 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reinforcement Learning for Content Moderation with Large Language Models
Dec 23, 2025
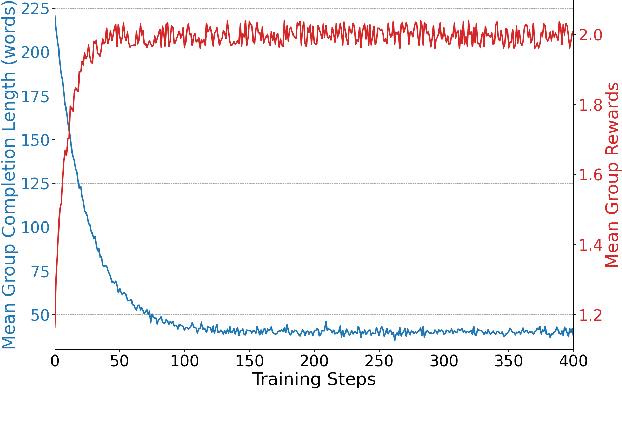
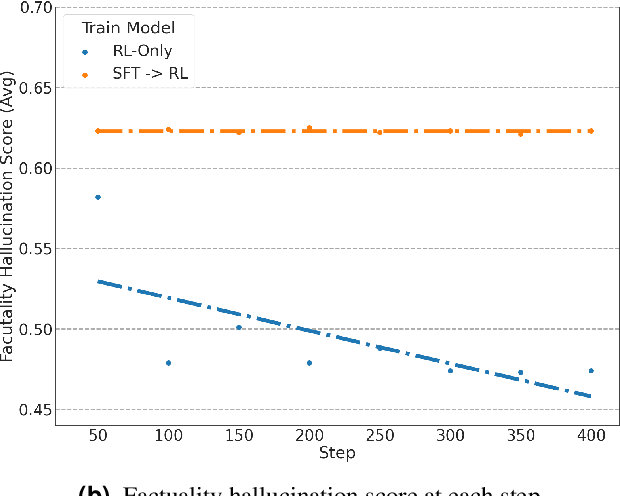
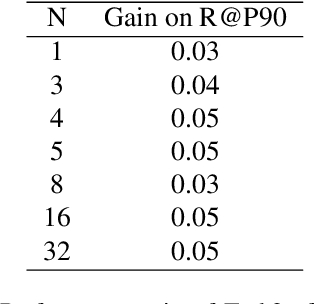
Content moderation at scale remains one of the most pressing challenges in today's digital ecosystem, where billions of user- and AI-generated artifacts must be continuously evaluated for policy violations. Although recent advances in large language models (LLMs) have demonstrated strong potential for policy-grounded moderation, the practical challenges of training these systems to achieve expert-level accuracy in real-world settings remain largely unexplored, particularly in regimes characterized by label sparsity, evolving policy definitions, and the need for nuanced reasoning beyond shallow pattern matching. In this work, we present a comprehensive empirical investigation of scaling reinforcement learning (RL) for content classification, systematically evaluating multiple RL training recipes and reward-shaping strategies-including verifiable rewards and LLM-as-judge frameworks-to transform general-purpose language models into specialized, policy-aligned classifiers across three real-world content moderation tasks. Our findings provide actionable insights for industrial-scale moderation systems, demonstrating that RL exhibits sigmoid-like scaling behavior in which performance improves smoothly with increased training data, rollouts, and optimization steps before gradually saturating. Moreover, we show that RL substantially improves performance on tasks requiring complex policy-grounded reasoning while achieving up to 100x higher data efficiency than supervised fine-tuning, making it particularly effective in domains where expert annotations are scarce or costly.
Large Scale Retrieval for the LinkedIn Feed using Causal Language Models
Oct 16, 2025


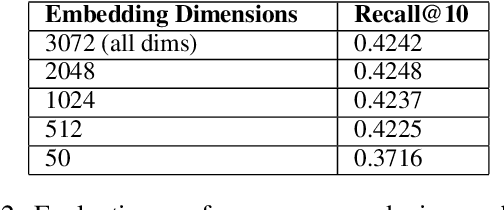
In large scale recommendation systems like the LinkedIn Feed, the retrieval stage is critical for narrowing hundreds of millions of potential candidates to a manageable subset for ranking. LinkedIn's Feed serves suggested content from outside of the member's network (based on the member's topical interests), where 2000 candidates are retrieved from a pool of hundreds of millions candidate with a latency budget of a few milliseconds and inbound QPS of several thousand per second. This paper presents a novel retrieval approach that fine-tunes a large causal language model (Meta's LLaMA 3) as a dual encoder to generate high quality embeddings for both users (members) and content (items), using only textual input. We describe the end to end pipeline, including prompt design for embedding generation, techniques for fine-tuning at LinkedIn's scale, and infrastructure for low latency, cost effective online serving. We share our findings on how quantizing numerical features in the prompt enables the information to get properly encoded in the embedding, facilitating greater alignment between the retrieval and ranking layer. The system was evaluated using offline metrics and an online A/B test, which showed substantial improvements in member engagement. We observed significant gains among newer members, who often lack strong network connections, indicating that high-quality suggested content aids retention. This work demonstrates how generative language models can be effectively adapted for real time, high throughput retrieval in industrial applications.
CoT-ICL Lab: A Petri Dish for Studying Chain-of-Thought Learning from In-Context Demonstrations
Feb 21, 2025


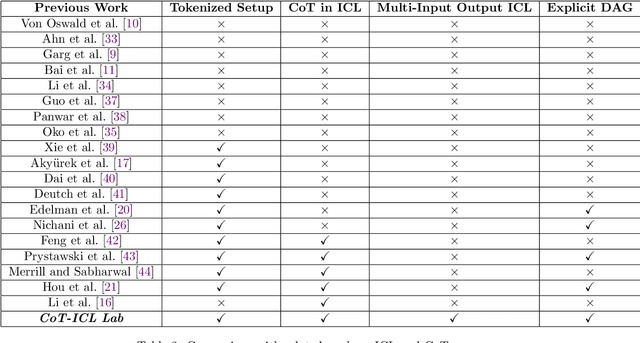
We introduce CoT-ICL Lab, a framework and methodology to generate synthetic tokenized datasets and systematically study chain-of-thought (CoT) in-context learning (ICL) in language models. CoT-ICL Lab allows fine grained control over the complexity of in-context examples by decoupling (1) the causal structure involved in chain token generation from (2) the underlying token processing functions. We train decoder-only transformers (up to 700M parameters) on these datasets and show that CoT accelerates the accuracy transition to higher values across model sizes. In particular, we find that model depth is crucial for leveraging CoT with limited in-context examples, while more examples help shallow models match deeper model performance. Additionally, limiting the diversity of token processing functions throughout training improves causal structure learning via ICL. We also interpret these transitions by analyzing transformer embeddings and attention maps. Overall, CoT-ICL Lab serves as a simple yet powerful testbed for theoretical and empirical insights into ICL and CoT in language models.
Efficient AI in Practice: Training and Deployment of Efficient LLMs for Industry Applications
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of industrial applications, from search and recommendations to generative tasks. Although scaling laws indicate that larger models generally yield better generalization and performance, their substantial computational requirements often render them impractical for many real-world scenarios at scale. In this paper, we present methods and insights for training small language models (SLMs) that deliver high performance and efficiency in deployment. We focus on two key techniques: (1) knowledge distillation and (2) model compression via quantization and pruning. These approaches enable SLMs to retain much of the quality of their larger counterparts while significantly reducing training, serving costs, and latency. We detail the impact of these techniques on a variety of use cases at a large professional social network platform and share deployment lessons - including hardware optimization strategies that enhance speed and throughput for both predictive and reasoning-based applications.
360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation
Jan 27, 2025



Ranking and recommendation systems are the foundation for numerous online experiences, ranging from search results to personalized content delivery. These systems have evolved into complex, multilayered architectures that leverage vast datasets and often incorporate thousands of predictive models. The maintenance and enhancement of these models is a labor intensive process that requires extensive feature engineering. This approach not only exacerbates technical debt but also hampers innovation in extending these systems to emerging problem domains. In this report, we present our research to address these challenges by utilizing a large foundation model with a textual interface for ranking and recommendation tasks. We illustrate several key advantages of our approach: (1) a single model can manage multiple predictive tasks involved in ranking and recommendation, (2) decoder models with textual interface due to their comprehension of reasoning capabilities, can generalize to new recommendation surfaces and out-of-domain problems, and (3) by employing natural language interfaces for task definitions and verbalizing member behaviors and their social connections, we eliminate the need for feature engineering and the maintenance of complex directed acyclic graphs of model dependencies. We introduce our research pre-production model, 360Brew V1.0, a 150B parameter, decoder-only model that has been trained and fine-tuned on LinkedIn's data and tasks. This model is capable of solving over 30 predictive tasks across various segments of the LinkedIn platform, achieving performance levels comparable to or exceeding those of current production systems based on offline metrics, without task-specific fine-tuning. Notably, each of these tasks is conventionally addressed by dedicated models that have been developed and maintained over multiple years by teams of a similar or larger size than our own.
Lost-in-Distance: Impact of Contextual Proximity on LLM Performance in Graph Tasks
Oct 02, 2024



Despite significant advancements, Large Language Models (LLMs) exhibit blind spots that impair their ability to retrieve and process relevant contextual data effectively. We demonstrate that LLM performance in graph tasks with complexities beyond the "needle-in-a-haystack" scenario-where solving the problem requires cross-referencing and reasoning across multiple subproblems jointly-is influenced by the proximity of relevant information within the context, a phenomenon we term "lost-in-distance". We examine two fundamental graph tasks: identifying common connections between two nodes and assessing similarity among three nodes, and show that the model's performance in these tasks significantly depends on the relative positioning of common edges. We evaluate three publicly available LLMs-Llama-3-8B, Llama-3-70B, and GPT-4-using various graph encoding techniques that represent graph structures for LLM input. We propose a formulation for the lost-in-distance phenomenon and demonstrate that lost-in-distance and lost-in-the middle phenomenas occur independently. Results indicate that model accuracy can decline by up to 6x as the distance between node connections increases, independent of graph encoding and model size.
Enhancing Stability for Large Models Training in Constrained Bandwidth Networks
Jun 28, 2024Training extremely large language models with billions of parameters is a computationally intensive task that pushes the limits of current data parallel training systems. While techniques like ZeRO++ have enabled efficient distributed training of such giant models on inexpensive low-bandwidth clusters, they can suffer from convergence issues due to potential race conditions in the hierarchical partitioning (hpZ) scheme employed to reduce cross-machine communication. In this work, we first show how these race conditions cause instability when training models with billions of parameters. We then propose a modification to the partitioning algorithm that addresses these convergence challenges while maintaining competitive training efficiency. Empirical evaluation on training the multi-billion parameters Falcon Models and Llama-2 models demonstrates the updated algorithm's ability to achieve reliable convergence on these massive models, where stock ZeRO++ hpZ fails to converge. The updated algorithm enables robust training of larger models with 98\% throughput and model training speed improvement without sacrificing the quality of convergence.
Resprompt: Residual Connection Prompting Advances Multi-Step Reasoning in Large Language Models
Oct 07, 2023Chain-of-thought (CoT) prompting, which offers step-by-step problem-solving rationales, has impressively unlocked the reasoning potential of large language models (LLMs). Yet, the standard CoT is less effective in problems demanding multiple reasoning steps. This limitation arises from the complex reasoning process in multi-step problems: later stages often depend on the results of several steps earlier, not just the results of the immediately preceding step. Such complexities suggest the reasoning process is naturally represented as a graph. The almost linear and straightforward structure of CoT prompting, however, struggles to capture this complex reasoning graph. To address this challenge, we propose Residual Connection Prompting (RESPROMPT), a new prompting strategy that advances multi-step reasoning in LLMs. Our key idea is to reconstruct the reasoning graph within prompts. We achieve this by integrating necessary connections-links present in the reasoning graph but missing in the linear CoT flow-into the prompts. Termed "residual connections", these links are pivotal in morphing the linear CoT structure into a graph representation, effectively capturing the complex reasoning graphs inherent in multi-step problems. We evaluate RESPROMPT on six benchmarks across three diverse domains: math, sequential, and commonsense reasoning. For the open-sourced LLaMA family of models, RESPROMPT yields a significant average reasoning accuracy improvement of 12.5% on LLaMA-65B and 6.8% on LLaMA2-70B. Breakdown analysis further highlights RESPROMPT particularly excels in complex multi-step reasoning: for questions demanding at least five reasoning steps, RESPROMPT outperforms the best CoT based benchmarks by a remarkable average improvement of 21.1% on LLaMA-65B and 14.3% on LLaMA2-70B. Through extensive ablation studies and analyses, we pinpoint how to most effectively build residual connections.
Identifying Interpretable Subspaces in Image Representations
Jul 20, 2023We propose Automatic Feature Explanation using Contrasting Concepts (FALCON), an interpretability framework to explain features of image representations. For a target feature, FALCON captions its highly activating cropped images using a large captioning dataset (like LAION-400m) and a pre-trained vision-language model like CLIP. Each word among the captions is scored and ranked leading to a small number of shared, human-understandable concepts that closely describe the target feature. FALCON also applies contrastive interpretation using lowly activating (counterfactual) images, to eliminate spurious concepts. Although many existing approaches interpret features independently, we observe in state-of-the-art self-supervised and supervised models, that less than 20% of the representation space can be explained by individual features. We show that features in larger spaces become more interpretable when studied in groups and can be explained with high-order scoring concepts through FALCON. We discuss how extracted concepts can be used to explain and debug failures in downstream tasks. Finally, we present a technique to transfer concepts from one (explainable) representation space to another unseen representation space by learning a simple linear transformation.
Meta-training with Demonstration Retrieval for Efficient Few-shot Learning
Jun 30, 2023



Large language models show impressive results on few-shot NLP tasks. However, these models are memory and computation-intensive. Meta-training allows one to leverage smaller models for few-shot generalization in a domain-general and task-agnostic manner; however, these methods alone results in models that may not have sufficient parameterization or knowledge to adapt quickly to a large variety of tasks. To overcome this issue, we propose meta-training with demonstration retrieval, where we use a dense passage retriever to retrieve semantically similar labeled demonstrations to each example for more varied supervision. By separating external knowledge from model parameters, we can use meta-training to train parameter-efficient models that generalize well on a larger variety of tasks. We construct a meta-training set from UnifiedQA and CrossFit, and propose a demonstration bank based on UnifiedQA tasks. To our knowledge, our work is the first to combine retrieval with meta-training, to use DPR models to retrieve demonstrations, and to leverage demonstrations from many tasks simultaneously, rather than randomly sampling demonstrations from the training set of the target task. Our approach outperforms a variety of targeted parameter-efficient and retrieval-augmented few-shot methods on QA, NLI, and text classification tasks (including SQuAD, QNLI, and TREC). Our approach can be meta-trained and fine-tuned quickly on a single GPU.