the performance of dropped pronoun recovery. In this paper, we present a novel framework that combines the strength of Transformer network with General Conditional Random Fields (GCRF) to model the dependencies between pronouns in neighboring utterances. Results on three Chinese conversation datasets show that the Transformer-GCRF model outperforms the state-of-the-art dropped pronoun recovery models. Exploratory analysis also demonstrates that the GCRF did help to capture the dependencies between pronouns in neighboring utterances, thus contributes to the performance improvements.
Recovering Dropped Pronouns in Chinese Conversations via Modeling Their Referents
May 17, 2019
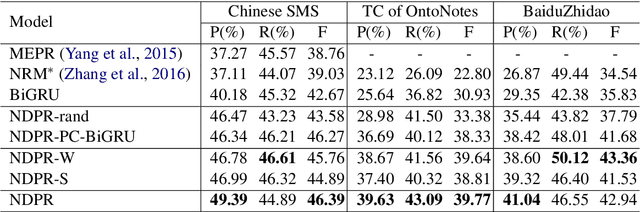
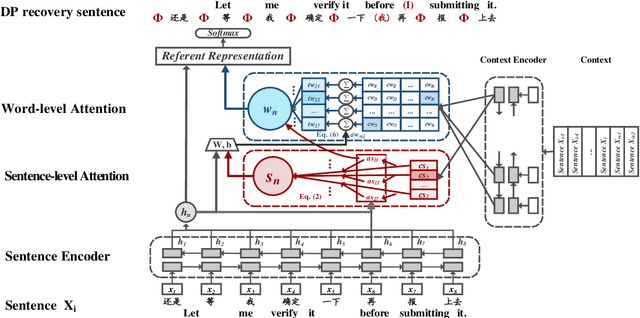
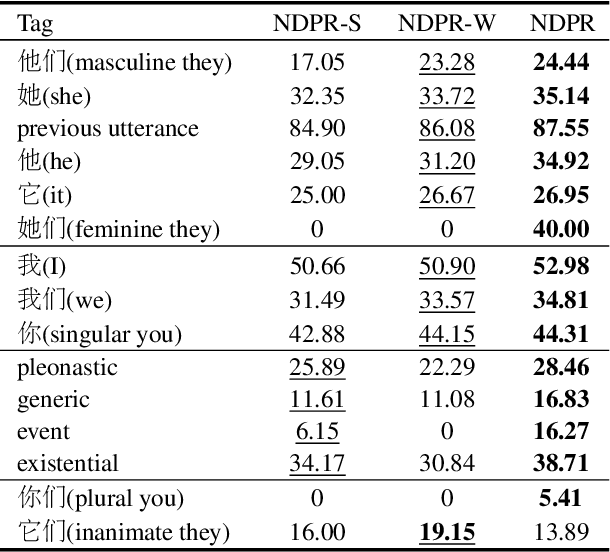
Pronouns are often dropped in Chinese sentences, and this happens more frequently in conversational genres as their referents can be easily understood from context. Recovering dropped pronouns is essential to applications such as Information Extraction where the referents of these dropped pronouns need to be resolved, or Machine Translation when Chinese is the source language. In this work, we present a novel end-to-end neural network model to recover dropped pronouns in conversational data. Our model is based on a structured attention mechanism that models the referents of dropped pronouns utilizing both sentence-level and word-level information. Results on three different conversational genres show that our approach achieves a significant improvement over the current state of the art.
Pre-training of Context-aware Item Representation for Next Basket Recommendation
Apr 14, 2019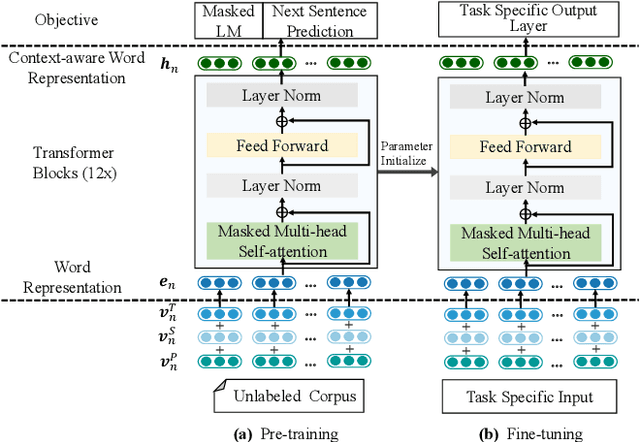
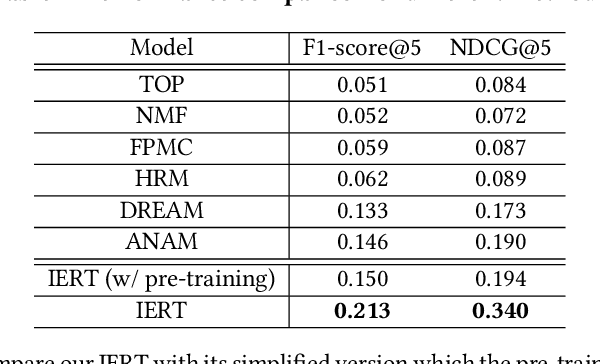
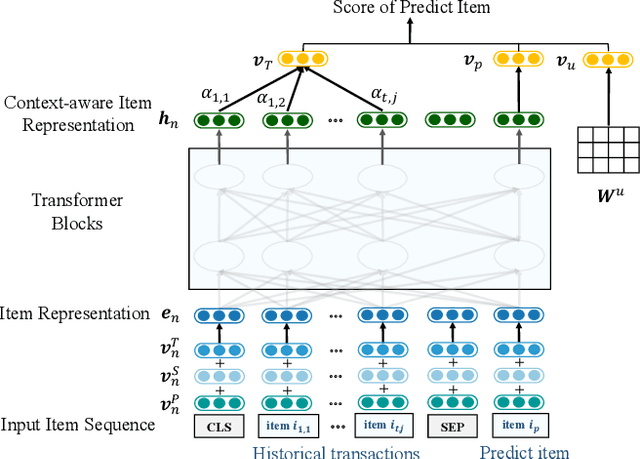
Next basket recommendation, which aims to predict the next a few items that a user most probably purchases given his historical transactions, plays a vital role in market basket analysis. From the viewpoint of item, an item could be purchased by different users together with different items, for different reasons. Therefore, an ideal recommender system should represent an item considering its transaction contexts. Existing state-of-the-art deep learning methods usually adopt the static item representations, which are invariant among all of the transactions and thus cannot achieve the full potentials of deep learning. Inspired by the pre-trained representations of BERT in natural language processing, we propose to conduct context-aware item representation for next basket recommendation, called Item Encoder Representations from Transformers (IERT). In the offline phase, IERT pre-trains deep item representations conditioning on their transaction contexts. In the online recommendation phase, the pre-trained model is further fine-tuned with an additional output layer. The output contextualized item embeddings are used to capture users' sequential behaviors and general tastes to conduct recommendation. Experimental results on the Ta-Feng data set show that IERT outperforms the state-of-the-art baseline methods, which demonstrated the effectiveness of IERT in next basket representation.