 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein Policy Optimization
May 01, 2025



We introduce Wasserstein Policy Optimization (WPO), an actor-critic algorithm for reinforcement learning in continuous action spaces. WPO can be derived as an approximation to Wasserstein gradient flow over the space of all policies projected into a finite-dimensional parameter space (e.g., the weights of a neural network), leading to a simple and completely general closed-form update. The resulting algorithm combines many properties of deterministic and classic policy gradient methods. Like deterministic policy gradients, it exploits knowledge of the gradient of the action-value function with respect to the action. Like classic policy gradients, it can be applied to stochastic policies with arbitrary distributions over actions -- without using the reparameterization trick. We show results on the DeepMind Control Suite and a magnetic confinement fusion task which compare favorably with state-of-the-art continuous control methods.
Towards practical reinforcement learning for tokamak magnetic control
Jul 21, 2023



Reinforcement learning (RL) has shown promising results for real-time control systems, including the domain of plasma magnetic control. However, there are still significant drawbacks compared to traditional feedback control approaches for magnetic confinement. In this work, we address key drawbacks of the RL method; achieving higher control accuracy for desired plasma properties, reducing the steady-state error, and decreasing the required time to learn new tasks. We build on top of \cite{degrave2022magnetic}, and present algorithmic improvements to the agent architecture and training procedure. We present simulation results that show up to 65\% improvement in shape accuracy, achieve substantial reduction in the long-term bias of the plasma current, and additionally reduce the training time required to learn new tasks by a factor of 3 or more. We present new experiments using the upgraded RL-based controllers on the TCV tokamak, which validate the simulation results achieved, and point the way towards routinely achieving accurate discharges using the RL approach.
One Step at a Time: Pros and Cons of Multi-Step Meta-Gradient Reinforcement Learning
Oct 30, 2021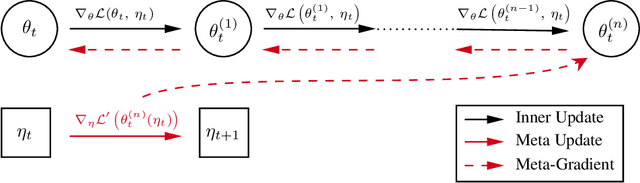

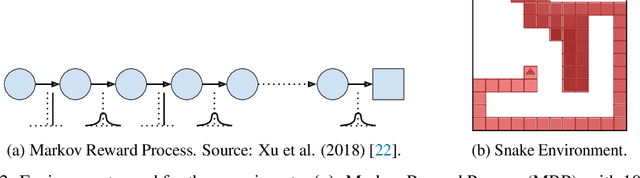
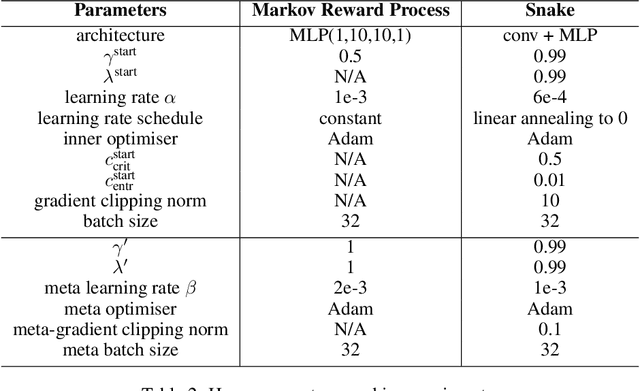
Self-tuning algorithms that adapt the learning process online encourage more effective and robust learning. Among all the methods available, meta-gradients have emerged as a promising approach. They leverage the differentiability of the learning rule with respect to some hyper-parameters to adapt them in an online fashion. Although meta-gradients can be accumulated over multiple learning steps to avoid myopic updates, this is rarely used in practice. In this work, we demonstrate that whilst multi-step meta-gradients do provide a better learning signal in expectation, this comes at the cost of a significant increase in variance, hindering performance. In the light of this analysis, we introduce a novel method mixing multiple inner steps that enjoys a more accurate and robust meta-gradient signal, essentially trading off bias and variance in meta-gradient estimation. When applied to the Snake game, the mixing meta-gradient algorithm can cut the variance by a factor of 3 while achieving similar or higher performance.
Fully Distributed Actor-Critic Architecture for Multitask Deep Reinforcement Learning
Oct 23, 2021We propose a fully distributed actor-critic architecture, named Diff-DAC, with application to multitask reinforcement learning (MRL). During the learning process, agents communicate their value and policy parameters to their neighbours, diffusing the information across a network of agents with no need for a central station. Each agent can only access data from its local task, but aims to learn a common policy that performs well for the whole set of tasks. The architecture is scalable, since the computational and communication cost per agent depends on the number of neighbours rather than the overall number of agents. We derive Diff-DAC from duality theory and provide novel insights into the actor-critic framework, showing that it is actually an instance of the dual ascent method. We prove almost sure convergence of Diff-DAC to a common policy under general assumptions that hold even for deep-neural network approximations. For more restrictive assumptions, we also prove that this common policy is a stationary point of an approximation of the original problem. Numerical results on multitask extensions of common continuous control benchmarks demonstrate that Diff-DAC stabilises learning and has a regularising effect that induces higher performance and better generalisation properties than previous architectures.
* 27 pages, 8 figures
Kernel Identification Through Transformers
Jun 15, 2021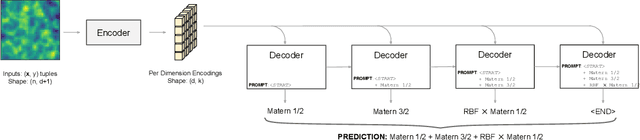
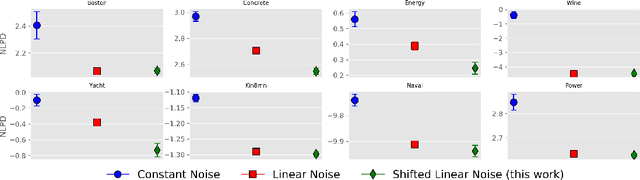
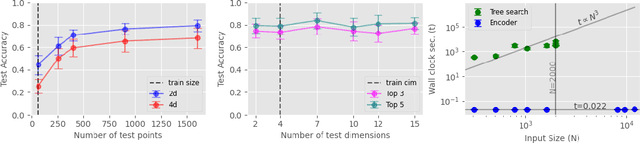
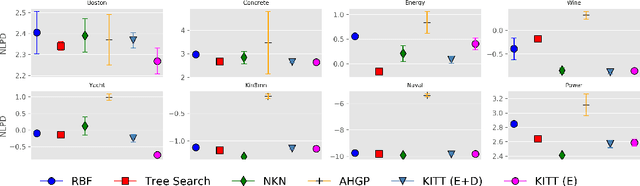
Kernel selection plays a central role in determining the performance of Gaussian Process (GP) models, as the chosen kernel determines both the inductive biases and prior support of functions under the GP prior. This work addresses the challenge of constructing custom kernel functions for high-dimensional GP regression models. Drawing inspiration from recent progress in deep learning, we introduce a novel approach named KITT: Kernel Identification Through Transformers. KITT exploits a transformer-based architecture to generate kernel recommendations in under 0.1 seconds, which is several orders of magnitude faster than conventional kernel search algorithms. We train our model using synthetic data generated from priors over a vocabulary of known kernels. By exploiting the nature of the self-attention mechanism, KITT is able to process datasets with inputs of arbitrary dimension. We demonstrate that kernels chosen by KITT yield strong performance over a diverse collection of regression benchmarks.
Learning to Model Opponent Learning
Jun 06, 2020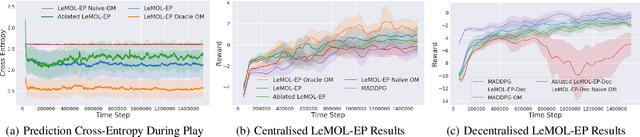

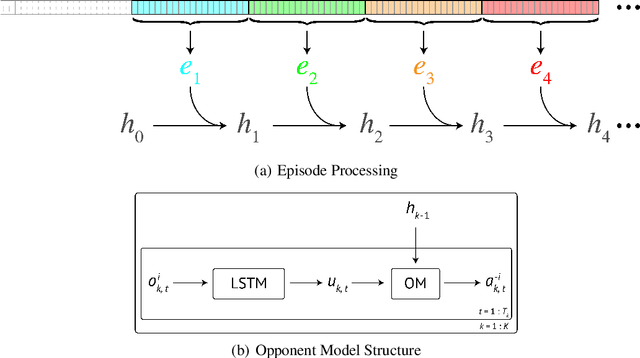

Multi-Agent Reinforcement Learning (MARL) considers settings in which a set of coexisting agents interact with one another and their environment. The adaptation and learning of other agents induces non-stationarity in the environment dynamics. This poses a great challenge for value function-based algorithms whose convergence usually relies on the assumption of a stationary environment. Policy search algorithms also struggle in multi-agent settings as the partial observability resulting from an opponent's actions not being known introduces high variance to policy training. Modelling an agent's opponent(s) is often pursued as a means of resolving the issues arising from the coexistence of learning opponents. An opponent model provides an agent with some ability to reason about other agents to aid its own decision making. Most prior works learn an opponent model by assuming the opponent is employing a stationary policy or switching between a set of stationary policies. Such an approach can reduce the variance of training signals for policy search algorithms. However, in the multi-agent setting, agents have an incentive to continually adapt and learn. This means that the assumptions concerning opponent stationarity are unrealistic. In this work, we develop a novel approach to modelling an opponent's learning dynamics which we term Learning to Model Opponent Learning (LeMOL). We show our structured opponent model is more accurate and stable than naive behaviour cloning baselines. We further show that opponent modelling can improve the performance of algorithmic agents in multi-agent settings.