 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Online Algorithms via ML Predictions
Jul 25, 2024In this work we study the problem of using machine-learned predictions to improve the performance of online algorithms. We consider two classical problems, ski rental and non-clairvoyant job scheduling, and obtain new online algorithms that use predictions to make their decisions. These algorithms are oblivious to the performance of the predictor, improve with better predictions, but do not degrade much if the predictions are poor.
Optimizing Memory Mapping Using Deep Reinforcement Learning
May 11, 2023



Resource scheduling and allocation is a critical component of many high impact systems ranging from congestion control to cloud computing. Finding more optimal solutions to these problems often has significant impact on resource and time savings, reducing device wear-and-tear, and even potentially improving carbon emissions. In this paper, we focus on a specific instance of a scheduling problem, namely the memory mapping problem that occurs during compilation of machine learning programs: That is, mapping tensors to different memory layers to optimize execution time. We introduce an approach for solving the memory mapping problem using Reinforcement Learning. RL is a solution paradigm well-suited for sequential decision making problems that are amenable to planning, and combinatorial search spaces with high-dimensional data inputs. We formulate the problem as a single-player game, which we call the mallocGame, such that high-reward trajectories of the game correspond to efficient memory mappings on the target hardware. We also introduce a Reinforcement Learning agent, mallocMuZero, and show that it is capable of playing this game to discover new and improved memory mapping solutions that lead to faster execution times on real ML workloads on ML accelerators. We compare the performance of mallocMuZero to the default solver used by the Accelerated Linear Algebra (XLA) compiler on a benchmark of realistic ML workloads. In addition, we show that mallocMuZero is capable of improving the execution time of the recently published AlphaTensor matrix multiplication model.
Parsimonious Learning-Augmented Caching
Feb 09, 2022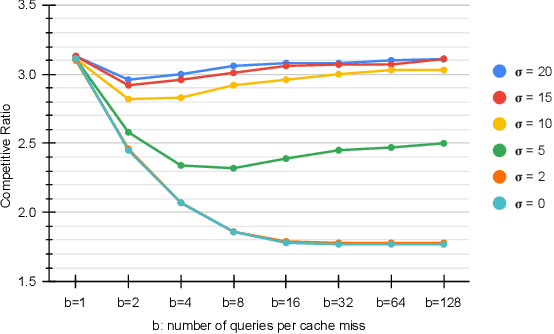
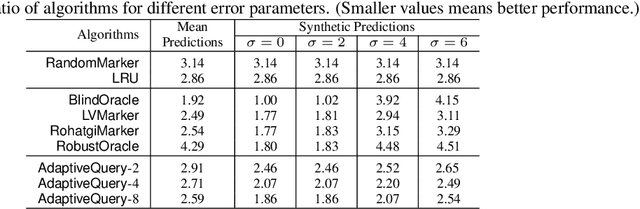
Learning-augmented algorithms -- in which, traditional algorithms are augmented with machine-learned predictions -- have emerged as a framework to go beyond worst-case analysis. The overarching goal is to design algorithms that perform near-optimally when the predictions are accurate yet retain certain worst-case guarantees irrespective of the accuracy of the predictions. This framework has been successfully applied to online problems such as caching where the predictions can be used to alleviate uncertainties. In this paper we introduce and study the setting in which the learning-augmented algorithm can utilize the predictions parsimoniously. We consider the caching problem -- which has been extensively studied in the learning-augmented setting -- and show that one can achieve quantitatively similar results but only using a sublinear number of predictions.
Logarithmic Regret from Sublinear Hints
Nov 09, 2021We consider the online linear optimization problem, where at every step the algorithm plays a point $x_t$ in the unit ball, and suffers loss $\langle c_t, x_t\rangle$ for some cost vector $c_t$ that is then revealed to the algorithm. Recent work showed that if an algorithm receives a hint $h_t$ that has non-trivial correlation with $c_t$ before it plays $x_t$, then it can achieve a regret guarantee of $O(\log T)$, improving on the bound of $\Theta(\sqrt{T})$ in the standard setting. In this work, we study the question of whether an algorithm really requires a hint at every time step. Somewhat surprisingly, we show that an algorithm can obtain $O(\log T)$ regret with just $O(\sqrt{T})$ hints under a natural query model; in contrast, we also show that $o(\sqrt{T})$ hints cannot guarantee better than $\Omega(\sqrt{T})$ regret. We give two applications of our result, to the well-studied setting of optimistic regret bounds and to the problem of online learning with abstention.
Upper Confidence Bounds for Combining Stochastic Bandits
Dec 24, 2020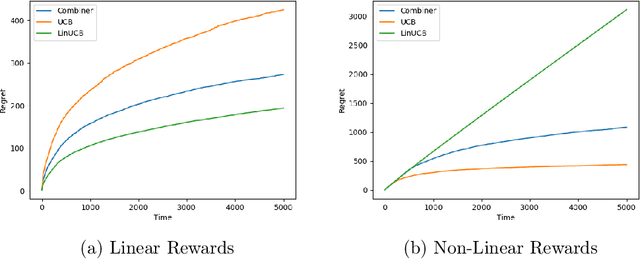
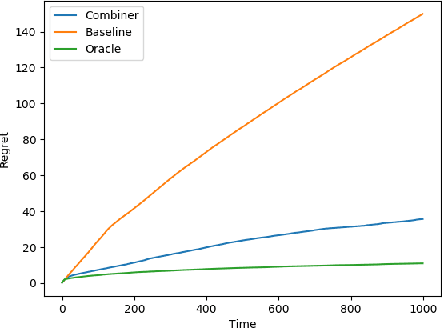
We provide a simple method to combine stochastic bandit algorithms. Our approach is based on a "meta-UCB" procedure that treats each of $N$ individual bandit algorithms as arms in a higher-level $N$-armed bandit problem that we solve with a variant of the classic UCB algorithm. Our final regret depends only on the regret of the base algorithm with the best regret in hindsight. This approach provides an easy and intuitive alternative strategy to the CORRAL algorithm for adversarial bandits, without requiring the stability conditions imposed by CORRAL on the base algorithms. Our results match lower bounds in several settings, and we provide empirical validation of our algorithm on misspecified linear bandit and model selection problems.
Online Linear Optimization with Many Hints
Oct 06, 2020We study an online linear optimization (OLO) problem in which the learner is provided access to $K$ "hint" vectors in each round prior to making a decision. In this setting, we devise an algorithm that obtains logarithmic regret whenever there exists a convex combination of the $K$ hints that has positive correlation with the cost vectors. This significantly extends prior work that considered only the case $K=1$. To accomplish this, we develop a way to combine many arbitrary OLO algorithms to obtain regret only a logarithmically worse factor than the minimum regret of the original algorithms in hindsight; this result is of independent interest.
Online Learning with Imperfect Hints
Feb 11, 2020We consider a variant of the classical online linear optimization problem in which at every step, the online player receives a "hint" vector before choosing the action for that round. Rather surprisingly, it was shown that if the hint vector is guaranteed to have a positive correlation with the cost vector, then the online player can achieve a regret of $O(\log T)$, thus significantly improving over the $O(\sqrt{T})$ regret in the general setting. However, the result and analysis require the correlation property at \emph{all} time steps, thus raising the natural question: can we design online learning algorithms that are resilient to bad hints? In this paper we develop algorithms and nearly matching lower bounds for online learning with imperfect directional hints. Our algorithms are oblivious to the quality of the hints, and the regret bounds interpolate between the always-correlated hints case and the no-hints case. Our results also generalize, simplify, and improve upon previous results on optimistic regret bounds, which can be viewed as an additive version of hints.
On Correcting Inputs: Inverse Optimization for Online Structured Prediction
Oct 12, 2015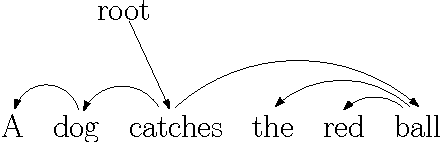
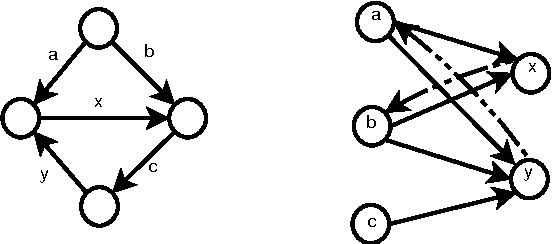
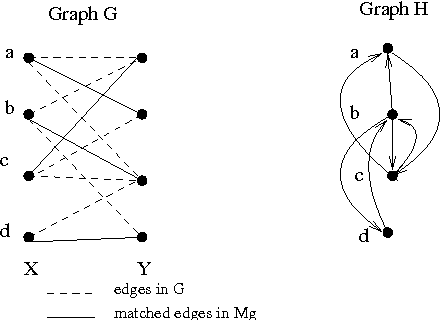
Algorithm designers typically assume that the input data is correct, and then proceed to find "optimal" or "sub-optimal" solutions using this input data. However this assumption of correct data does not always hold in practice, especially in the context of online learning systems where the objective is to learn appropriate feature weights given some training samples. Such scenarios necessitate the study of inverse optimization problems where one is given an input instance as well as a desired output and the task is to adjust the input data so that the given output is indeed optimal. Motivated by learning structured prediction models, in this paper we consider inverse optimization with a margin, i.e., we require the given output to be better than all other feasible outputs by a desired margin. We consider such inverse optimization problems for maximum weight matroid basis, matroid intersection, perfect matchings, minimum cost maximum flows, and shortest paths and derive the first known results for such problems with a non-zero margin. The effectiveness of these algorithmic approaches to online learning for structured prediction is also discussed.