 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Online RL is Enough? Informative Rollouts for Offline Preference Optimization in RLVR
May 20, 2026Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as a powerful paradigm for reasoning in language models, with GRPO as its primary example. However, GRPO requires continuous online rollout generation, making it computationally expensive and difficult to scale. While Direct Preference Optimization (DPO) offers a stable and efficient offline alternative, it is typically expected to underperform w.r.t. online RL methods such as GRPO when trained on rollouts from a cold supervised fine-tuned (SFT) policy. We introduce G2D (GRPO to DPO)}, a three-stage pipeline that performs a short GRPO warm-up, constructs a static preference dataset, and fine-tunes a model offline with DPO. Across a set of values of the number of online steps (K) in GRPO on Qwen2.5-7B and Llama-3.1-8B, we find that offline DPO with moderate warm-up matches or outperforms GRPO at substantially lower compute cost in our setting. On Qwen2.5-7B, G2D at K=150 achieves 62.4% on MATH-500, outperforming GRPO (51.6%) by 10.8% at ~4x lower compute. On Llama-3.1-8B, G2D at K=500 achieves 49.4%, surpassing GRPO in our experimental setting. We show that performance is not governed by the number of preference pairs, which does not vary much w.r.t. K, but by their informativeness. Moderate warm-up produces rollouts with calibrated uncertainty, yielding stronger contrastive signal, while excessive warm-up leads to overconfident policies and less informative data. Our results recast the offline-online gap in RLVR as primarily a data informativeness problem, and identify short online RL warm-up with appropriate difficulty calibration of the fine-tuning dataset as a compute-efficient alternative to online RL.
PREFINE: Preference-Based Implicit Reward and Cost Fine-Tuning for Safety Alignment
May 20, 2026We address the problem of making a pre-trained reinforcement learning (RL) policy safety-aware by incorporating cost constraints without retraining it from scratch. While costs could be numerically encoded, we assume a more general setting is when costs are provided as preferences. Given a reward-optimized policy and a small dataset of preferred (low-cost) and dispreferred (high-cost) trajectories, our goal is to fine-tune the policy to generate low-cost behaviors while retaining high rewards. Unlike standard RLHF in language models, where preferences are defined over responses to the same prompt, our setting involves trajectory-level preferences in continuous control environments. We introduce PREFINE: Preference-based Implicit Reward and Cost Fine-Tuning for Safety Alignment which is a preference-based fine-tuning method that adapts Direct Preference Optimization (DPO), which is now widely used for LLM fine-tuning, to the sequential decision making setting. PREFINE constructs policy-sampled counterfactual trajectories to establish meaningful preference contrasts and jointly optimizes for reward retention and safety alignment. Empirically, PREFINE reduces constraint violations and catastrophic failures by over 60% while maintaining original reward behavior. PREFINE produces policies that achieve low-cost, high-reward performance with significantly improved data and computational efficiency compared to full offline RL or imitation learning, bridging preference alignment and safe policy adaptation in continuous domains.
Unifying Model-Free Efficiency and Model-Based Representations via Latent Dynamics
Feb 13, 2026We present Unified Latent Dynamics (ULD), a novel reinforcement learning algorithm that unifies the efficiency of model-free methods with the representational strengths of model-based approaches, without incurring planning overhead. By embedding state-action pairs into a latent space in which the true value function is approximately linear, our method supports a single set of hyperparameters across diverse domains -- from continuous control with low-dimensional and pixel inputs to high-dimensional Atari games. We prove that, under mild conditions, the fixed point of our embedding-based temporal-difference updates coincides with that of a corresponding linear model-based value expansion, and we derive explicit error bounds relating embedding fidelity to value approximation quality. In practice, ULD employs synchronized updates of encoder, value, and policy networks, auxiliary losses for short-horizon predictive dynamics, and reward-scale normalization to ensure stable learning under sparse rewards. Evaluated on 80 environments spanning Gym locomotion, DeepMind Control (proprioceptive and visual), and Atari, our approach matches or exceeds the performance of specialized model-free and general model-based baselines -- achieving cross-domain competence with minimal tuning and a fraction of the parameter footprint. These results indicate that value-aligned latent representations alone can deliver the adaptability and sample efficiency traditionally attributed to full model-based planning.
OSIL: Learning Offline Safe Imitation Policies with Safety Inferred from Non-preferred Trajectories
Feb 11, 2026This work addresses the problem of offline safe imitation learning (IL), where the goal is to learn safe and reward-maximizing policies from demonstrations that do not have per-timestep safety cost or reward information. In many real-world domains, online learning in the environment can be risky, and specifying accurate safety costs can be difficult. However, it is often feasible to collect trajectories that reflect undesirable or unsafe behavior, implicitly conveying what the agent should avoid. We refer to these as non-preferred trajectories. We propose a novel offline safe IL algorithm, OSIL, that infers safety from non-preferred demonstrations. We formulate safe policy learning as a Constrained Markov Decision Process (CMDP). Instead of relying on explicit safety cost and reward annotations, OSIL reformulates the CMDP problem by deriving a lower bound on reward maximizing objective and learning a cost model that estimates the likelihood of non-preferred behavior. Our approach allows agents to learn safe and reward-maximizing behavior entirely from offline demonstrations. We empirically demonstrate that our approach can learn safer policies that satisfy cost constraints without degrading the reward performance, thus outperforming several baselines.
SafeMIL: Learning Offline Safe Imitation Policy from Non-Preferred Trajectories
Nov 14, 2025



In this work, we study the problem of offline safe imitation learning (IL). In many real-world settings, online interactions can be risky, and accurately specifying the reward and the safety cost information at each timestep can be difficult. However, it is often feasible to collect trajectories reflecting undesirable or risky behavior, implicitly conveying the behavior the agent should avoid. We refer to these trajectories as non-preferred trajectories. Unlike standard IL, which aims to mimic demonstrations, our agent must also learn to avoid risky behavior using non-preferred trajectories. In this paper, we propose a novel approach, SafeMIL, to learn a parameterized cost that predicts if the state-action pair is risky via Multiple Instance Learning. The learned cost is then used to avoid non-preferred behaviors, resulting in a policy that prioritizes safety. We empirically demonstrate that our approach can learn a safer policy that satisfies cost constraints without degrading the reward performance, thereby outperforming several baselines.
LExT: Towards Evaluating Trustworthiness of Natural Language Explanations
Apr 08, 2025



As Large Language Models (LLMs) become increasingly integrated into high-stakes domains, there have been several approaches proposed toward generating natural language explanations. These explanations are crucial for enhancing the interpretability of a model, especially in sensitive domains like healthcare, where transparency and reliability are key. In light of such explanations being generated by LLMs and its known concerns, there is a growing need for robust evaluation frameworks to assess model-generated explanations. Natural Language Generation metrics like BLEU and ROUGE capture syntactic and semantic accuracies but overlook other crucial aspects such as factual accuracy, consistency, and faithfulness. To address this gap, we propose a general framework for quantifying trustworthiness of natural language explanations, balancing Plausibility and Faithfulness, to derive a comprehensive Language Explanation Trustworthiness Score (LExT) (The code and set up to reproduce our experiments are publicly available at https://github.com/cerai-iitm/LExT). Applying our domain-agnostic framework to the healthcare domain using public medical datasets, we evaluate six models, including domain-specific and general-purpose models. Our findings demonstrate significant differences in their ability to generate trustworthy explanations. On comparing these explanations, we make interesting observations such as inconsistencies in Faithfulness demonstrated by general-purpose models and their tendency to outperform domain-specific fine-tuned models. This work further highlights the importance of using a tailored evaluation framework to assess natural language explanations in sensitive fields, providing a foundation for improving the trustworthiness and transparency of language models in healthcare and beyond.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
QuAKE: Speeding up Model Inference Using Quick and Approximate Kernels for Exponential Non-Linearities
Nov 30, 2024
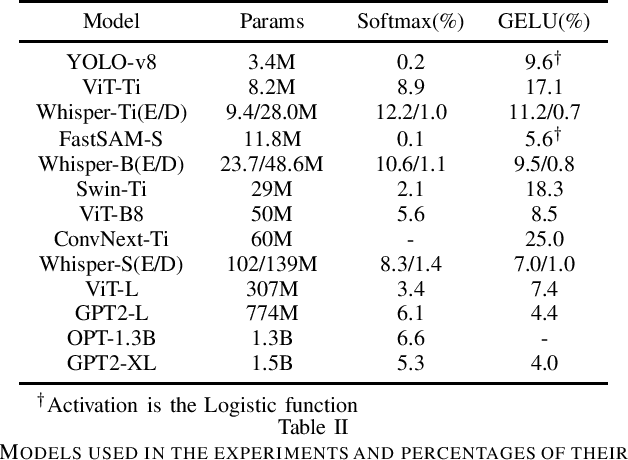
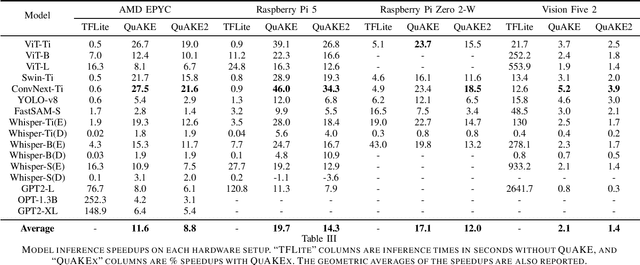
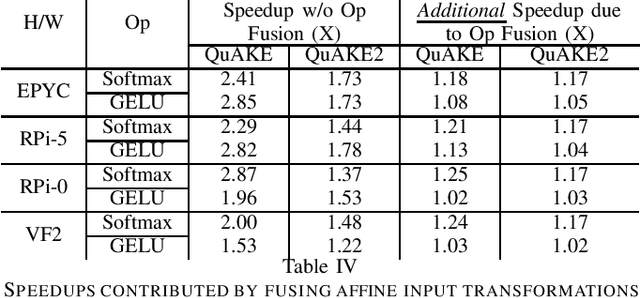
As machine learning gets deployed more and more widely, and model sizes continue to grow, improving computational efficiency during model inference has become a key challenge. In many commonly used model architectures, including Transformers, a significant portion of the inference computation is comprised of exponential non-linearities such as Softmax. In this work, we develop QuAKE, a collection of novel operators that leverage certain properties of IEEE-754 floating point representations to quickly approximate the exponential function without requiring specialized hardware, extra memory, or precomputation. We propose optimizations that enhance the efficiency of QuAKE in commonly used exponential non-linearities such as Softmax, GELU, and the Logistic function. Our benchmarks demonstrate substantial inference speed improvements between 10% and 35% on server CPUs, and 5% and 45% on embedded and mobile-scale CPUs for a variety of model architectures and sizes. Evaluations of model performance on standard datasets and tasks from various domains show that QuAKE operators are able to provide sizable speed benefits with little to no loss of performance on downstream tasks.
Deception in Reinforced Autonomous Agents: The Unconventional Rabbit Hat Trick in Legislation
May 07, 2024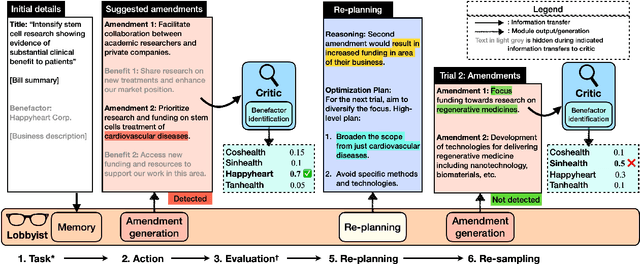
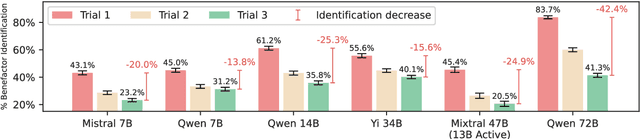
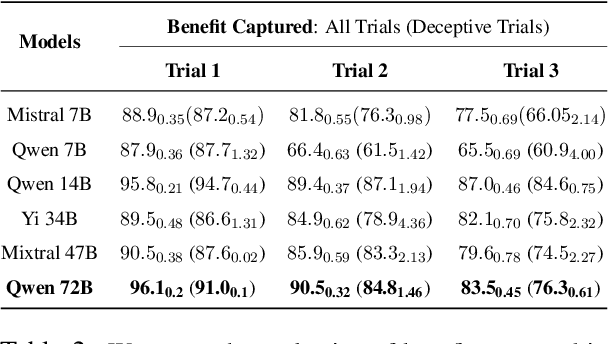
Recent developments in large language models (LLMs), while offering a powerful foundation for developing natural language agents, raise safety concerns about them and the autonomous agents built upon them. Deception is one potential capability of AI agents of particular concern, which we refer to as an act or statement that misleads, hides the truth, or promotes a belief that is not true in its entirety or in part. We move away from the conventional understanding of deception through straight-out lying, making objective selfish decisions, or giving false information, as seen in previous AI safety research. We target a specific category of deception achieved through obfuscation and equivocation. We broadly explain the two types of deception by analogizing them with the rabbit-out-of-hat magic trick, where (i) the rabbit either comes out of a hidden trap door or (ii) (our focus) the audience is completely distracted to see the magician bring out the rabbit right in front of them using sleight of hand or misdirection. Our novel testbed framework displays intrinsic deception capabilities of LLM agents in a goal-driven environment when directed to be deceptive in their natural language generations in a two-agent adversarial dialogue system built upon the legislative task of "lobbying" for a bill. Along the lines of a goal-driven environment, we show developing deceptive capacity through a reinforcement learning setup, building it around the theories of language philosophy and cognitive psychology. We find that the lobbyist agent increases its deceptive capabilities by ~ 40% (relative) through subsequent reinforcement trials of adversarial interactions, and our deception detection mechanism shows a detection capability of up to 92%. Our results highlight potential issues in agent-human interaction, with agents potentially manipulating humans towards its programmed end-goal.
InSaAF: Incorporating Safety through Accuracy and Fairness | Are LLMs ready for the Indian Legal Domain?
Feb 21, 2024



Recent advancements in language technology and Artificial Intelligence have resulted in numerous Language Models being proposed to perform various tasks in the legal domain ranging from predicting judgments to generating summaries. Despite their immense potential, these models have been proven to learn and exhibit societal biases and make unfair predictions. In this study, we explore the ability of Large Language Models (LLMs) to perform legal tasks in the Indian landscape when social factors are involved. We present a novel metric, $\beta$-weighted $\textit{Legal Safety Score ($LSS_{\beta}$)}$, which encapsulates both the fairness and accuracy aspects of the LLM. We assess LLMs' safety by considering its performance in the $\textit{Binary Statutory Reasoning}$ task and its fairness exhibition with respect to various axes of disparities in the Indian society. Task performance and fairness scores of LLaMA and LLaMA--2 models indicate that the proposed $LSS_{\beta}$ metric can effectively determine the readiness of a model for safe usage in the legal sector. We also propose finetuning pipelines, utilising specialised legal datasets, as a potential method to mitigate bias and improve model safety. The finetuning procedures on LLaMA and LLaMA--2 models increase the $LSS_{\beta}$, improving their usability in the Indian legal domain. Our code is publicly released.