 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCobalt: Optimizing Mining Rewards in Proof-of-Work Network Games
Jul 10, 2023



Mining in proof-of-work blockchains has become an expensive affair requiring specialized hardware capable of executing several megahashes per second at huge electricity costs. Miners earn a reward each time they mine a block within the longest chain, which helps offset their mining costs. It is therefore of interest to miners to maximize the number of mined blocks in the blockchain and increase revenue. A key factor affecting mining rewards earned is the connectivity between miners in the peer-to-peer network. To maximize rewards a miner must choose its network connections carefully, ensuring existence of paths to other miners that are on average of a lower latency compared to paths between other miners. We formulate the problem of deciding whom to connect to for miners as a combinatorial bandit problem. Each node picks its neighbors strategically to minimize the latency to reach 90\% of the hash power of the network relative to the 90-th percentile latency from other nodes. A key contribution of our work is the use of a network coordinates based model for learning the network structure within the bandit algorithm. Experimentally we show our proposed algorithm outperforming or matching baselines on diverse network settings.
PolicyClusterGCN: Identifying Efficient Clusters for Training Graph Convolutional Networks
Jun 25, 2023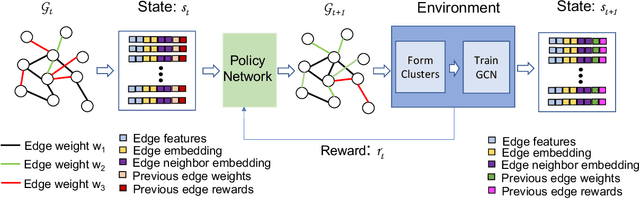

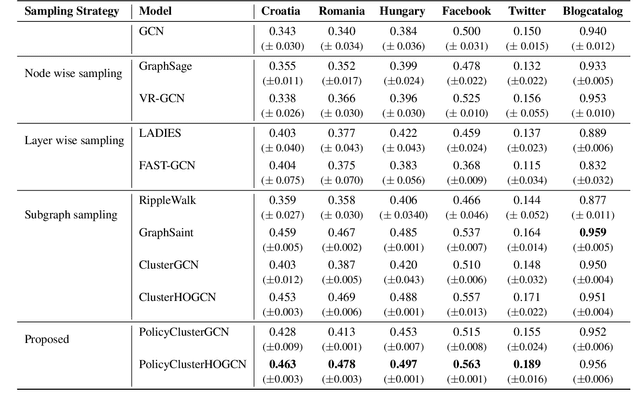
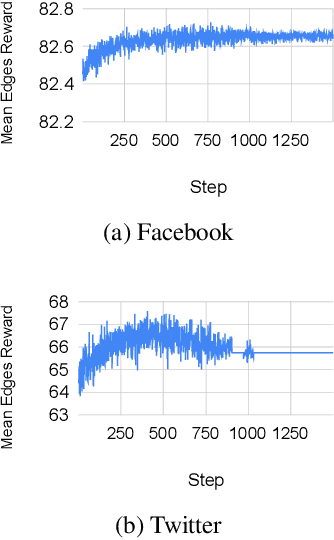
Graph convolutional networks (GCNs) have achieved huge success in several machine learning (ML) tasks on graph-structured data. Recently, several sampling techniques have been proposed for the efficient training of GCNs and to improve the performance of GCNs on ML tasks. Specifically, the subgraph-based sampling approaches such as ClusterGCN and GraphSAINT have achieved state-of-the-art performance on the node classification tasks. These subgraph-based sampling approaches rely on heuristics -- such as graph partitioning via edge cuts -- to identify clusters that are then treated as minibatches during GCN training. In this work, we hypothesize that rather than relying on such heuristics, one can learn a reinforcement learning (RL) policy to compute efficient clusters that lead to effective GCN performance. To that end, we propose PolicyClusterGCN, an online RL framework that can identify good clusters for GCN training. We develop a novel Markov Decision Process (MDP) formulation that allows the policy network to predict ``importance" weights on the edges which are then utilized by a clustering algorithm (Graclus) to compute the clusters. We train the policy network using a standard policy gradient algorithm where the rewards are computed from the classification accuracies while training GCN using clusters given by the policy. Experiments on six real-world datasets and several synthetic datasets show that PolicyClusterGCN outperforms existing state-of-the-art models on node classification task.
Kadabra: Adapting Kademlia for the Decentralized Web
Oct 23, 2022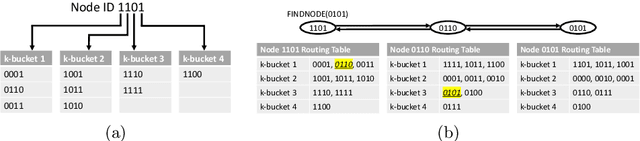
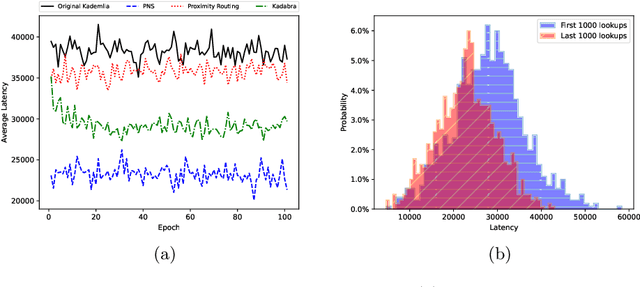
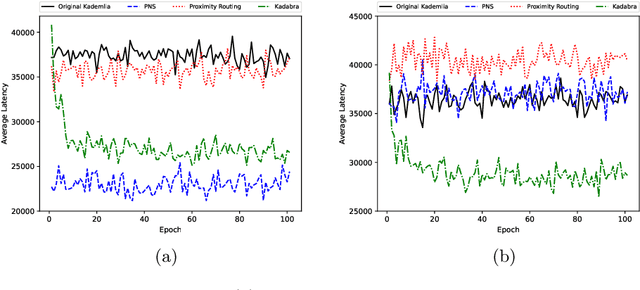
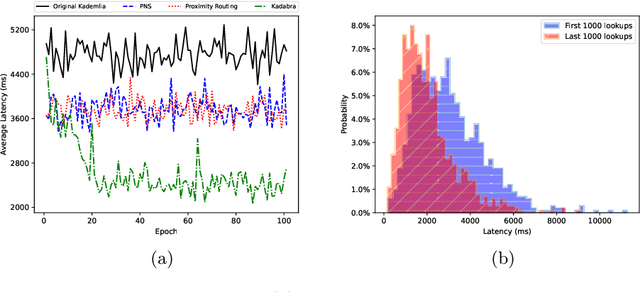
Blockchains have become the catalyst for a growing movement to create a more decentralized Internet. A fundamental operation of applications in a decentralized Internet is data storage and retrieval. As today's blockchains are limited in their storage functionalities, in recent years a number of peer-to-peer data storage networks have emerged based on the Kademlia distributed hash table protocol. However, existing Kademlia implementations are not efficient enough to support fast data storage and retrieval operations necessary for (decentralized) Web applications. In this paper, we present Kadabra, a decentralized protocol for computing the routing table entries in Kademlia to accelerate lookups. Kadabra is motivated by the multi-armed bandit problem, and can automatically adapt to heterogeneity and dynamism in the network. Experimental results show Kadabra achieving between 15-50% lower lookup latencies compared to state-of-the-art baselines.
Placeto: Learning Generalizable Device Placement Algorithms for Distributed Machine Learning
Jun 20, 2019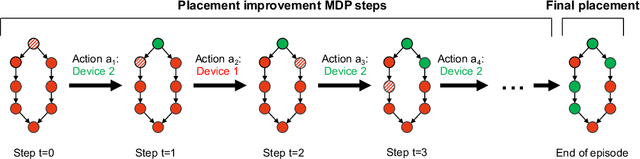
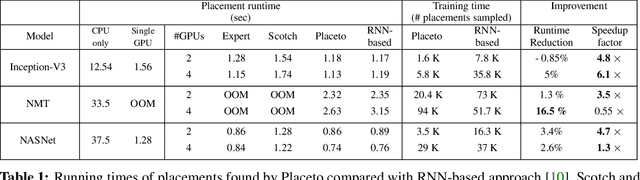
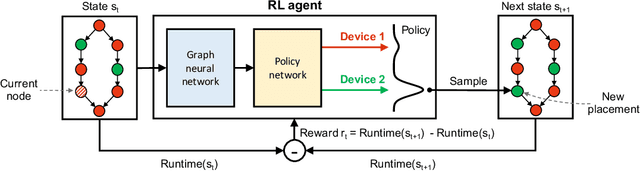
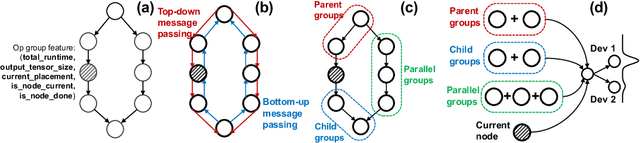
We present Placeto, a reinforcement learning (RL) approach to efficiently find device placements for distributed neural network training. Unlike prior approaches that only find a device placement for a specific computation graph, Placeto can learn generalizable device placement policies that can be applied to any graph. We propose two key ideas in our approach: (1) we represent the policy as performing iterative placement improvements, rather than outputting a placement in one shot; (2) we use graph embeddings to capture relevant information about the structure of the computation graph, without relying on node labels for indexing. These ideas allow Placeto to train efficiently and generalize to unseen graphs. Our experiments show that Placeto requires up to 6.1x fewer training steps to find placements that are on par with or better than the best placements found by prior approaches. Moreover, Placeto is able to learn a generalizable placement policy for any given family of graphs, which can then be used without any retraining to predict optimized placements for unseen graphs from the same family. This eliminates the large overhead incurred by prior RL approaches whose lack of generalizability necessitates re-training from scratch every time a new graph is to be placed.
Learning Scheduling Algorithms for Data Processing Clusters
Oct 12, 2018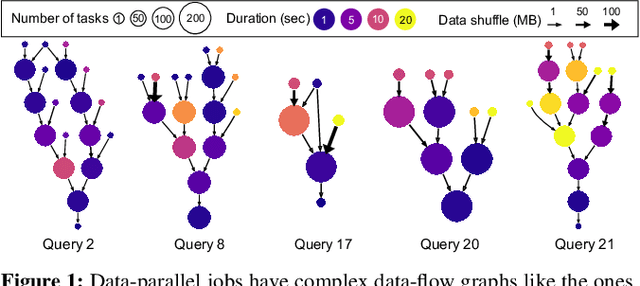

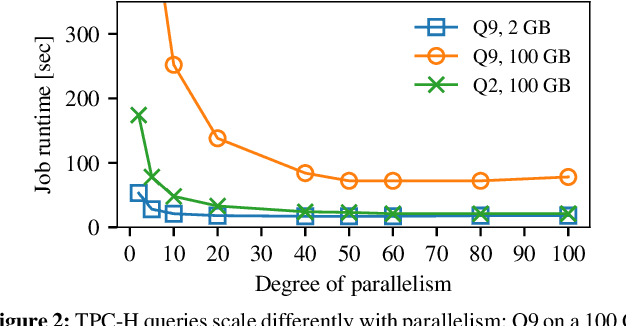

Efficiently scheduling data processing jobs on distributed compute clusters requires complex algorithms. Current systems, however, use simple generalized heuristics and ignore workload structure, since developing and tuning a bespoke heuristic for each workload is infeasible. In this paper, we show that modern machine learning techniques can generate highly-efficient policies automatically. Decima uses reinforcement learning (RL) and neural networks to learn workload-specific scheduling algorithms without any human instruction beyond specifying a high-level objective such as minimizing average job completion time. Off-the-shelf RL techniques, however, cannot handle the complexity and scale of the scheduling problem. To build Decima, we had to develop new representations for jobs' dependency graphs, design scalable RL models, and invent new RL training methods for continuous job arrivals. Our prototype integration with Spark on a 25-node cluster shows that Decima outperforms several heuristics, including hand-tuned ones, by at least 21%. Further experiments with an industrial production workload trace demonstrate that Decima delivers up to a 17% reduction in average job completion time and scales to large clusters.
Graph2Seq: Scalable Learning Dynamics for Graphs
Oct 09, 2018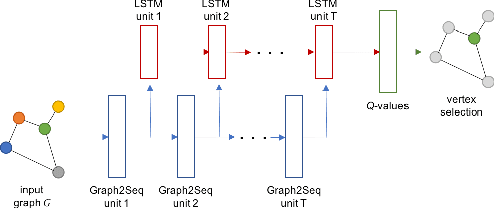
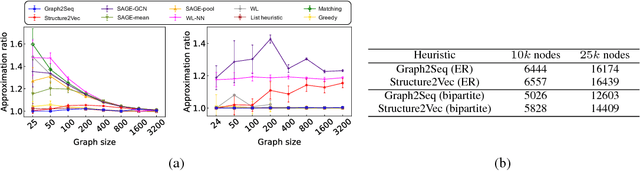
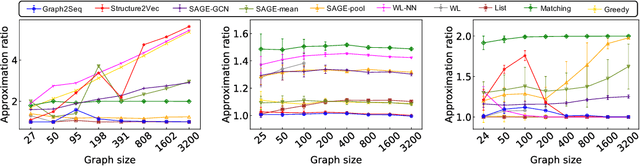
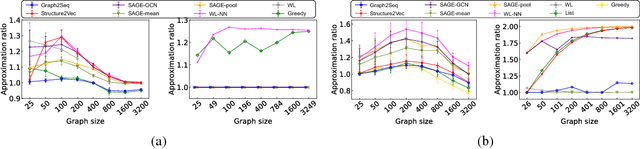
Neural networks have been shown to be an effective tool for learning algorithms over graph-structured data. However, graph representation techniques---that convert graphs to real-valued vectors for use with neural networks---are still in their infancy. Recent works have proposed several approaches (e.g., graph convolutional networks), but these methods have difficulty scaling and generalizing to graphs with different sizes and shapes. We present Graph2Seq, a new technique that represents vertices of graphs as infinite time-series. By not limiting the representation to a fixed dimension, Graph2Seq scales naturally to graphs of arbitrary sizes and shapes. Graph2Seq is also reversible, allowing full recovery of the graph structure from the sequences. By analyzing a formal computational model for graph representation, we show that an unbounded sequence is necessary for scalability. Our experimental results with Graph2Seq show strong generalization and new state-of-the-art performance on a variety of graph combinatorial optimization problems.
Variance Reduction for Reinforcement Learning in Input-Driven Environments
Oct 03, 2018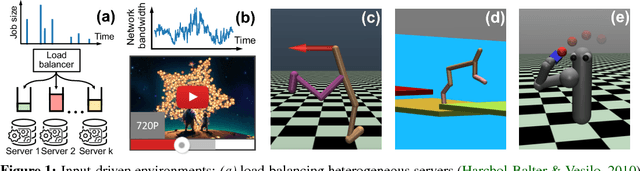
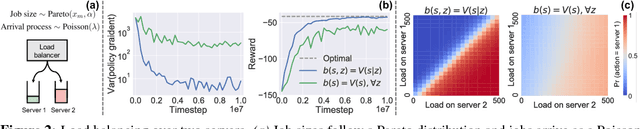
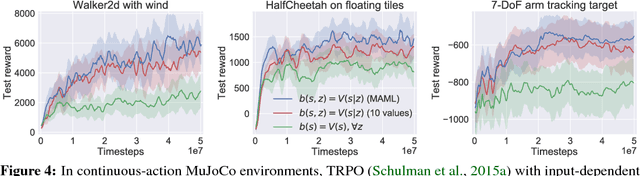
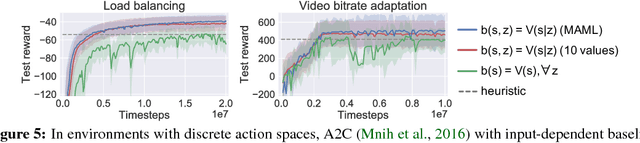
We consider reinforcement learning in input-driven environments, where an exogenous, stochastic input process affects the dynamics of the system. Input processes arise in many applications, including queuing systems, robotics control with disturbances, and object tracking. Since the state dynamics and rewards depend on the input process, the state alone provides limited information for the expected future returns. Therefore, policy gradient methods with standard state-dependent baselines suffer high variance during training. We derive a bias-free, input-dependent baseline to reduce this variance, and analytically show its benefits over state-dependent baselines. We then propose a meta-learning approach to overcome the complexity of learning a baseline that depends on a long sequence of inputs. Our experimental results show that across environments from queuing systems, computer networks, and MuJoCo robotic locomotion, input-dependent baselines consistently improve training stability and result in better eventual policies.