 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying the Plasticity in Deep Convolutional Neural Networks using Random Pruning
Paper and Code
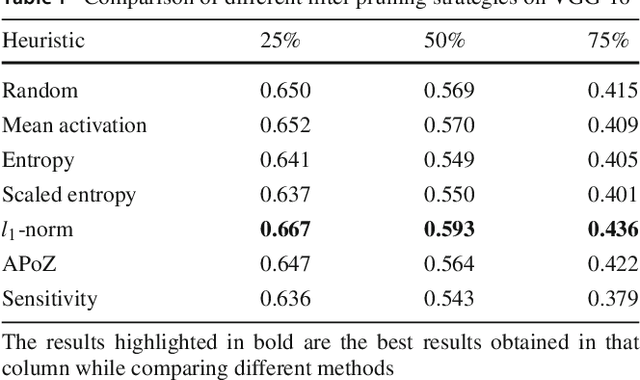
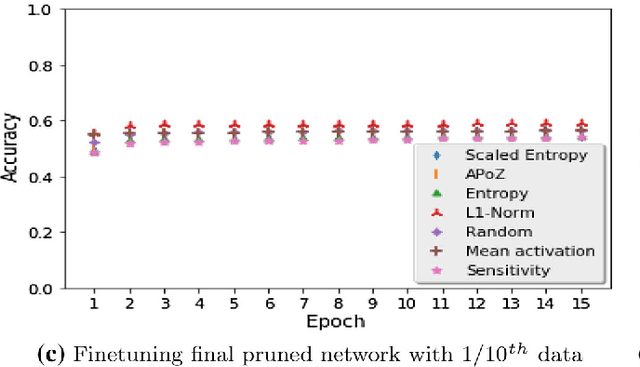
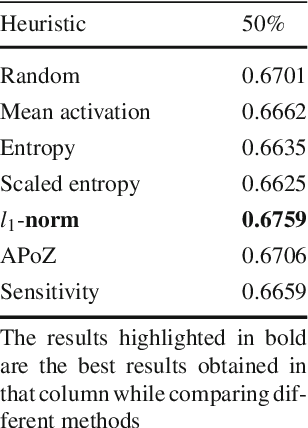
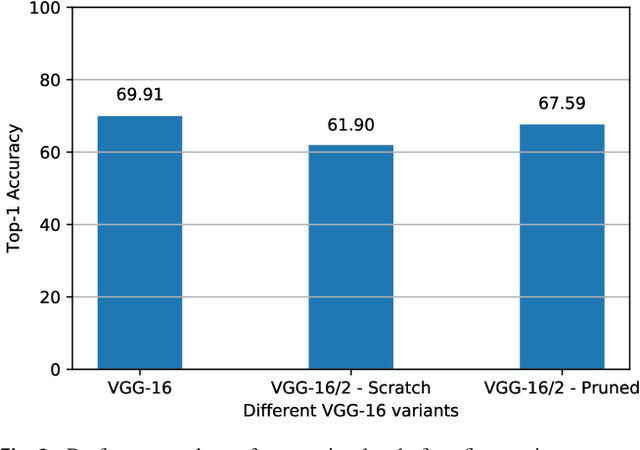
Recently there has been a lot of work on pruning filters from deep convolutional neural networks (CNNs) with the intention of reducing computations.The key idea is to rank the filters based on a certain criterion (say, l1-norm) and retain only the top ranked filters. Once the low scoring filters are pruned away the remainder of the network is fine tuned and is shown to give performance comparable to the original unpruned network. In this work, we report experiments which suggest that the comparable performance of the pruned network is not due to the specific criterion chosen but due to the inherent plasticity of deep neural networks which allows them to recover from the loss of pruned filters once the rest of the filters are fine-tuned. Specifically we show counter-intuitive results wherein by randomly pruning 25-50% filters from deep CNNs we are able to obtain the same performance as obtained by using state-of-the-art pruning methods. We empirically validate our claims by doing an exhaustive evaluation with VGG-16 and ResNet-50. We also evaluate a real world scenario where a CNN trained on all 1000 ImageNet classes needs to be tested on only a small set of classes at test time (say, only animals). We create a new benchmark dataset from ImageNet to evaluate such class specific pruning and show that even here a random pruning strategy gives close to state-of-the-art performance. Unlike existing approaches which mainly focus on the task of image classification, in this work we also report results on object detection and image segmentation. We show that using a simple random pruning strategy we can achieve significant speed up in object detection (74% improvement in fps) while retaining the same accuracy as that of the original Faster RCNN model. Similarly we show that the performance of a pruned Segmentation Network (SegNet) is actually very similar to that of the original unpruned SegNet.