 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontier LLMs Still Struggle with Simple Reasoning Tasks
Jul 09, 2025
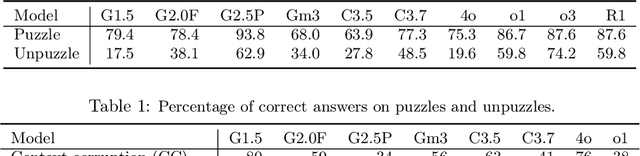
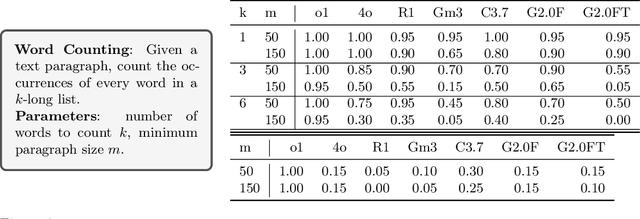
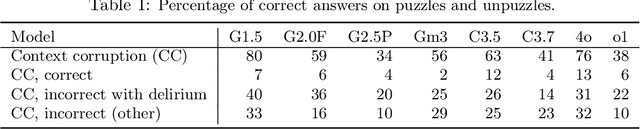
While state-of-the-art large language models (LLMs) demonstrate advanced reasoning capabilities-achieving remarkable performance on challenging competitive math and coding benchmarks-they also frequently fail on tasks that are easy for humans. This work studies the performance of frontier LLMs on a broad set of such "easy" reasoning problems. By extending previous work in the literature, we create a suite of procedurally generated simple reasoning tasks, including counting, first-order logic, proof trees, and travel planning, with changeable parameters (such as document length. or the number of variables in a math problem) that can arbitrarily increase the amount of computation required to produce the answer while preserving the fundamental difficulty. While previous work showed that traditional, non-thinking models can be made to fail on such problems, we demonstrate that even state-of-the-art thinking models consistently fail on such problems and for similar reasons (e.g. statistical shortcuts, errors in intermediate steps, and difficulties in processing long contexts). To further understand the behavior of the models, we introduce the unpuzzles dataset, a different "easy" benchmark consisting of trivialized versions of well-known math and logic puzzles. Interestingly, while modern LLMs excel at solving the original puzzles, they tend to fail on the trivialized versions, exhibiting several systematic failure patterns related to memorizing the originals. We show that this happens even if the models are otherwise able to solve problems with different descriptions but requiring the same logic. Our results highlight that out-of-distribution generalization is still problematic for frontier language models and the new generation of thinking models, even for simple reasoning tasks, and making tasks easier does not necessarily imply improved performance.
Achieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Robotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023



We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.
Towards practical reinforcement learning for tokamak magnetic control
Jul 21, 2023



Reinforcement learning (RL) has shown promising results for real-time control systems, including the domain of plasma magnetic control. However, there are still significant drawbacks compared to traditional feedback control approaches for magnetic confinement. In this work, we address key drawbacks of the RL method; achieving higher control accuracy for desired plasma properties, reducing the steady-state error, and decreasing the required time to learn new tasks. We build on top of \cite{degrave2022magnetic}, and present algorithmic improvements to the agent architecture and training procedure. We present simulation results that show up to 65\% improvement in shape accuracy, achieve substantial reduction in the long-term bias of the plasma current, and additionally reduce the training time required to learn new tasks by a factor of 3 or more. We present new experiments using the upgraded RL-based controllers on the TCV tokamak, which validate the simulation results achieved, and point the way towards routinely achieving accurate discharges using the RL approach.
Sample Efficient Deep Reinforcement Learning via Local Planning
Jan 29, 2023



The focus of this work is sample-efficient deep reinforcement learning (RL) with a simulator. One useful property of simulators is that it is typically easy to reset the environment to a previously observed state. We propose an algorithmic framework, named uncertainty-first local planning (UFLP), that takes advantage of this property. Concretely, in each data collection iteration, with some probability, our meta-algorithm resets the environment to an observed state which has high uncertainty, instead of sampling according to the initial-state distribution. The agent-environment interaction then proceeds as in the standard online RL setting. We demonstrate that this simple procedure can dramatically improve the sample cost of several baseline RL algorithms on difficult exploration tasks. Notably, with our framework, we can achieve super-human performance on the notoriously hard Atari game, Montezuma's Revenge, with a simple (distributional) double DQN. Our work can be seen as an efficient approximate implementation of an existing algorithm with theoretical guarantees, which offers an interpretation of the positive empirical results.
A New Look at Dynamic Regret for Non-Stationary Stochastic Bandits
Jan 17, 2022We study the non-stationary stochastic multi-armed bandit problem, where the reward statistics of each arm may change several times during the course of learning. The performance of a learning algorithm is evaluated in terms of their dynamic regret, which is defined as the difference of the expected cumulative reward of an agent choosing the optimal arm in every round and the cumulative reward of the learning algorithm. One way to measure the hardness of such environments is to consider how many times the identity of the optimal arm can change. We propose a method that achieves, in $K$-armed bandit problems, a near-optimal $\widetilde O(\sqrt{K N(S+1)})$ dynamic regret, where $N$ is the number of rounds and $S$ is the number of times the identity of the optimal arm changes, without prior knowledge of $S$ and $N$. Previous works for this problem obtain regret bounds that scale with the number of changes (or the amount of change) in the reward functions, which can be much larger, or assume prior knowledge of $S$ to achieve similar bounds.
Improved Regret Bound and Experience Replay in Regularized Policy Iteration
Feb 25, 2021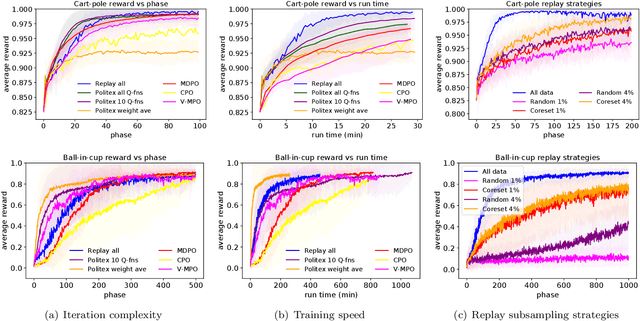
In this work, we study algorithms for learning in infinite-horizon undiscounted Markov decision processes (MDPs) with function approximation. We first show that the regret analysis of the Politex algorithm (a version of regularized policy iteration) can be sharpened from $O(T^{3/4})$ to $O(\sqrt{T})$ under nearly identical assumptions, and instantiate the bound with linear function approximation. Our result provides the first high-probability $O(\sqrt{T})$ regret bound for a computationally efficient algorithm in this setting. The exact implementation of Politex with neural network function approximation is inefficient in terms of memory and computation. Since our analysis suggests that we need to approximate the average of the action-value functions of past policies well, we propose a simple efficient implementation where we train a single Q-function on a replay buffer with past data. We show that this often leads to superior performance over other implementation choices, especially in terms of wall-clock time. Our work also provides a novel theoretical justification for using experience replay within policy iteration algorithms.
Neural Rate Control for Video Encoding using Imitation Learning
Dec 09, 2020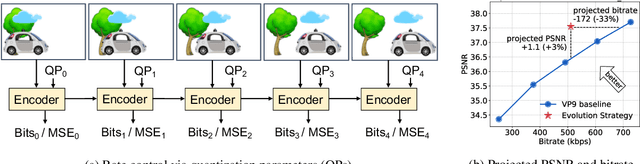
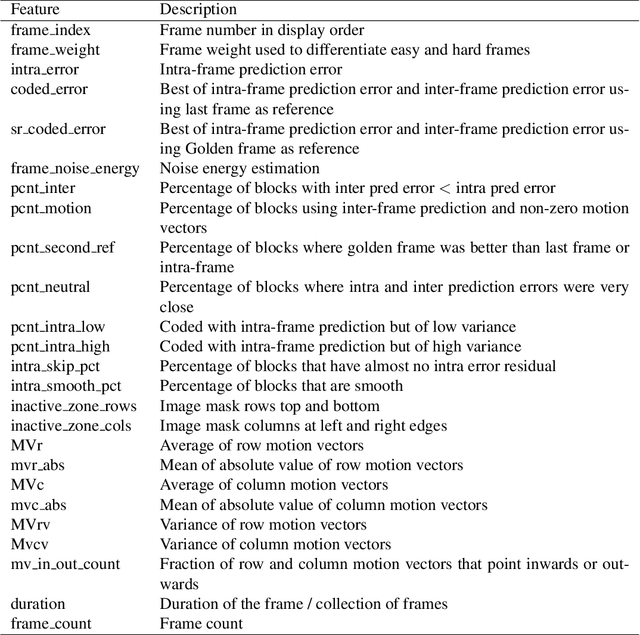
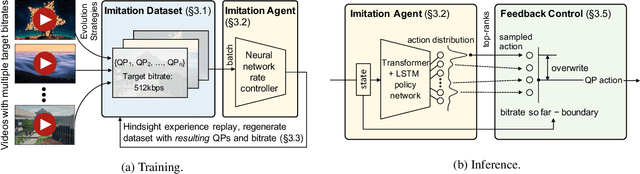
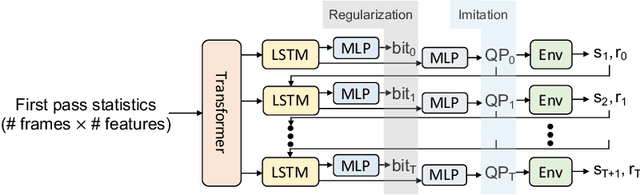
In modern video encoders, rate control is a critical component and has been heavily engineered. It decides how many bits to spend to encode each frame, in order to optimize the rate-distortion trade-off over all video frames. This is a challenging constrained planning problem because of the complex dependency among decisions for different video frames and the bitrate constraint defined at the end of the episode. We formulate the rate control problem as a Partially Observable Markov Decision Process (POMDP), and apply imitation learning to learn a neural rate control policy. We demonstrate that by learning from optimal video encoding trajectories obtained through evolution strategies, our learned policy achieves better encoding efficiency and has minimal constraint violation. In addition to imitating the optimal actions, we find that additional auxiliary losses, data augmentation/refinement and inference-time policy improvements are critical for learning a good rate control policy. We evaluate the learned policy against the rate control policy in libvpx, a widely adopted open source VP9 codec library, in the two-pass variable bitrate (VBR) mode. We show that over a diverse set of real-world videos, our learned policy achieves 8.5% median bitrate reduction without sacrificing video quality.
A maximum-entropy approach to off-policy evaluation in average-reward MDPs
Jun 17, 2020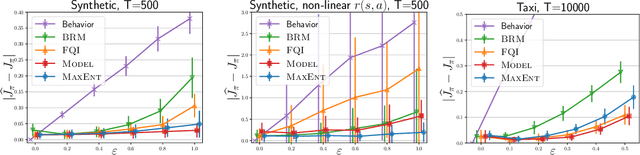
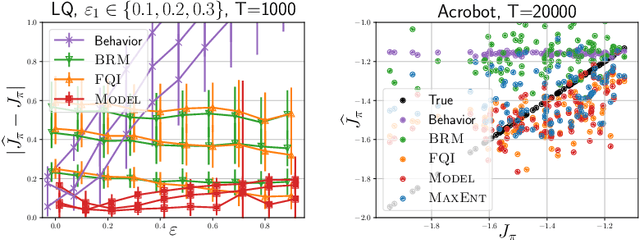
This work focuses on off-policy evaluation (OPE) with function approximation in infinite-horizon undiscounted Markov decision processes (MDPs). For MDPs that are ergodic and linear (i.e. where rewards and dynamics are linear in some known features), we provide the first finite-sample OPE error bound, extending existing results beyond the episodic and discounted cases. In a more general setting, when the feature dynamics are approximately linear and for arbitrary rewards, we propose a new approach for estimating stationary distributions with function approximation. We formulate this problem as finding the maximum-entropy distribution subject to matching feature expectations under empirical dynamics. We show that this results in an exponential-family distribution whose sufficient statistics are the features, paralleling maximum-entropy approaches in supervised learning. We demonstrate the effectiveness of the proposed OPE approaches in multiple environments.
Robotic Table Tennis with Model-Free Reinforcement Learning
Mar 31, 2020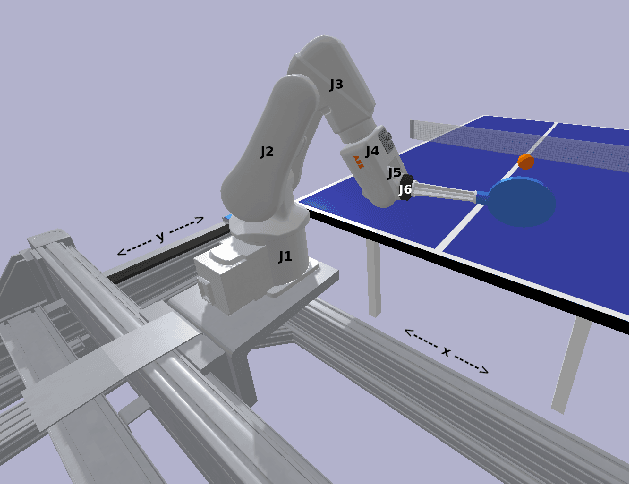
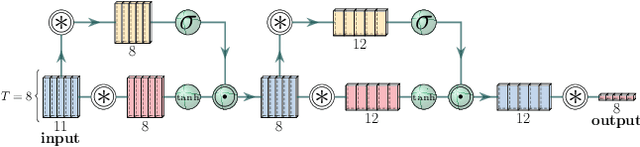
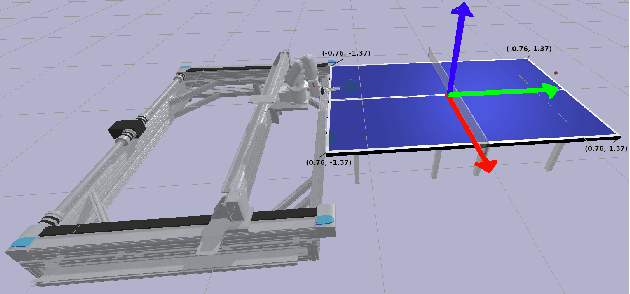

We propose a model-free algorithm for learning efficient policies capable of returning table tennis balls by controlling robot joints at a rate of 100Hz. We demonstrate that evolutionary search (ES) methods acting on CNN-based policy architectures for non-visual inputs and convolving across time learn compact controllers leading to smooth motions. Furthermore, we show that with appropriately tuned curriculum learning on the task and rewards, policies are capable of developing multi-modal styles, specifically forehand and backhand stroke, whilst achieving 80\% return rate on a wide range of ball throws. We observe that multi-modality does not require any architectural priors, such as multi-head architectures or hierarchical policies.