 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Word Segmentation for Chinese Patents
Paper and Code
Nov 30, 2016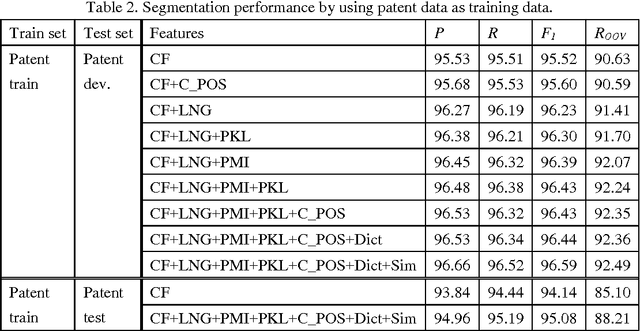
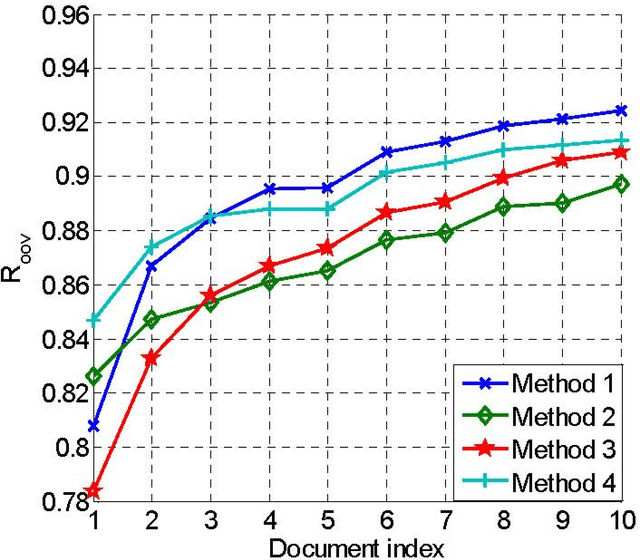
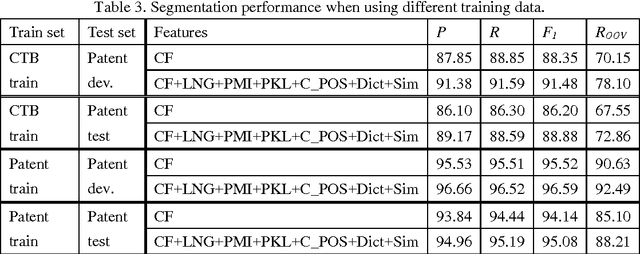
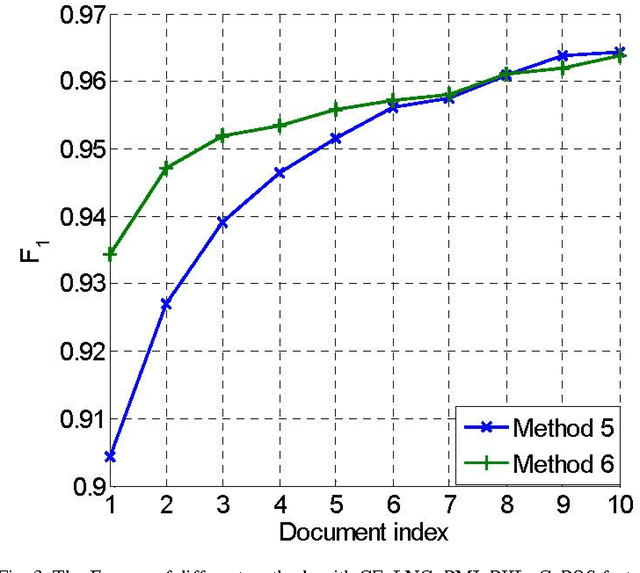
A patent is a property right for an invention granted by the government to the inventor. An invention is a solution to a specific technological problem. So patents often have a high concentration of scientific and technical terms that are rare in everyday language. The Chinese word segmentation model trained on currently available everyday language data sets performs poorly because it cannot effectively recognize these scientific and technical terms. In this paper we describe a pragmatic approach to Chinese word segmentation on patents where we train a character-based semi-supervised sequence labeling model by extracting features from a manually segmented corpus of 142 patents, enhanced with information extracted from the Chinese TreeBank. Experiments show that the accuracy of our model reached 95.08% (F1 score) on a held-out test set and 96.59% on development set, compared with an F1 score of 91.48% on development set if the model is trained on the Chinese TreeBank. We also experimented with some existing domain adaptation techniques, the results show that the amount of target domain data and the selected features impact the performance of the domain adaptation techniques.