 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Towards practical reinforcement learning for tokamak magnetic control
Jul 21, 2023



Reinforcement learning (RL) has shown promising results for real-time control systems, including the domain of plasma magnetic control. However, there are still significant drawbacks compared to traditional feedback control approaches for magnetic confinement. In this work, we address key drawbacks of the RL method; achieving higher control accuracy for desired plasma properties, reducing the steady-state error, and decreasing the required time to learn new tasks. We build on top of \cite{degrave2022magnetic}, and present algorithmic improvements to the agent architecture and training procedure. We present simulation results that show up to 65\% improvement in shape accuracy, achieve substantial reduction in the long-term bias of the plasma current, and additionally reduce the training time required to learn new tasks by a factor of 3 or more. We present new experiments using the upgraded RL-based controllers on the TCV tokamak, which validate the simulation results achieved, and point the way towards routinely achieving accurate discharges using the RL approach.
Optimizing Memory Mapping Using Deep Reinforcement Learning
May 11, 2023



Resource scheduling and allocation is a critical component of many high impact systems ranging from congestion control to cloud computing. Finding more optimal solutions to these problems often has significant impact on resource and time savings, reducing device wear-and-tear, and even potentially improving carbon emissions. In this paper, we focus on a specific instance of a scheduling problem, namely the memory mapping problem that occurs during compilation of machine learning programs: That is, mapping tensors to different memory layers to optimize execution time. We introduce an approach for solving the memory mapping problem using Reinforcement Learning. RL is a solution paradigm well-suited for sequential decision making problems that are amenable to planning, and combinatorial search spaces with high-dimensional data inputs. We formulate the problem as a single-player game, which we call the mallocGame, such that high-reward trajectories of the game correspond to efficient memory mappings on the target hardware. We also introduce a Reinforcement Learning agent, mallocMuZero, and show that it is capable of playing this game to discover new and improved memory mapping solutions that lead to faster execution times on real ML workloads on ML accelerators. We compare the performance of mallocMuZero to the default solver used by the Accelerated Linear Algebra (XLA) compiler on a benchmark of realistic ML workloads. In addition, we show that mallocMuZero is capable of improving the execution time of the recently published AlphaTensor matrix multiplication model.
Transformers Meet Directed Graphs
Jan 31, 2023Transformers were originally proposed as a sequence-to-sequence model for text but have become vital for a wide range of modalities, including images, audio, video, and undirected graphs. However, transformers for directed graphs are a surprisingly underexplored topic, despite their applicability to ubiquitous domains including source code and logic circuits. In this work, we propose two direction- and structure-aware positional encodings for directed graphs: (1) the eigenvectors of the Magnetic Laplacian - a direction-aware generalization of the combinatorial Laplacian; (2) directional random walk encodings. Empirically, we show that the extra directionality information is useful in various downstream tasks, including correctness testing of sorting networks and source code understanding. Together with a data-flow-centric graph construction, our model outperforms the prior state of the art on the Open Graph Benchmark Code2 relatively by 14.7%.
Controlling Commercial Cooling Systems Using Reinforcement Learning
Nov 11, 2022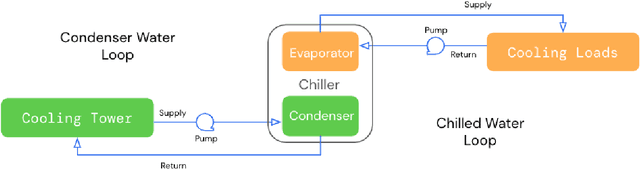
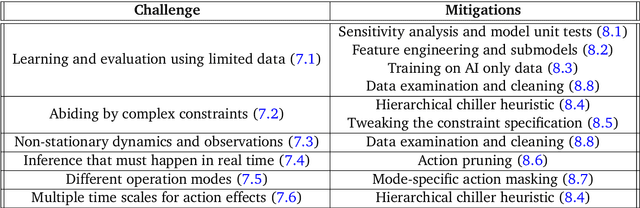
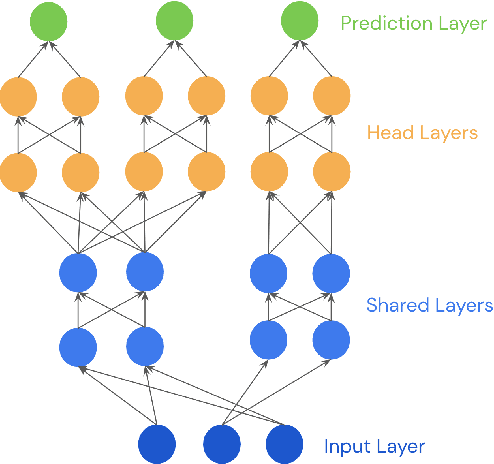
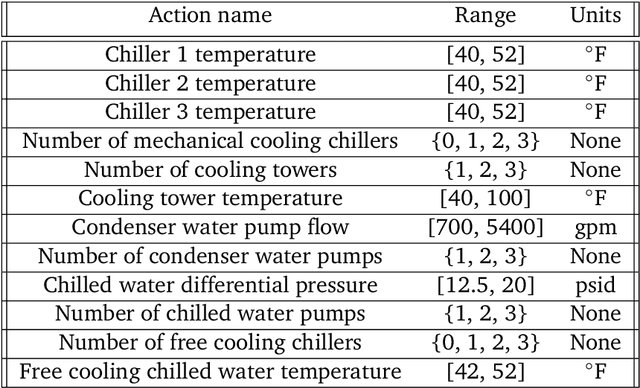
This paper is a technical overview of DeepMind and Google's recent work on reinforcement learning for controlling commercial cooling systems. Building on expertise that began with cooling Google's data centers more efficiently, we recently conducted live experiments on two real-world facilities in partnership with Trane Technologies, a building management system provider. These live experiments had a variety of challenges in areas such as evaluation, learning from offline data, and constraint satisfaction. Our paper describes these challenges in the hope that awareness of them will benefit future applied RL work. We also describe the way we adapted our RL system to deal with these challenges, resulting in energy savings of approximately 9% and 13% respectively at the two live experiment sites.
Optimizing Industrial HVAC Systems with Hierarchical Reinforcement Learning
Sep 16, 2022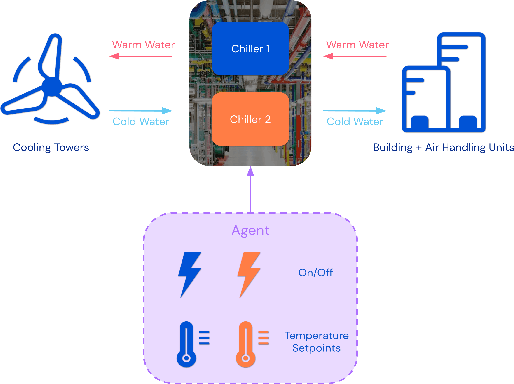
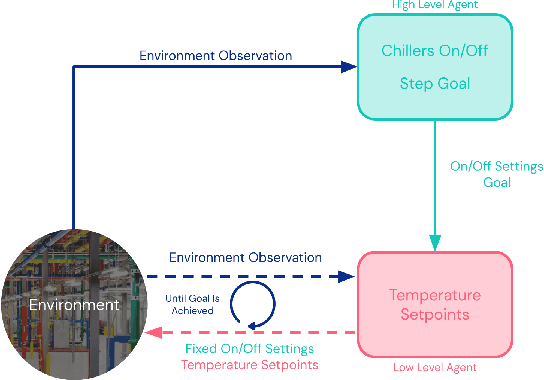
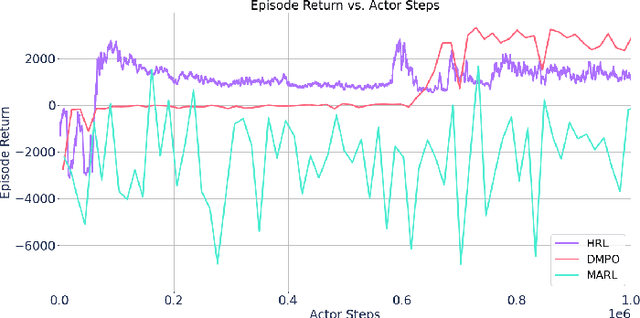
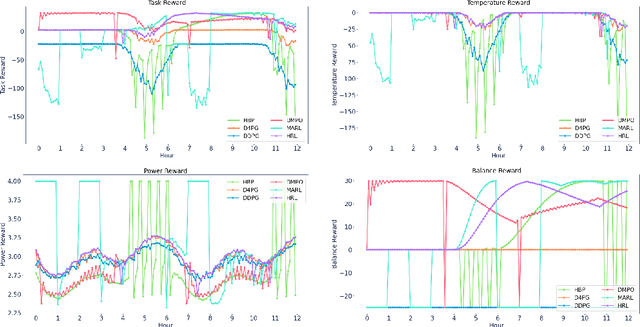
Reinforcement learning (RL) techniques have been developed to optimize industrial cooling systems, offering substantial energy savings compared to traditional heuristic policies. A major challenge in industrial control involves learning behaviors that are feasible in the real world due to machinery constraints. For example, certain actions can only be executed every few hours while other actions can be taken more frequently. Without extensive reward engineering and experimentation, an RL agent may not learn realistic operation of machinery. To address this, we use hierarchical reinforcement learning with multiple agents that control subsets of actions according to their operation time scales. Our hierarchical approach achieves energy savings over existing baselines while maintaining constraints such as operating chillers within safe bounds in a simulated HVAC control environment.
Semi-analytical Industrial Cooling System Model for Reinforcement Learning
Jul 26, 2022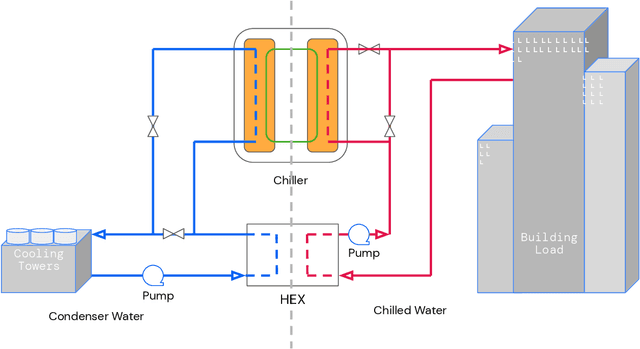
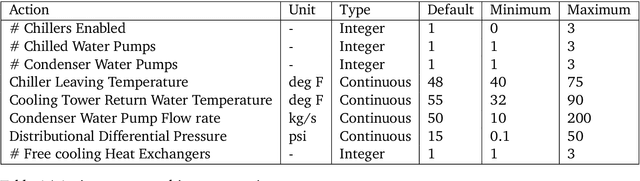
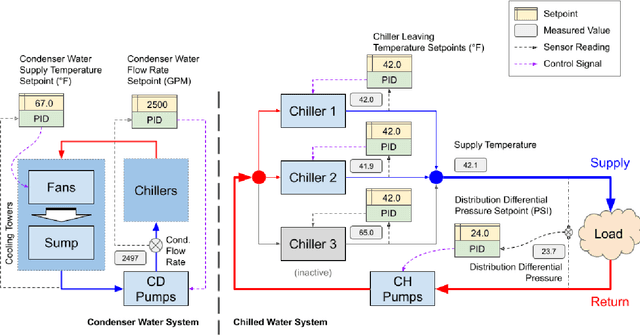
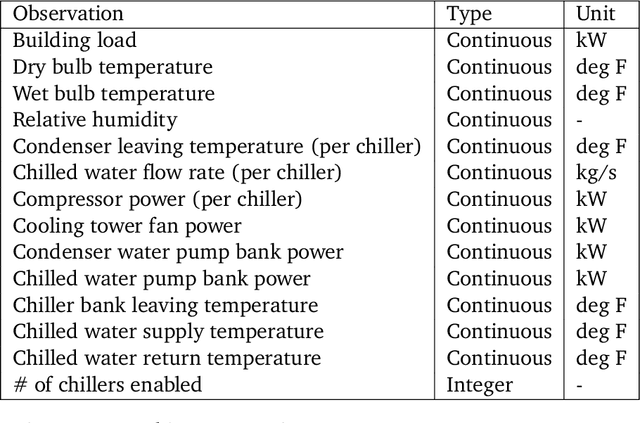
We present a hybrid industrial cooling system model that embeds analytical solutions within a multi-physics simulation. This model is designed for reinforcement learning (RL) applications and balances simplicity with simulation fidelity and interpretability. The model's fidelity is evaluated against real world data from a large scale cooling system. This is followed by a case study illustrating how the model can be used for RL research. For this, we develop an industrial task suite that allows specifying different problem settings and levels of complexity, and use it to evaluate the performance of different RL algorithms.
COptiDICE: Offline Constrained Reinforcement Learning via Stationary Distribution Correction Estimation
Apr 19, 2022
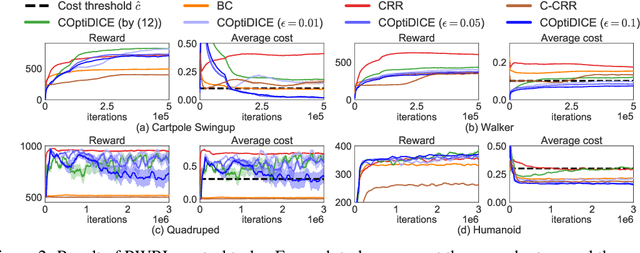


We consider the offline constrained reinforcement learning (RL) problem, in which the agent aims to compute a policy that maximizes expected return while satisfying given cost constraints, learning only from a pre-collected dataset. This problem setting is appealing in many real-world scenarios, where direct interaction with the environment is costly or risky, and where the resulting policy should comply with safety constraints. However, it is challenging to compute a policy that guarantees satisfying the cost constraints in the offline RL setting, since the off-policy evaluation inherently has an estimation error. In this paper, we present an offline constrained RL algorithm that optimizes the policy in the space of the stationary distribution. Our algorithm, COptiDICE, directly estimates the stationary distribution corrections of the optimal policy with respect to returns, while constraining the cost upper bound, with the goal of yielding a cost-conservative policy for actual constraint satisfaction. Experimental results show that COptiDICE attains better policies in terms of constraint satisfaction and return-maximization, outperforming baseline algorithms.
Active Offline Policy Selection
Jun 18, 2021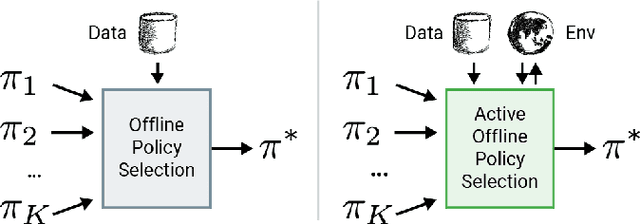
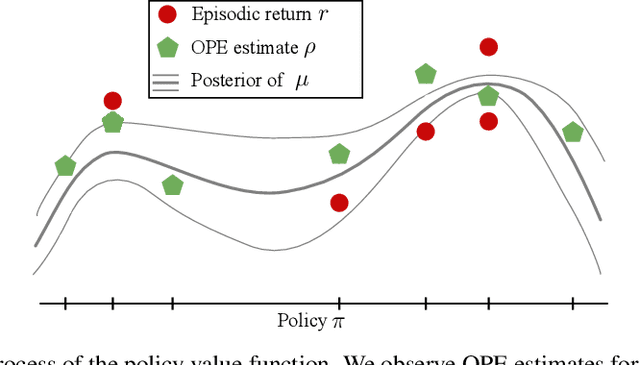
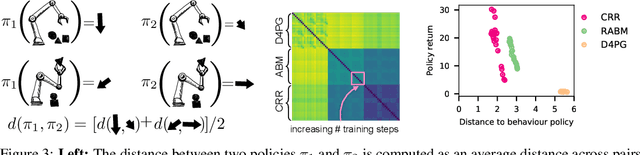

This paper addresses the problem of policy selection in domains with abundant logged data, but with a very restricted interaction budget. Solving this problem would enable safe evaluation and deployment of offline reinforcement learning policies in industry, robotics, and healthcare domain among others. Several off-policy evaluation (OPE) techniques have been proposed to assess the value of policies using only logged data. However, there is still a big gap between the evaluation by OPE and the full online evaluation in the real environment. To reduce this gap, we introduce a novel \emph{active offline policy selection} problem formulation, which combined logged data and limited online interactions to identify the best policy. We rely on the advances in OPE to warm start the evaluation. We build upon Bayesian optimization to iteratively decide which policies to evaluate in order to utilize the limited environment interactions wisely. Many candidate policies could be proposed, thus, we focus on making our approach scalable and introduce a kernel function to model similarity between policies. We use several benchmark environments to show that the proposed approach improves upon state-of-the-art OPE estimates and fully online policy evaluation with limited budget. Additionally, we show that each component of the proposed method is important, it works well with various number and quality of OPE estimates and even with a large number of candidate policies.
Autoregressive Dynamics Models for Offline Policy Evaluation and Optimization
Apr 28, 2021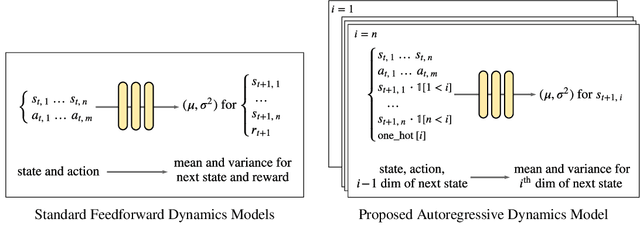

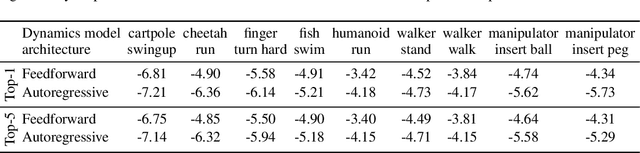
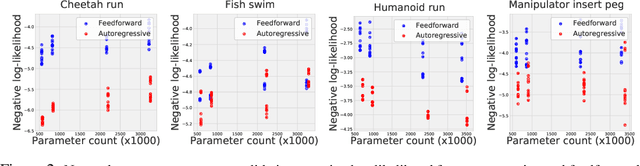
Standard dynamics models for continuous control make use of feedforward computation to predict the conditional distribution of next state and reward given current state and action using a multivariate Gaussian with a diagonal covariance structure. This modeling choice assumes that different dimensions of the next state and reward are conditionally independent given the current state and action and may be driven by the fact that fully observable physics-based simulation environments entail deterministic transition dynamics. In this paper, we challenge this conditional independence assumption and propose a family of expressive autoregressive dynamics models that generate different dimensions of the next state and reward sequentially conditioned on previous dimensions. We demonstrate that autoregressive dynamics models indeed outperform standard feedforward models in log-likelihood on heldout transitions. Furthermore, we compare different model-based and model-free off-policy evaluation (OPE) methods on RL Unplugged, a suite of offline MuJoCo datasets, and find that autoregressive dynamics models consistently outperform all baselines, achieving a new state-of-the-art. Finally, we show that autoregressive dynamics models are useful for offline policy optimization by serving as a way to enrich the replay buffer through data augmentation and improving performance using model-based planning.