 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kind Introduction to Lexical and Grammatical Aspect, with a Survey of Computational Approaches
Aug 18, 2022
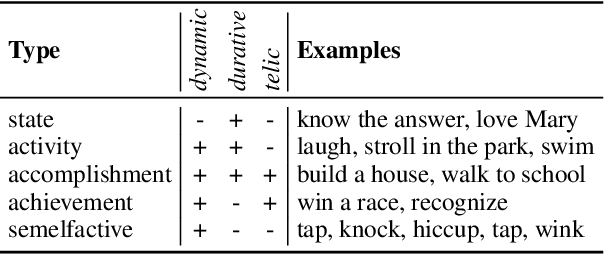

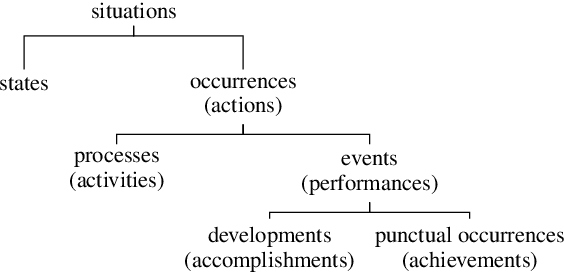
Aspectual meaning refers to how the internal temporal structure of situations is presented. This includes whether a situation is described as a state or as an event, whether the situation is finished or ongoing, and whether it is viewed as a whole or with a focus on a particular phase. This survey gives an overview of computational approaches to modeling lexical and grammatical aspect along with intuitive explanations of the necessary linguistic concepts and terminology. In particular, we describe the concepts of stativity, telicity, habituality, perfective and imperfective, as well as influential inventories of eventuality and situation types. We argue that because aspect is a crucial component of semantics, especially when it comes to reporting the temporal structure of situations in a precise way, future NLP approaches need to be able to handle and evaluate it systematically in order to achieve human-level language understanding.
A Joint Model for Dropped Pronoun Recovery and Conversational Discourse Parsing in Chinese Conversational Speech
Jun 07, 2021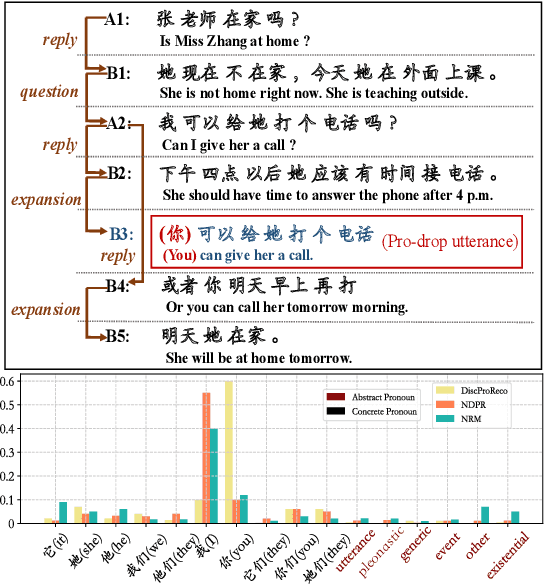
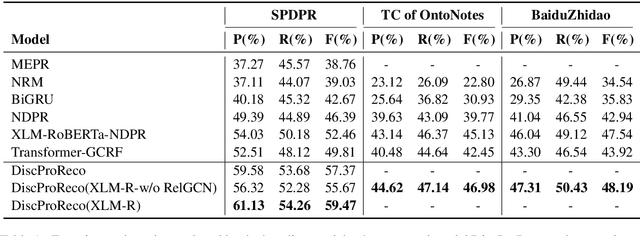
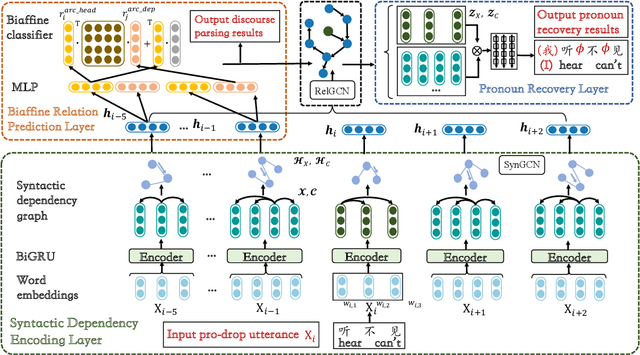
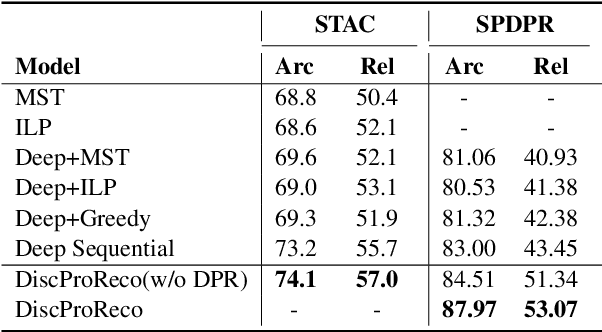
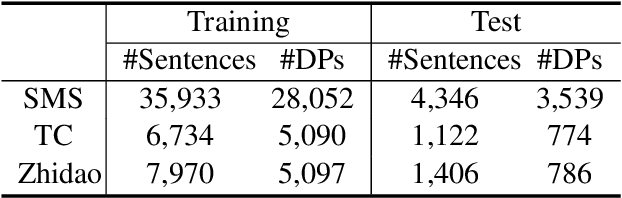
In this paper, we present a neural model for joint dropped pronoun recovery (DPR) and conversational discourse parsing (CDP) in Chinese conversational speech. We show that DPR and CDP are closely related, and a joint model benefits both tasks. We refer to our model as DiscProReco, and it first encodes the tokens in each utterance in a conversation with a directed Graph Convolutional Network (GCN). The token states for an utterance are then aggregated to produce a single state for each utterance. The utterance states are then fed into a biaffine classifier to construct a conversational discourse graph. A second (multi-relational) GCN is then applied to the utterance states to produce a discourse relation-augmented representation for the utterances, which are then fused together with token states in each utterance as input to a dropped pronoun recovery layer. The joint model is trained and evaluated on a new Structure Parsing-enhanced Dropped Pronoun Recovery (SPDPR) dataset that we annotated with both two types of information. Experimental results on the SPDPR dataset and other benchmarks show that DiscProReco significantly outperforms the state-of-the-art baselines of both tasks.
Transformer-GCRF: Recovering Chinese Dropped Pronouns with General Conditional Random Fields
Oct 07, 2020
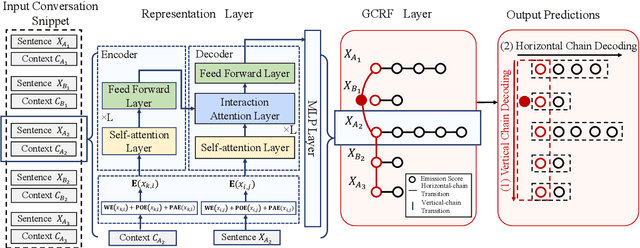
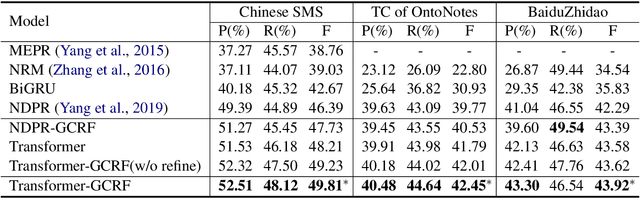
Pronouns are often dropped in Chinese conversations and recovering the dropped pronouns is important for NLP applications such as Machine Translation. Existing approaches usually formulate this as a sequence labeling task of predicting whether there is a dropped pronoun before each token and its type. Each utterance is considered to be a sequence and labeled independently. Although these approaches have shown promise, labeling each utterance independently ignores the dependencies between pronouns in neighboring utterances. Modeling these dependencies is critical to improving the performance of dropped pronoun recovery. In this paper, we present a novel framework that combines the strength of Transformer network with General Conditional Random Fields (GCRF) to model the dependencies between pronouns in neighboring utterances. Results on three Chinese conversation datasets show that the Transformer-GCRF model outperforms the state-of-the-art dropped pronoun recovery models. Exploratory analysis also demonstrates that the GCRF did help to capture the dependencies between pronouns in neighboring utterances, thus contributes to the performance improvements.
Recovering Dropped Pronouns in Chinese Conversations via Modeling Their Referents
May 17, 2019
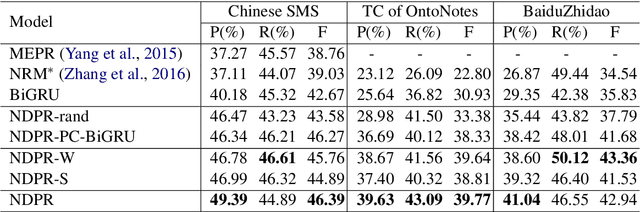
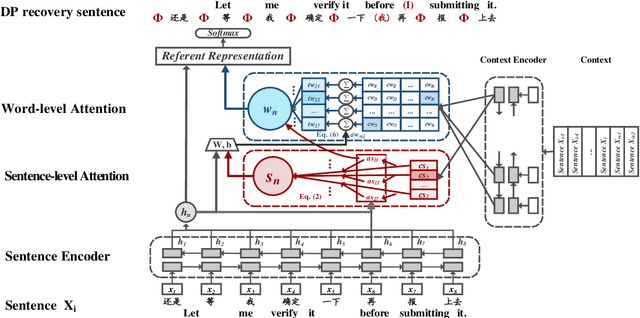
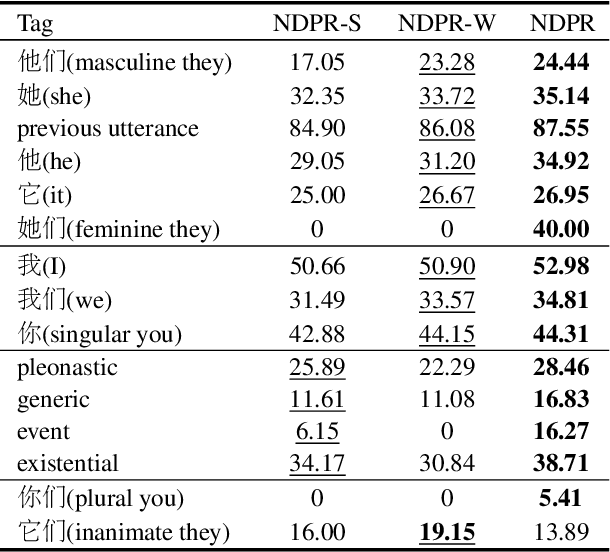
Pronouns are often dropped in Chinese sentences, and this happens more frequently in conversational genres as their referents can be easily understood from context. Recovering dropped pronouns is essential to applications such as Information Extraction where the referents of these dropped pronouns need to be resolved, or Machine Translation when Chinese is the source language. In this work, we present a novel end-to-end neural network model to recover dropped pronouns in conversational data. Our model is based on a structured attention mechanism that models the referents of dropped pronouns utilizing both sentence-level and word-level information. Results on three different conversational genres show that our approach achieves a significant improvement over the current state of the art.
Neural Ranking Models for Temporal Dependency Structure Parsing
Sep 02, 2018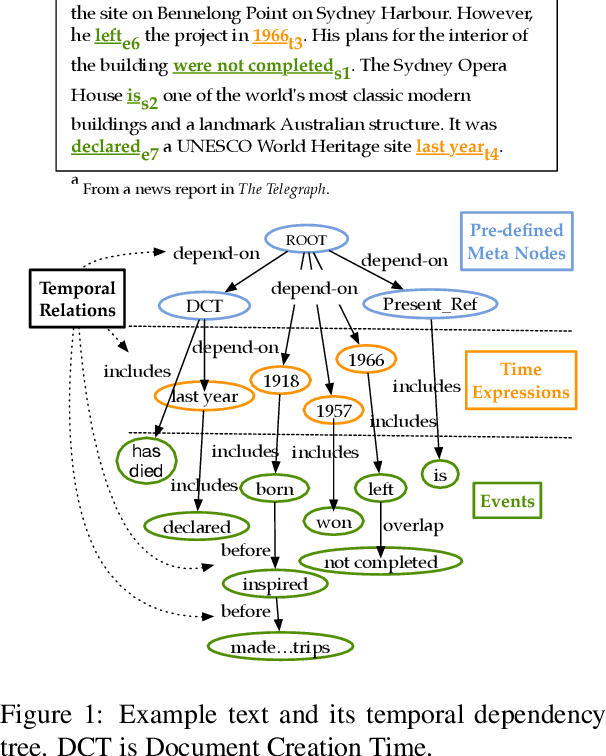

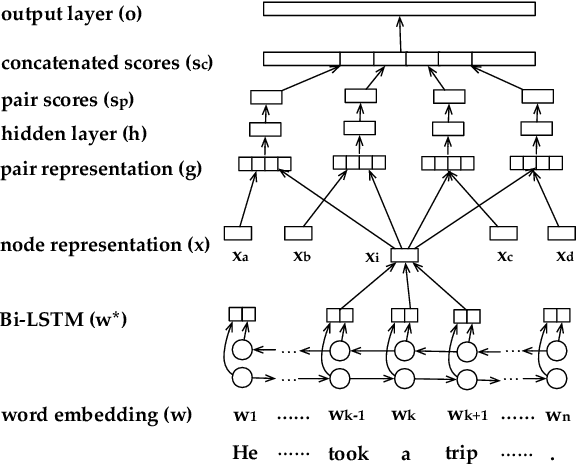

We design and build the first neural temporal dependency parser. It utilizes a neural ranking model with minimal feature engineering, and parses time expressions and events in a text into a temporal dependency tree structure. We evaluate our parser on two domains: news reports and narrative stories. In a parsing-only evaluation setup where gold time expressions and events are provided, our parser reaches 0.81 and 0.70 f-score on unlabeled and labeled parsing respectively, a result that is very competitive against alternative approaches. In an end-to-end evaluation setup where time expressions and events are automatically recognized, our parser beats two strong baselines on both data domains. Our experimental results and discussions shed light on the nature of temporal dependency structures in different domains and provide insights that we believe will be valuable to future research in this area.
Structured Interpretation of Temporal Relations
Aug 23, 2018


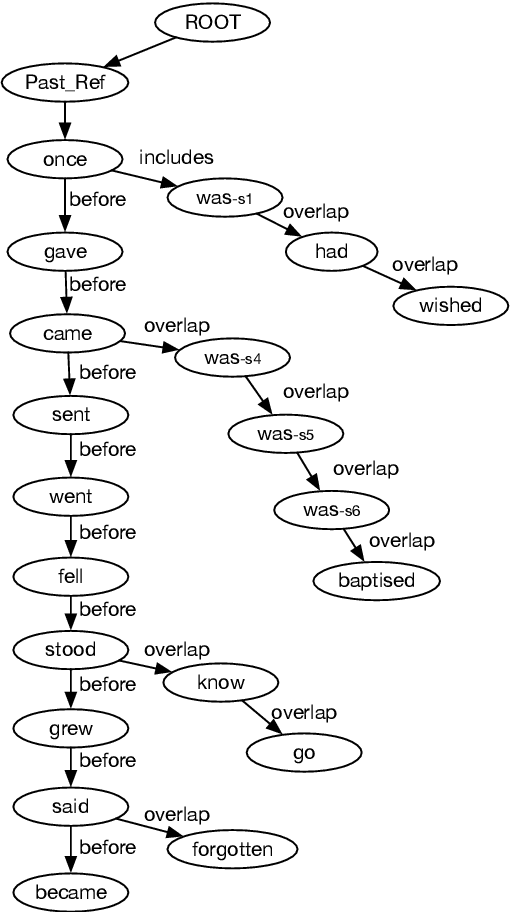
Temporal relations between events and time expressions in a document are often modeled in an unstructured manner where relations between individual pairs of time expressions and events are considered in isolation. This often results in inconsistent and incomplete annotation and computational modeling. We propose a novel annotation approach where events and time expressions in a document form a dependency tree in which each dependency relation corresponds to an instance of temporal anaphora where the antecedent is the parent and the anaphor is the child. We annotate a corpus of 235 documents using this approach in the two genres of news and narratives, with 48 documents doubly annotated. We report a stable and high inter-annotator agreement on the doubly annotated subset, validating our approach, and perform a quantitative comparison between the two genres of the entire corpus. We make this corpus publicly available.
* 9 pages, 2 figures, 8 tables, LREC-2018
Addressing the Data Sparsity Issue in Neural AMR Parsing
Feb 16, 2017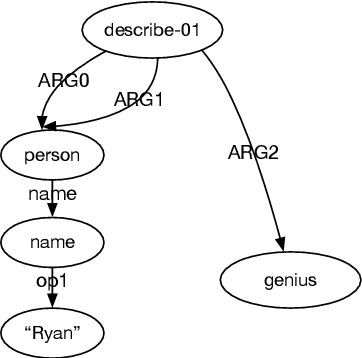
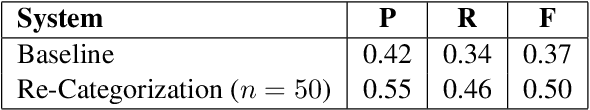

Neural attention models have achieved great success in different NLP tasks. How- ever, they have not fulfilled their promise on the AMR parsing task due to the data sparsity issue. In this paper, we de- scribe a sequence-to-sequence model for AMR parsing and present different ways to tackle the data sparsity problem. We show that our methods achieve significant improvement over a baseline neural atten- tion model and our results are also compet- itive against state-of-the-art systems that do not use extra linguistic resources.
Towards Accurate Word Segmentation for Chinese Patents
Nov 30, 2016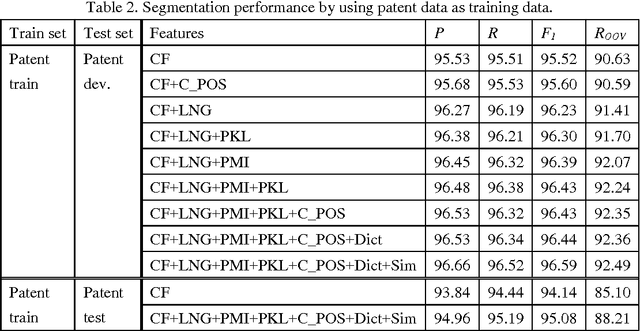
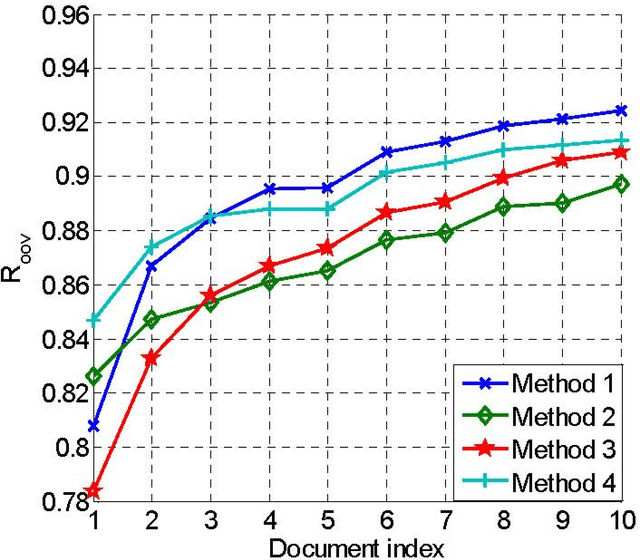
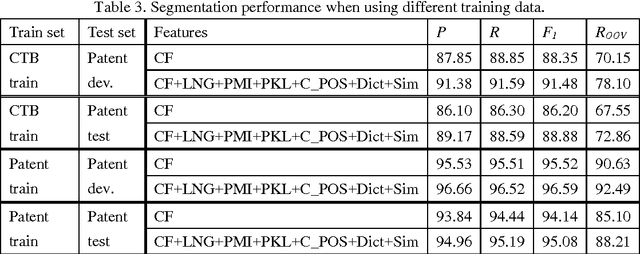
A patent is a property right for an invention granted by the government to the inventor. An invention is a solution to a specific technological problem. So patents often have a high concentration of scientific and technical terms that are rare in everyday language. The Chinese word segmentation model trained on currently available everyday language data sets performs poorly because it cannot effectively recognize these scientific and technical terms. In this paper we describe a pragmatic approach to Chinese word segmentation on patents where we train a character-based semi-supervised sequence labeling model by extracting features from a manually segmented corpus of 142 patents, enhanced with information extracted from the Chinese TreeBank. Experiments show that the accuracy of our model reached 95.08% (F1 score) on a held-out test set and 96.59% on development set, compared with an F1 score of 91.48% on development set if the model is trained on the Chinese TreeBank. We also experimented with some existing domain adaptation techniques, the results show that the amount of target domain data and the selected features impact the performance of the domain adaptation techniques.
Neural Network Models for Implicit Discourse Relation Classification in English and Chinese without Surface Features
Jun 07, 2016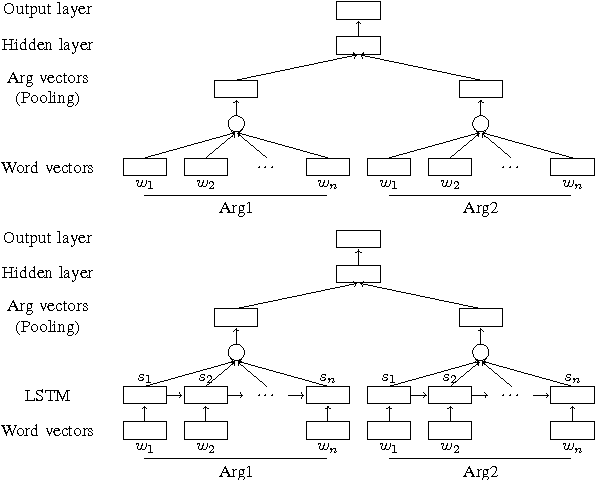

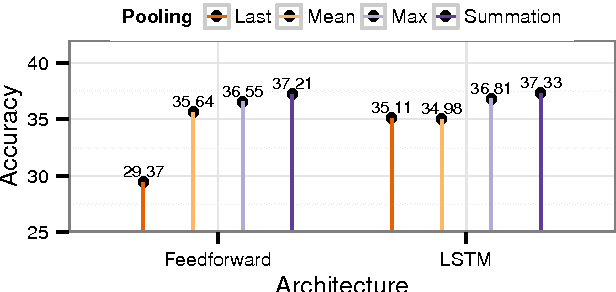
Inferring implicit discourse relations in natural language text is the most difficult subtask in discourse parsing. Surface features achieve good performance, but they are not readily applicable to other languages without semantic lexicons. Previous neural models require parses, surface features, or a small label set to work well. Here, we propose neural network models that are based on feedforward and long-short term memory architecture without any surface features. To our surprise, our best configured feedforward architecture outperforms LSTM-based model in most cases despite thorough tuning. Under various fine-grained label sets and a cross-linguistic setting, our feedforward models perform consistently better or at least just as well as systems that require hand-crafted surface features. Our models present the first neural Chinese discourse parser in the style of Chinese Discourse Treebank, showing that our results hold cross-linguistically.