 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Rate Control for Video Encoding using Imitation Learning
Dec 09, 2020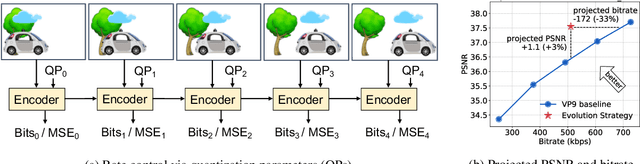
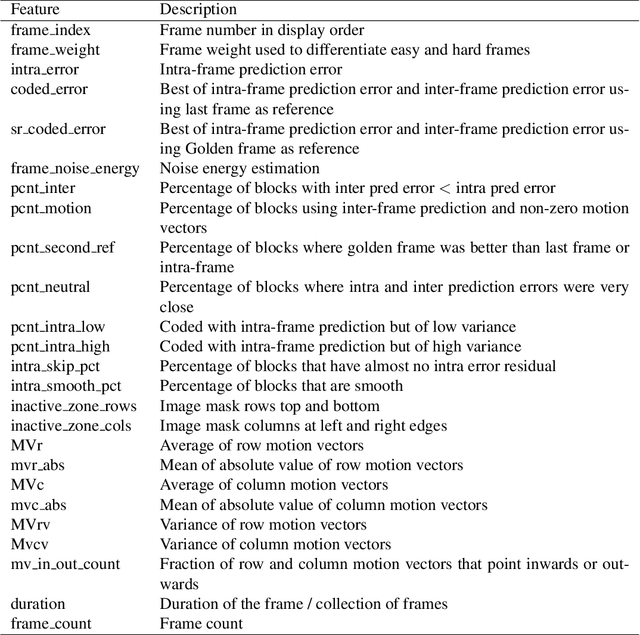
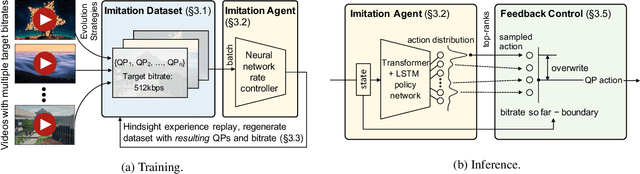
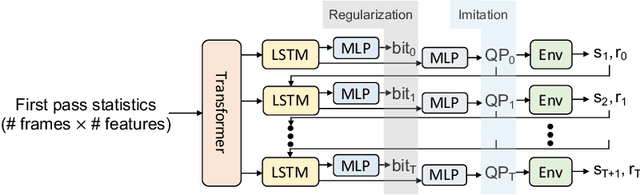
In modern video encoders, rate control is a critical component and has been heavily engineered. It decides how many bits to spend to encode each frame, in order to optimize the rate-distortion trade-off over all video frames. This is a challenging constrained planning problem because of the complex dependency among decisions for different video frames and the bitrate constraint defined at the end of the episode. We formulate the rate control problem as a Partially Observable Markov Decision Process (POMDP), and apply imitation learning to learn a neural rate control policy. We demonstrate that by learning from optimal video encoding trajectories obtained through evolution strategies, our learned policy achieves better encoding efficiency and has minimal constraint violation. In addition to imitating the optimal actions, we find that additional auxiliary losses, data augmentation/refinement and inference-time policy improvements are critical for learning a good rate control policy. We evaluate the learned policy against the rate control policy in libvpx, a widely adopted open source VP9 codec library, in the two-pass variable bitrate (VBR) mode. We show that over a diverse set of real-world videos, our learned policy achieves 8.5% median bitrate reduction without sacrificing video quality.
Real-world Video Adaptation with Reinforcement Learning
Aug 28, 2020
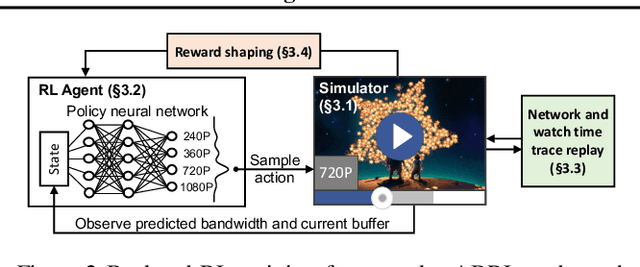
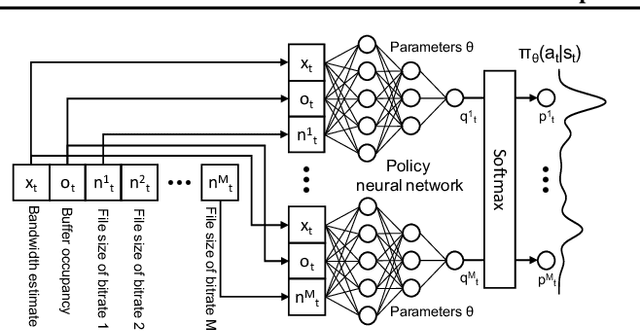
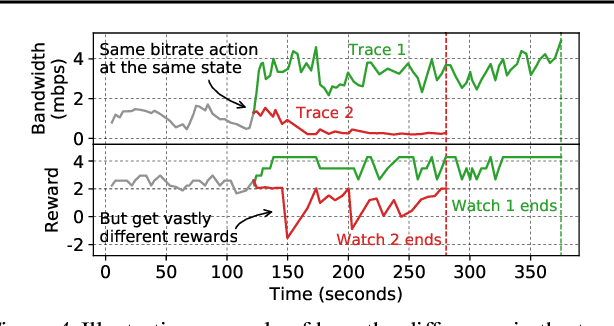
Client-side video players employ adaptive bitrate (ABR) algorithms to optimize user quality of experience (QoE). We evaluate recently proposed RL-based ABR methods in Facebook's web-based video streaming platform. Real-world ABR contains several challenges that requires customized designs beyond off-the-shelf RL algorithms -- we implement a scalable neural network architecture that supports videos with arbitrary bitrate encodings; we design a training method to cope with the variance resulting from the stochasticity in network conditions; and we leverage constrained Bayesian optimization for reward shaping in order to optimize the conflicting QoE objectives. In a week-long worldwide deployment with more than 30 million video streaming sessions, our RL approach outperforms the existing human-engineered ABR algorithms.
Explaining Deep Learning-Based Networked Systems
Oct 09, 2019
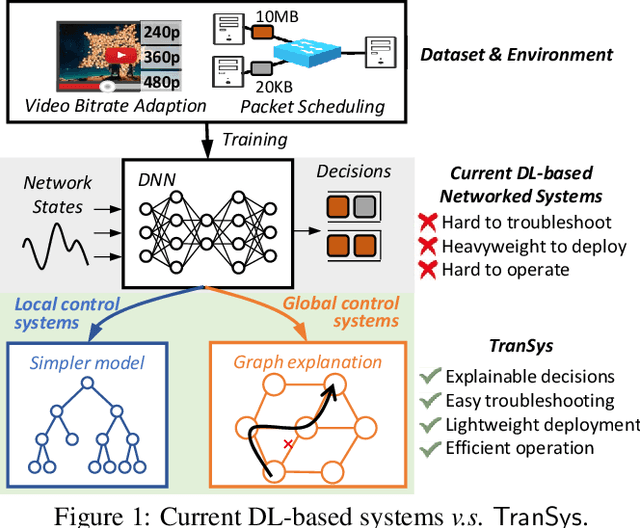
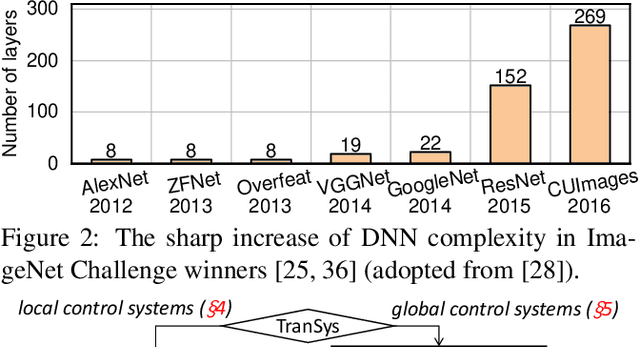

While deep learning (DL)-based networked systems have shown great potential in various applications, a key drawback is that Deep Neural Networks (DNNs) in DL are blackboxes and nontransparent for network operators. The lack of interpretability makes DL-based networked systems challenging to operate and troubleshoot, which further prevents DL-based networked systems from deploying in practice. In this paper, we propose TranSys, a novel framework to explain DL-based networked systems for practical deployment. Transys categorizes current DL-based networked systems and introduces different explanation methods based on decision tree and hypergraph to effectively explain DL-based networked systems. TranSys can explain the DNN policies in the form of decision trees and highlight critical components based on analysis over hypergraph. We evaluate TranSys over several typical DL-based networked systems and demonstrate that Transys can provide human-readable explanations for network operators. We also present three use cases of Transys, which could (i) help network operators troubleshoot DL-based networked systems, (ii) improve the decision latency and resource consumption of DL-based networked systems by ~10x on different metrics, and (iii) provide suggestions on daily operations for network operators when incidences occur.
Placeto: Learning Generalizable Device Placement Algorithms for Distributed Machine Learning
Jun 20, 2019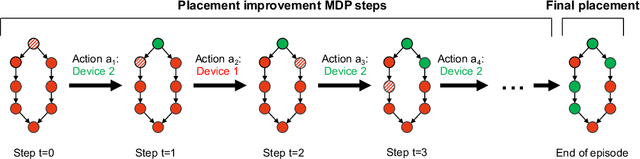
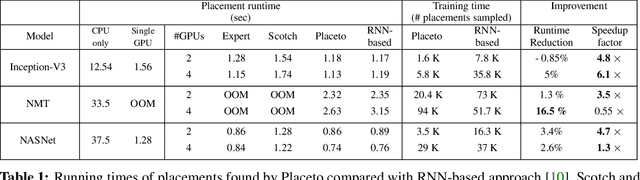
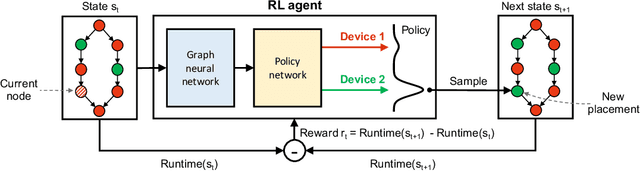
We present Placeto, a reinforcement learning (RL) approach to efficiently find device placements for distributed neural network training. Unlike prior approaches that only find a device placement for a specific computation graph, Placeto can learn generalizable device placement policies that can be applied to any graph. We propose two key ideas in our approach: (1) we represent the policy as performing iterative placement improvements, rather than outputting a placement in one shot; (2) we use graph embeddings to capture relevant information about the structure of the computation graph, without relying on node labels for indexing. These ideas allow Placeto to train efficiently and generalize to unseen graphs. Our experiments show that Placeto requires up to 6.1x fewer training steps to find placements that are on par with or better than the best placements found by prior approaches. Moreover, Placeto is able to learn a generalizable placement policy for any given family of graphs, which can then be used without any retraining to predict optimized placements for unseen graphs from the same family. This eliminates the large overhead incurred by prior RL approaches whose lack of generalizability necessitates re-training from scratch every time a new graph is to be placed.
Learning Scheduling Algorithms for Data Processing Clusters
Oct 12, 2018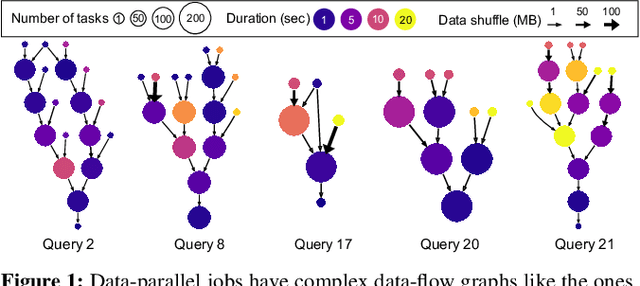

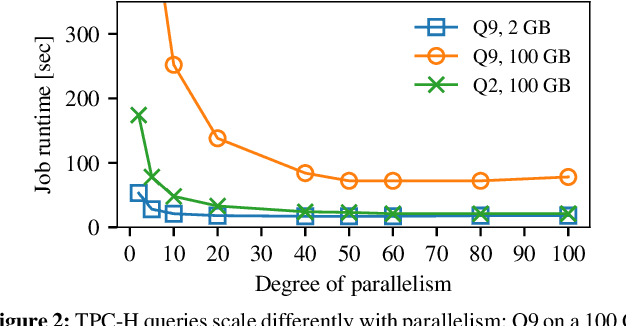

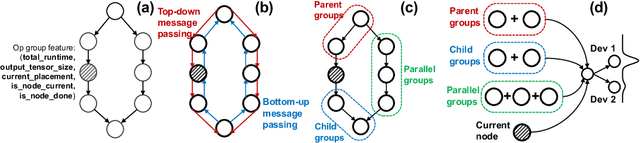
Efficiently scheduling data processing jobs on distributed compute clusters requires complex algorithms. Current systems, however, use simple generalized heuristics and ignore workload structure, since developing and tuning a bespoke heuristic for each workload is infeasible. In this paper, we show that modern machine learning techniques can generate highly-efficient policies automatically. Decima uses reinforcement learning (RL) and neural networks to learn workload-specific scheduling algorithms without any human instruction beyond specifying a high-level objective such as minimizing average job completion time. Off-the-shelf RL techniques, however, cannot handle the complexity and scale of the scheduling problem. To build Decima, we had to develop new representations for jobs' dependency graphs, design scalable RL models, and invent new RL training methods for continuous job arrivals. Our prototype integration with Spark on a 25-node cluster shows that Decima outperforms several heuristics, including hand-tuned ones, by at least 21%. Further experiments with an industrial production workload trace demonstrate that Decima delivers up to a 17% reduction in average job completion time and scales to large clusters.
Variance Reduction for Reinforcement Learning in Input-Driven Environments
Oct 03, 2018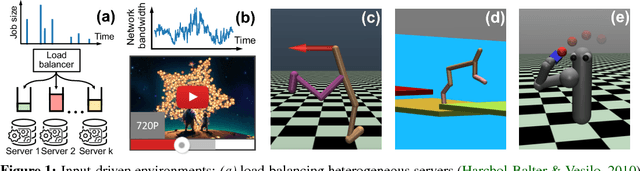
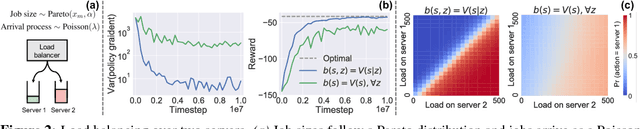
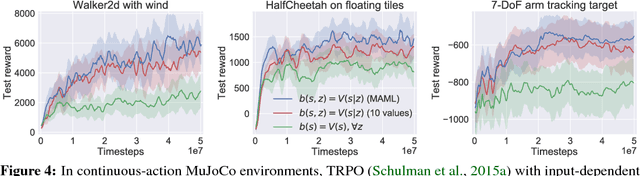
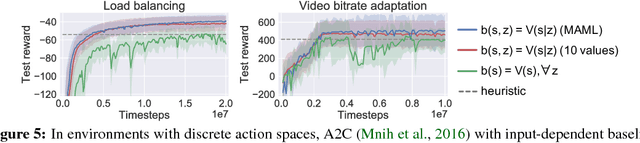
We consider reinforcement learning in input-driven environments, where an exogenous, stochastic input process affects the dynamics of the system. Input processes arise in many applications, including queuing systems, robotics control with disturbances, and object tracking. Since the state dynamics and rewards depend on the input process, the state alone provides limited information for the expected future returns. Therefore, policy gradient methods with standard state-dependent baselines suffer high variance during training. We derive a bias-free, input-dependent baseline to reduce this variance, and analytically show its benefits over state-dependent baselines. We then propose a meta-learning approach to overcome the complexity of learning a baseline that depends on a long sequence of inputs. Our experimental results show that across environments from queuing systems, computer networks, and MuJoCo robotic locomotion, input-dependent baselines consistently improve training stability and result in better eventual policies.