 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reinforcement Learning for Content Moderation with Large Language Models
Dec 23, 2025
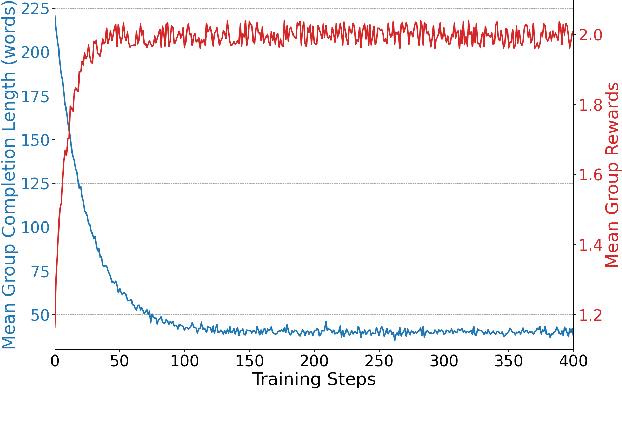
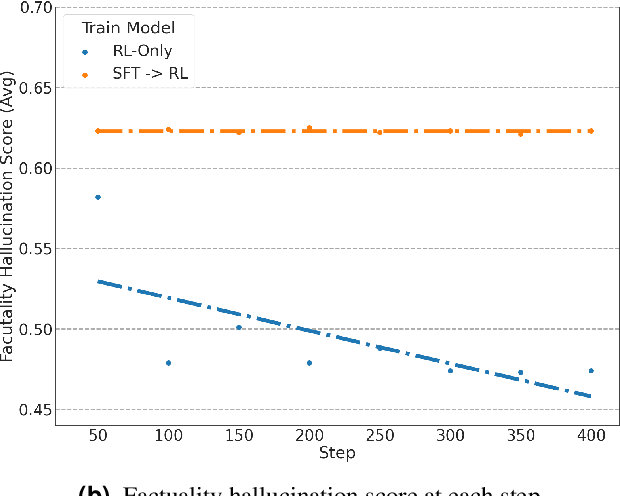
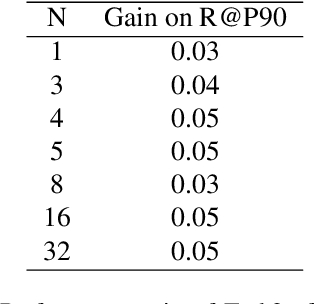
Content moderation at scale remains one of the most pressing challenges in today's digital ecosystem, where billions of user- and AI-generated artifacts must be continuously evaluated for policy violations. Although recent advances in large language models (LLMs) have demonstrated strong potential for policy-grounded moderation, the practical challenges of training these systems to achieve expert-level accuracy in real-world settings remain largely unexplored, particularly in regimes characterized by label sparsity, evolving policy definitions, and the need for nuanced reasoning beyond shallow pattern matching. In this work, we present a comprehensive empirical investigation of scaling reinforcement learning (RL) for content classification, systematically evaluating multiple RL training recipes and reward-shaping strategies-including verifiable rewards and LLM-as-judge frameworks-to transform general-purpose language models into specialized, policy-aligned classifiers across three real-world content moderation tasks. Our findings provide actionable insights for industrial-scale moderation systems, demonstrating that RL exhibits sigmoid-like scaling behavior in which performance improves smoothly with increased training data, rollouts, and optimization steps before gradually saturating. Moreover, we show that RL substantially improves performance on tasks requiring complex policy-grounded reasoning while achieving up to 100x higher data efficiency than supervised fine-tuning, making it particularly effective in domains where expert annotations are scarce or costly.
FRAME: Evaluating Simulatability Metrics for Free-Text Rationales
Jul 02, 2022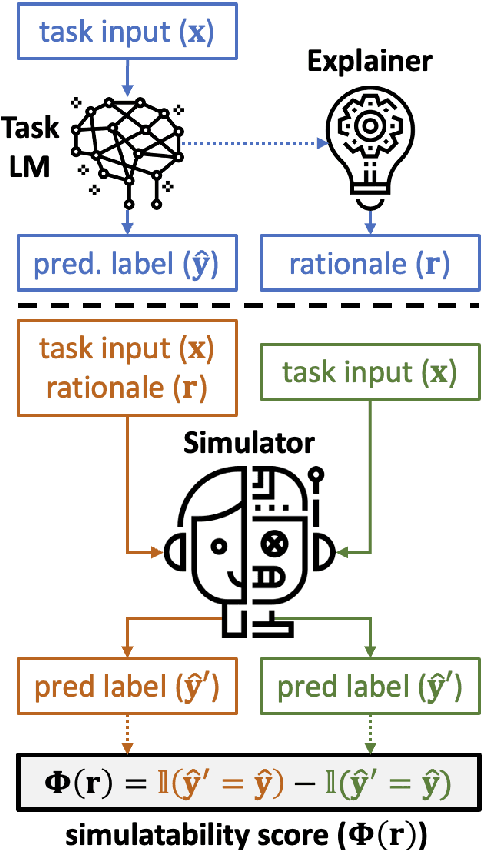
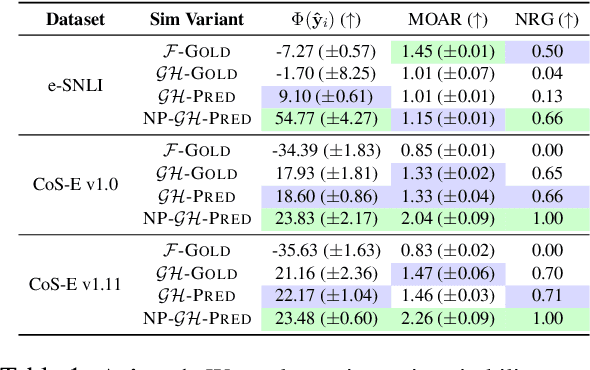

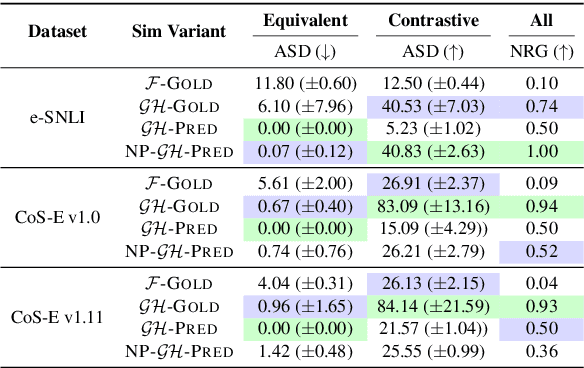
Free-text rationales aim to explain neural language model (LM) behavior more flexibly and intuitively via natural language. To ensure rationale quality, it is important to have metrics for measuring rationales' faithfulness (reflects LM's actual behavior) and plausibility (convincing to humans). All existing free-text rationale metrics are based on simulatability (association between rationale and LM's predicted label), but there is no protocol for assessing such metrics' reliability. To investigate this, we propose FRAME, a framework for evaluating free-text rationale simulatability metrics. FRAME is based on three axioms: (1) good metrics should yield highest scores for reference rationales, which maximize rationale-label association by construction; (2) good metrics should be appropriately sensitive to semantic perturbation of rationales; and (3) good metrics should be robust to variation in the LM's task performance. Across three text classification datasets, we show that existing simulatability metrics cannot satisfy all three FRAME axioms, since they are implemented via model pretraining which muddles the metric's signal. We introduce a non-pretraining simulatability variant that improves performance on (1) and (3) by an average of 41.7% and 42.9%, respectively, while performing competitively on (2).
UniREx: A Unified Learning Framework for Language Model Rationale Extraction
Dec 16, 2021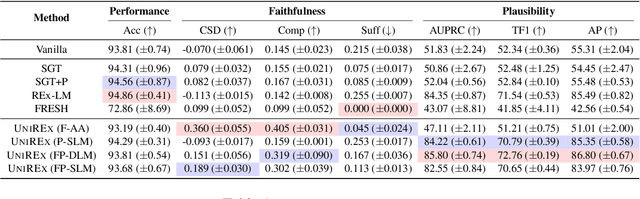
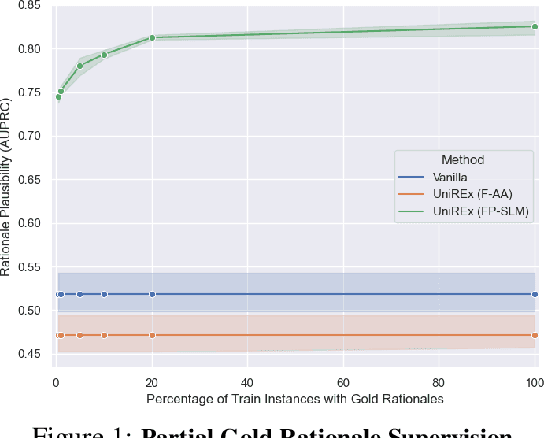
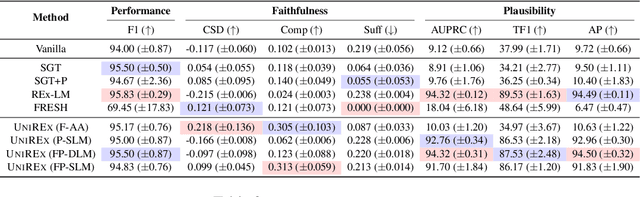
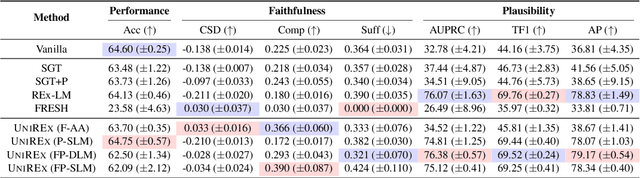
An extractive rationale explains a language model's (LM's) prediction on a given task instance by highlighting the text inputs that most influenced the output. Ideally, rationale extraction should be faithful (reflects LM's behavior), plausible (makes sense to humans), data-efficient, and fast, without sacrificing the LM's task performance. Prior rationale extraction works consist of specialized approaches for addressing various subsets of these desiderata -- but never all five. Narrowly focusing on certain desiderata typically comes at the expense of ignored ones, so existing rationale extractors are often impractical in real-world applications. To tackle this challenge, we propose UniREx, a unified and highly flexible learning framework for rationale extraction, which allows users to easily account for all five factors. UniREx enables end-to-end customization of the rationale extractor training process, supporting arbitrary: (1) heuristic/learned rationale extractors, (2) combinations of faithfulness and/or plausibility objectives, and (3) amounts of gold rationale supervision. Across three text classification datasets, our best UniREx configurations achieve a superior balance of the five desiderata, when compared to strong baselines. Furthermore, UniREx-trained rationale extractors can even generalize to unseen datasets and tasks.
AMR-to-text Generation with Synchronous Node Replacement Grammar
Apr 28, 2017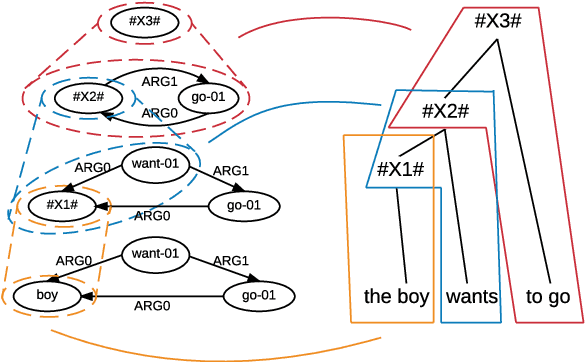


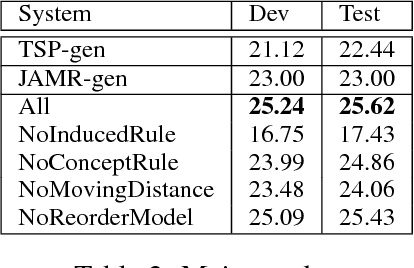
This paper addresses the task of AMR-to-text generation by leveraging synchronous node replacement grammar. During training, graph-to-string rules are learned using a heuristic extraction algorithm. At test time, a graph transducer is applied to collapse input AMRs and generate output sentences. Evaluated on SemEval-2016 Task 8, our method gives a BLEU score of 25.62, which is the best reported so far.
Addressing the Data Sparsity Issue in Neural AMR Parsing
Feb 16, 2017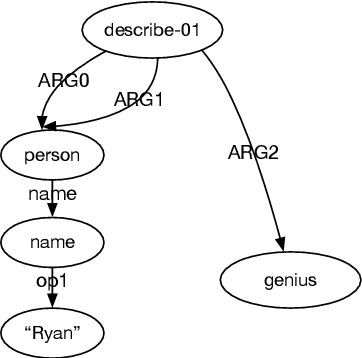
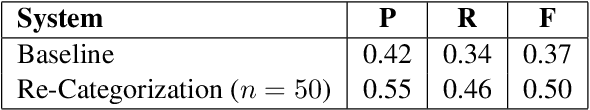

Neural attention models have achieved great success in different NLP tasks. How- ever, they have not fulfilled their promise on the AMR parsing task due to the data sparsity issue. In this paper, we de- scribe a sequence-to-sequence model for AMR parsing and present different ways to tackle the data sparsity problem. We show that our methods achieve significant improvement over a baseline neural atten- tion model and our results are also compet- itive against state-of-the-art systems that do not use extra linguistic resources.
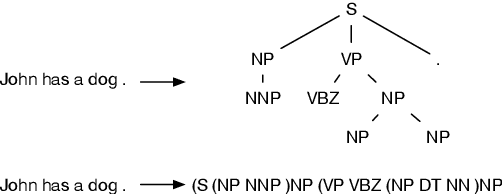
AMR-to-text generation as a Traveling Salesman Problem
Sep 23, 2016
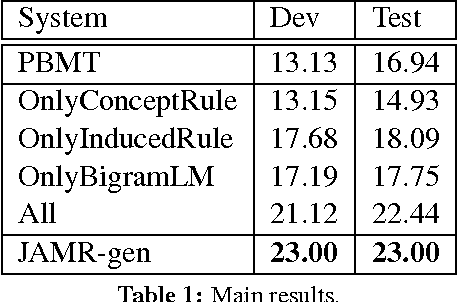


The task of AMR-to-text generation is to generate grammatical text that sustains the semantic meaning for a given AMR graph. We at- tack the task by first partitioning the AMR graph into smaller fragments, and then generating the translation for each fragment, before finally deciding the order by solving an asymmetric generalized traveling salesman problem (AGTSP). A Maximum Entropy classifier is trained to estimate the traveling costs, and a TSP solver is used to find the optimized solution. The final model reports a BLEU score of 22.44 on the SemEval-2016 Task8 dataset.
Exploring phrase-compositionality in skip-gram models
Jul 21, 2016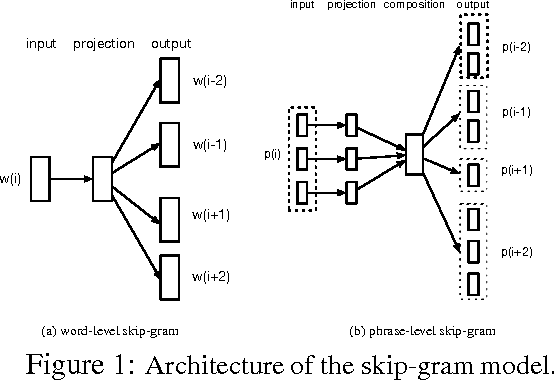

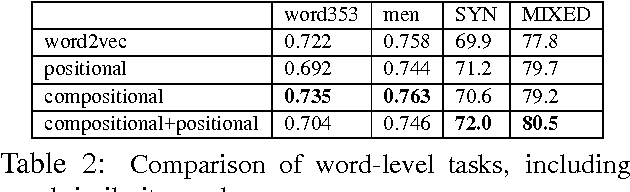
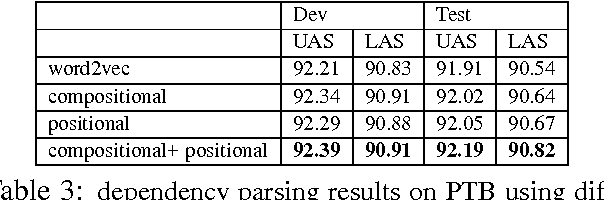
In this paper, we introduce a variation of the skip-gram model which jointly learns distributed word vector representations and their way of composing to form phrase embeddings. In particular, we propose a learning procedure that incorporates a phrase-compositionality function which can capture how we want to compose phrases vectors from their component word vectors. Our experiments show improvement in word and phrase similarity tasks as well as syntactic tasks like dependency parsing using the proposed joint models.