 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-REX: Benchmarking Exploratory Visual Reasoning via Chain-of-Questions
Dec 12, 2025While many vision-language models (VLMs) are developed to answer well-defined, straightforward questions with highly specified targets, as in most benchmarks, they often struggle in practice with complex open-ended tasks, which usually require multiple rounds of exploration and reasoning in the visual space. Such visual thinking paths not only provide step-by-step exploration and verification as an AI detective but also produce better interpretations of the final answers. However, these paths are challenging to evaluate due to the large exploration space of intermediate steps. To bridge the gap, we develop an evaluation suite, ``Visual Reasoning with multi-step EXploration (V-REX)'', which is composed of a benchmark of challenging visual reasoning tasks requiring native multi-step exploration and an evaluation protocol. V-REX covers rich application scenarios across diverse domains. V-REX casts the multi-step exploratory reasoning into a Chain-of-Questions (CoQ) and disentangles VLMs' capability to (1) Planning: breaking down an open-ended task by selecting a chain of exploratory questions; and (2) Following: answering curated CoQ sequentially to collect information for deriving the final answer. By curating finite options of questions and answers per step, V-REX achieves a reliable quantitative and fine-grained analysis of the intermediate steps. By assessing SOTA proprietary and open-sourced VLMs, we reveal consistent scaling trends, significant differences between planning and following abilities, and substantial room for improvement in multi-step exploratory reasoning.
ColorBench: Can VLMs See and Understand the Colorful World? A Comprehensive Benchmark for Color Perception, Reasoning, and Robustness
Apr 10, 2025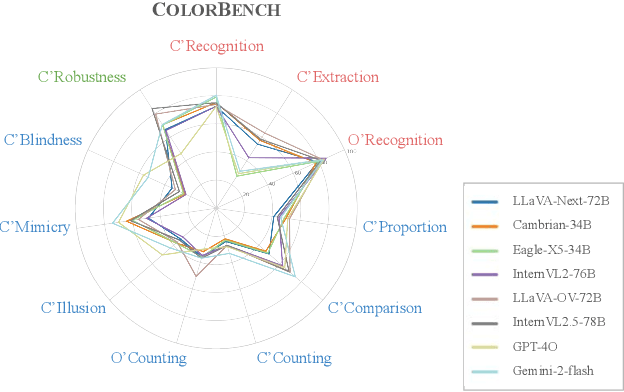
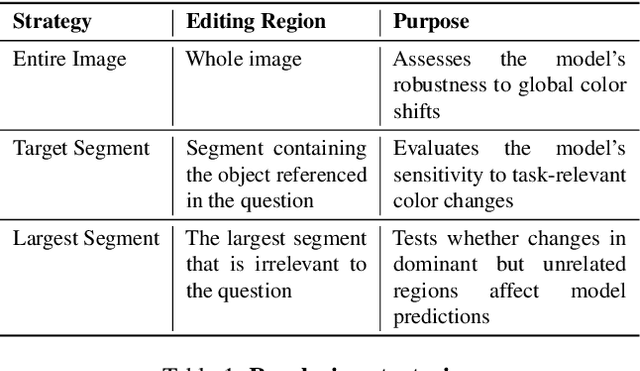
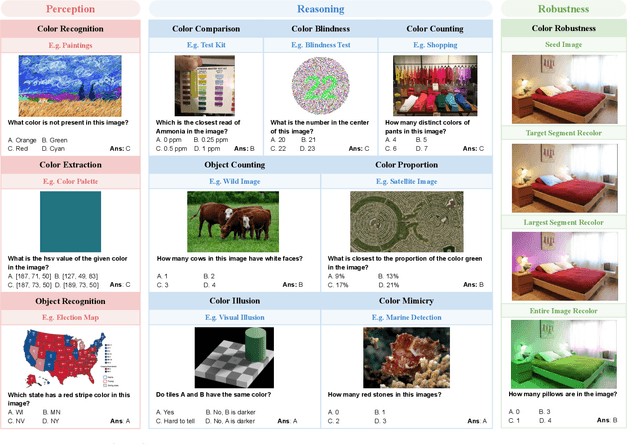
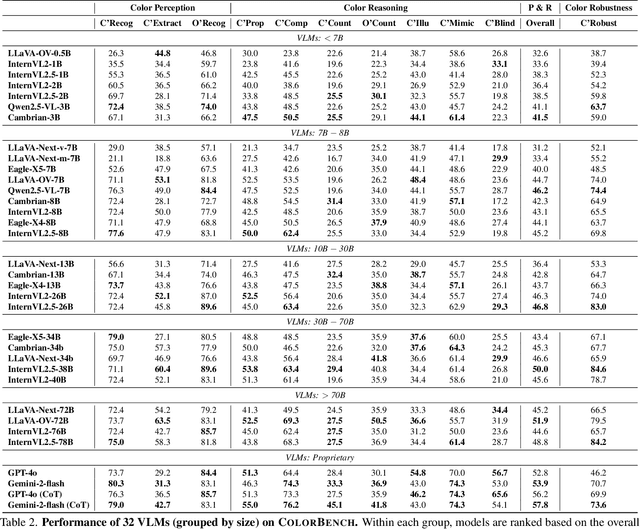
Color plays an important role in human perception and usually provides critical clues in visual reasoning. However, it is unclear whether and how vision-language models (VLMs) can perceive, understand, and leverage color as humans. This paper introduces ColorBench, an innovative benchmark meticulously crafted to assess the capabilities of VLMs in color understanding, including color perception, reasoning, and robustness. By curating a suite of diverse test scenarios, with grounding in real applications, ColorBench evaluates how these models perceive colors, infer meanings from color-based cues, and maintain consistent performance under varying color transformations. Through an extensive evaluation of 32 VLMs with varying language models and vision encoders, our paper reveals some undiscovered findings: (i) The scaling law (larger models are better) still holds on ColorBench, while the language model plays a more important role than the vision encoder. (ii) However, the performance gaps across models are relatively small, indicating that color understanding has been largely neglected by existing VLMs. (iii) CoT reasoning improves color understanding accuracies and robustness, though they are vision-centric tasks. (iv) Color clues are indeed leveraged by VLMs on ColorBench but they can also mislead models in some tasks. These findings highlight the critical limitations of current VLMs and underscore the need to enhance color comprehension. Our ColorBenchcan serve as a foundational tool for advancing the study of human-level color understanding of multimodal AI.
Diffusion Curriculum: Synthetic-to-Real Generative Curriculum Learning via Image-Guided Diffusion
Oct 17, 2024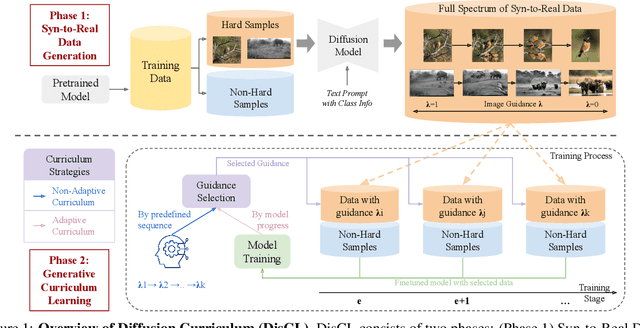
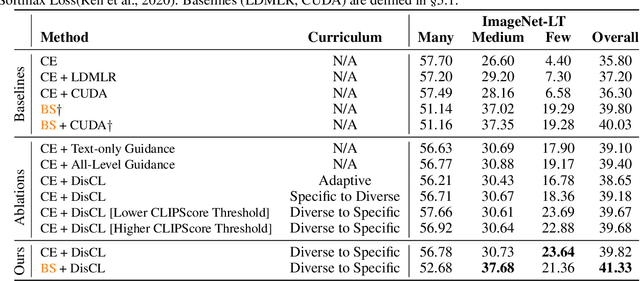

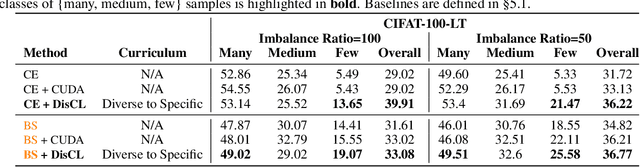
Low-quality or scarce data has posed significant challenges for training deep neural networks in practice. While classical data augmentation cannot contribute very different new data, diffusion models opens up a new door to build self-evolving AI by generating high-quality and diverse synthetic data through text-guided prompts. However, text-only guidance cannot control synthetic images' proximity to the original images, resulting in out-of-distribution data detrimental to the model performance. To overcome the limitation, we study image guidance to achieve a spectrum of interpolations between synthetic and real images. With stronger image guidance, the generated images are similar to the training data but hard to learn. While with weaker image guidance, the synthetic images will be easier for model but contribute to a larger distribution gap with the original data. The generated full spectrum of data enables us to build a novel "Diffusion Curriculum (DisCL)". DisCL adjusts the image guidance level of image synthesis for each training stage: It identifies and focuses on hard samples for the model and assesses the most effective guidance level of synthetic images to improve hard data learning. We apply DisCL to two challenging tasks: long-tail (LT) classification and learning from low-quality data. It focuses on lower-guidance images of high-quality to learn prototypical features as a warm-up of learning higher-guidance images that might be weak on diversity or quality. Extensive experiments showcase a gain of 2.7% and 2.1% in OOD and ID macro-accuracy when applying DisCL to iWildCam dataset. On ImageNet-LT, DisCL improves the base model's tail-class accuracy from 4.4% to 23.64% and leads to a 4.02% improvement in all-class accuracy.
EditVal: Benchmarking Diffusion Based Text-Guided Image Editing Methods
Oct 03, 2023
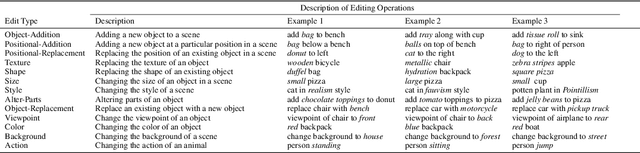
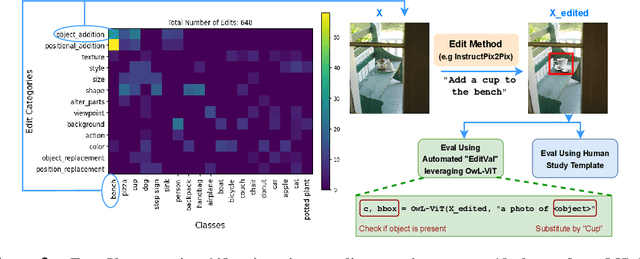
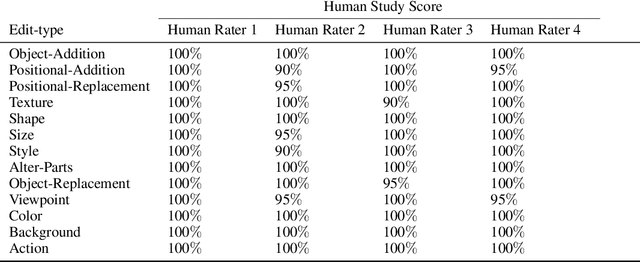
A plethora of text-guided image editing methods have recently been developed by leveraging the impressive capabilities of large-scale diffusion-based generative models such as Imagen and Stable Diffusion. A standardized evaluation protocol, however, does not exist to compare methods across different types of fine-grained edits. To address this gap, we introduce EditVal, a standardized benchmark for quantitatively evaluating text-guided image editing methods. EditVal consists of a curated dataset of images, a set of editable attributes for each image drawn from 13 possible edit types, and an automated evaluation pipeline that uses pre-trained vision-language models to assess the fidelity of generated images for each edit type. We use EditVal to benchmark 8 cutting-edge diffusion-based editing methods including SINE, Imagic and Instruct-Pix2Pix. We complement this with a large-scale human study where we show that EditVall's automated evaluation pipeline is strongly correlated with human-preferences for the edit types we considered. From both the human study and automated evaluation, we find that: (i) Instruct-Pix2Pix, Null-Text and SINE are the top-performing methods averaged across different edit types, however {\it only} Instruct-Pix2Pix and Null-Text are able to preserve original image properties; (ii) Most of the editing methods fail at edits involving spatial operations (e.g., changing the position of an object). (iii) There is no `winner' method which ranks the best individually across a range of different edit types. We hope that our benchmark can pave the way to developing more reliable text-guided image editing tools in the future. We will publicly release EditVal, and all associated code and human-study templates to support these research directions in https://deep-ml-research.github.io/editval/.
Identifying Interpretable Subspaces in Image Representations
Jul 20, 2023We propose Automatic Feature Explanation using Contrasting Concepts (FALCON), an interpretability framework to explain features of image representations. For a target feature, FALCON captions its highly activating cropped images using a large captioning dataset (like LAION-400m) and a pre-trained vision-language model like CLIP. Each word among the captions is scored and ranked leading to a small number of shared, human-understandable concepts that closely describe the target feature. FALCON also applies contrastive interpretation using lowly activating (counterfactual) images, to eliminate spurious concepts. Although many existing approaches interpret features independently, we observe in state-of-the-art self-supervised and supervised models, that less than 20% of the representation space can be explained by individual features. We show that features in larger spaces become more interpretable when studied in groups and can be explained with high-order scoring concepts through FALCON. We discuss how extracted concepts can be used to explain and debug failures in downstream tasks. Finally, we present a technique to transfer concepts from one (explainable) representation space to another unseen representation space by learning a simple linear transformation.
Efficient Video Classification Using Fewer Frames
Feb 27, 2019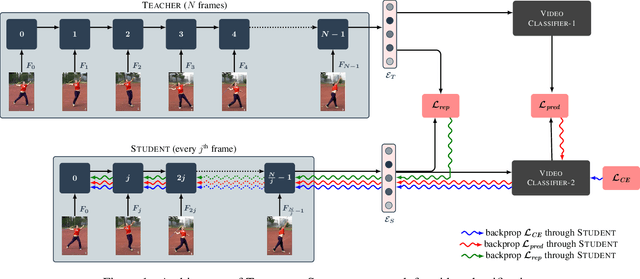
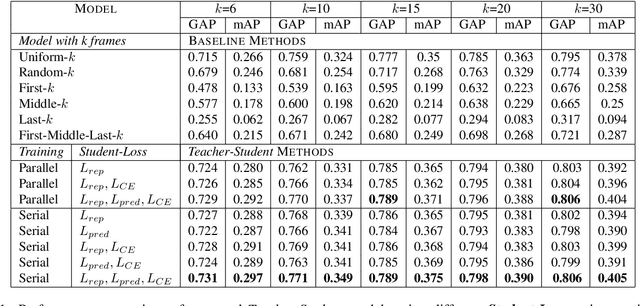
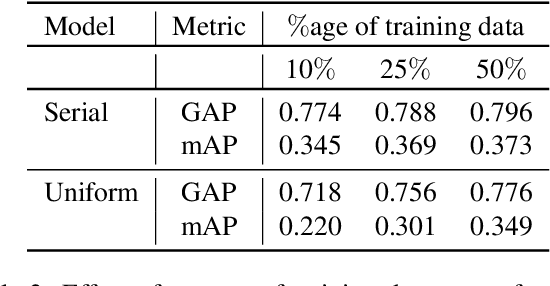
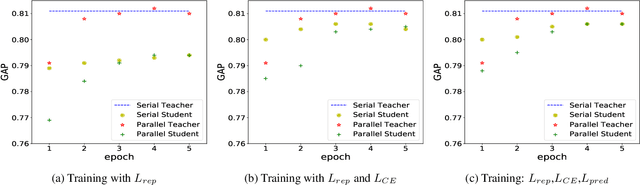
Recently,there has been a lot of interest in building compact models for video classification which have a small memory footprint (<1 GB). While these models are compact, they typically operate by repeated application of a small weight matrix to all the frames in a video. E.g. recurrent neural network based methods compute a hidden state for every frame of the video using a recurrent weight matrix. Similarly, cluster-and-aggregate based methods such as NetVLAD, have a learnable clustering matrix which is used to assign soft-clusters to every frame in the video. Since these models look at every frame in the video, the number of floating point operations (FLOPs) is still large even though the memory footprint is small. We focus on building compute-efficient video classification models which process fewer frames and hence have less number of FLOPs. Similar to memory efficient models, we use the idea of distillation albeit in a different setting. Specifically, in our case, a compute-heavy teacher which looks at all the frames in the video is used to train a compute-efficient student which looks at only a small fraction of frames in the video. This is in contrast to a typical memory efficient Teacher-Student setting, wherein both the teacher and the student look at all the frames in the video but the student has fewer parameters. Our work thus complements the research on memory efficient video classification. We do an extensive evaluation with three types of models for video classification,viz.(i) recurrent models (ii) cluster-and-aggregate models and (iii) memory-efficient cluster-and-aggregate models and show that in each of these cases, a see-it-all teacher can be used to train a compute efficient see-very-little student. We show that the proposed student network can reduce the inference time by 30% and the number of FLOPs by approximately 90% with a negligible drop in the performance.
Studying the Plasticity in Deep Convolutional Neural Networks using Random Pruning
Dec 26, 2018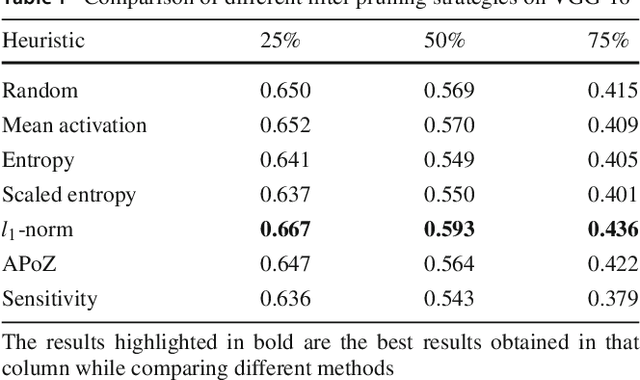
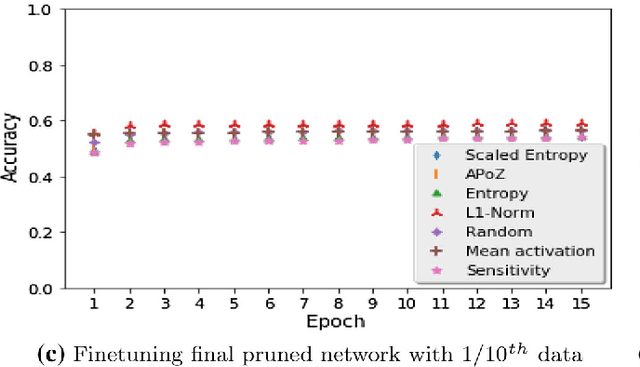
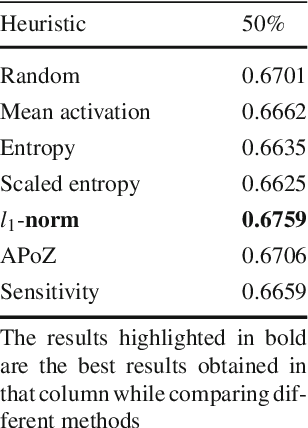
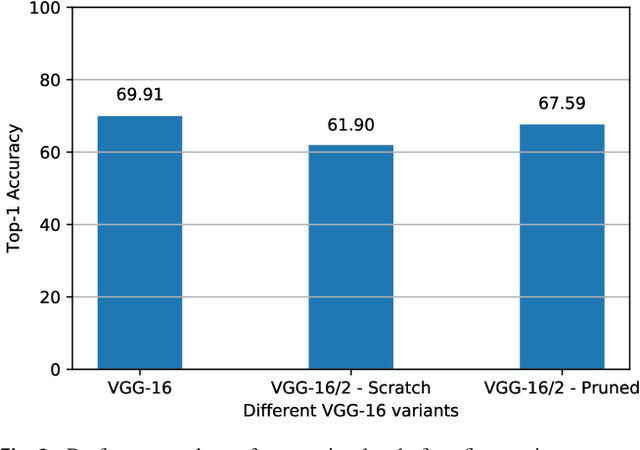
Recently there has been a lot of work on pruning filters from deep convolutional neural networks (CNNs) with the intention of reducing computations.The key idea is to rank the filters based on a certain criterion (say, l1-norm) and retain only the top ranked filters. Once the low scoring filters are pruned away the remainder of the network is fine tuned and is shown to give performance comparable to the original unpruned network. In this work, we report experiments which suggest that the comparable performance of the pruned network is not due to the specific criterion chosen but due to the inherent plasticity of deep neural networks which allows them to recover from the loss of pruned filters once the rest of the filters are fine-tuned. Specifically we show counter-intuitive results wherein by randomly pruning 25-50% filters from deep CNNs we are able to obtain the same performance as obtained by using state-of-the-art pruning methods. We empirically validate our claims by doing an exhaustive evaluation with VGG-16 and ResNet-50. We also evaluate a real world scenario where a CNN trained on all 1000 ImageNet classes needs to be tested on only a small set of classes at test time (say, only animals). We create a new benchmark dataset from ImageNet to evaluate such class specific pruning and show that even here a random pruning strategy gives close to state-of-the-art performance. Unlike existing approaches which mainly focus on the task of image classification, in this work we also report results on object detection and image segmentation. We show that using a simple random pruning strategy we can achieve significant speed up in object detection (74% improvement in fps) while retaining the same accuracy as that of the original Faster RCNN model. Similarly we show that the performance of a pruned Segmentation Network (SegNet) is actually very similar to that of the original unpruned SegNet.
I Have Seen Enough: A Teacher Student Network for Video Classification Using Fewer Frames
May 12, 2018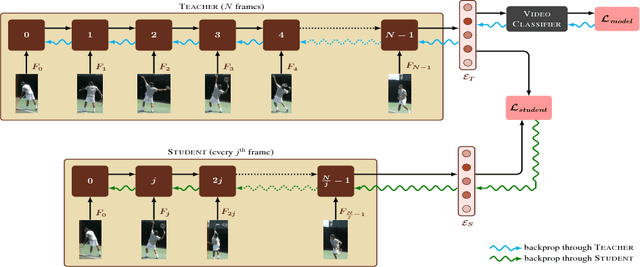
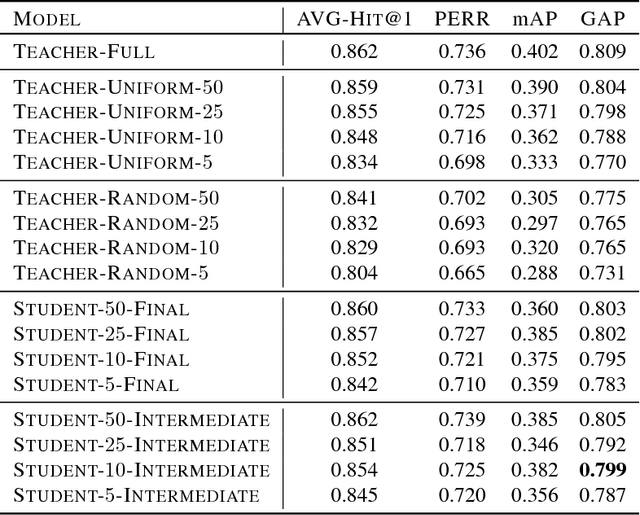

Over the past few years, various tasks involving videos such as classification, description, summarization and question answering have received a lot of attention. Current models for these tasks compute an encoding of the video by treating it as a sequence of images and going over every image in the sequence. However, for longer videos this is very time consuming. In this paper, we focus on the task of video classification and aim to reduce the computational time by using the idea of distillation. Specifically, we first train a teacher network which looks at all the frames in a video and computes a representation for the video. We then train a student network whose objective is to process only a small fraction of the frames in the video and still produce a representation which is very close to the representation computed by the teacher network. This smaller student network involving fewer computations can then be employed at inference time for video classification. We experiment with the YouTube-8M dataset and show that the proposed student network can reduce the inference time by upto 30% with a very small drop in the performance
Recovering from Random Pruning: On the Plasticity of Deep Convolutional Neural Networks
Jan 31, 2018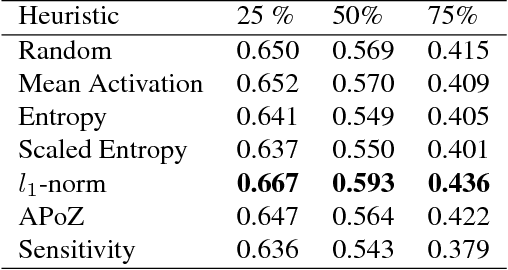
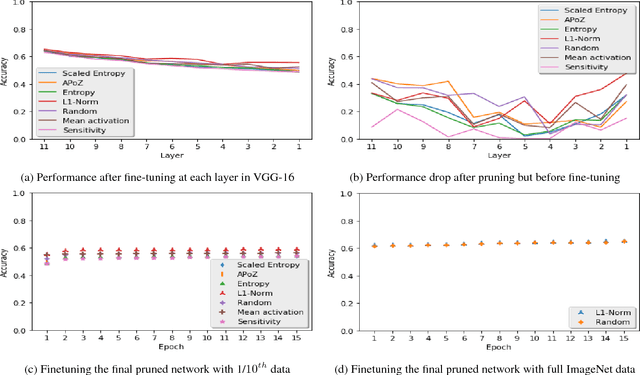
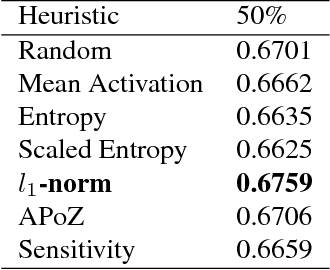
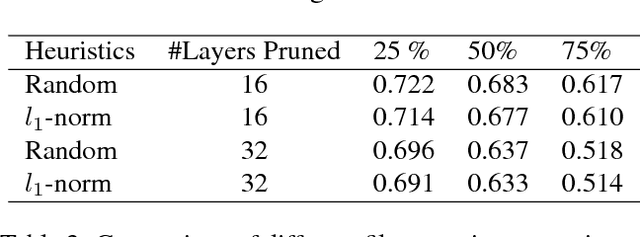
Recently there has been a lot of work on pruning filters from deep convolutional neural networks (CNNs) with the intention of reducing computations. The key idea is to rank the filters based on a certain criterion (say, $l_1$-norm, average percentage of zeros, etc) and retain only the top ranked filters. Once the low scoring filters are pruned away the remainder of the network is fine tuned and is shown to give performance comparable to the original unpruned network. In this work, we report experiments which suggest that the comparable performance of the pruned network is not due to the specific criterion chosen but due to the inherent plasticity of deep neural networks which allows them to recover from the loss of pruned filters once the rest of the filters are fine-tuned. Specifically, we show counter-intuitive results wherein by randomly pruning 25-50\% filters from deep CNNs we are able to obtain the same performance as obtained by using state of the art pruning methods. We empirically validate our claims by doing an exhaustive evaluation with VGG-16 and ResNet-50. Further, we also evaluate a real world scenario where a CNN trained on all 1000 ImageNet classes needs to be tested on only a small set of classes at test time (say, only animals). We create a new benchmark dataset from ImageNet to evaluate such class specific pruning and show that even here a random pruning strategy gives close to state of the art performance. Lastly, unlike existing approaches which mainly focus on the task of image classification, in this work we also report results on object detection. We show that using a simple random pruning strategy we can achieve significant speed up in object detection (74$\%$ improvement in fps) while retaining the same accuracy as that of the original Faster RCNN model.