 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioned Language Policy: A General Framework for Steerable Multi-Objective Finetuning
Jul 22, 2024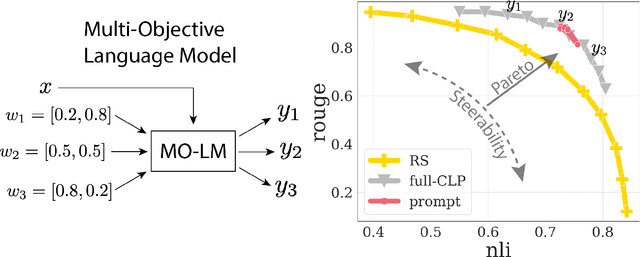
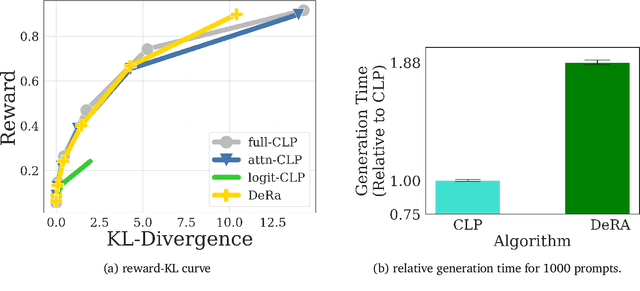
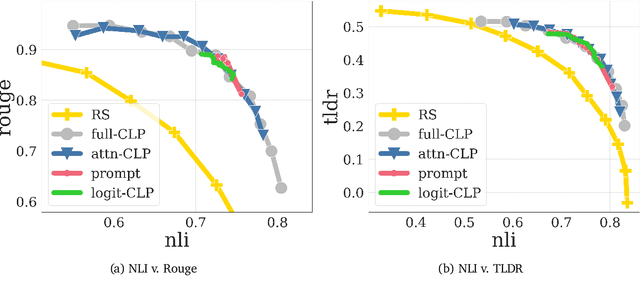
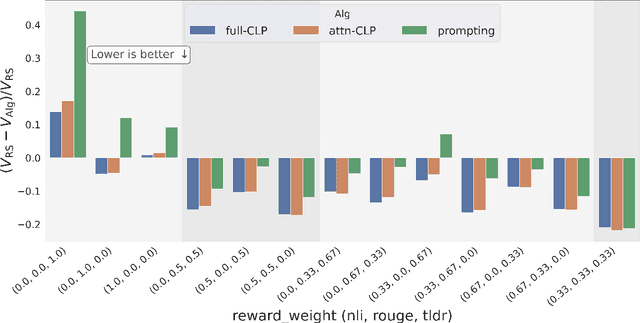
Reward-based finetuning is crucial for aligning language policies with intended behaviors (e.g., creativity and safety). A key challenge here is to develop steerable language models that trade-off multiple (conflicting) objectives in a flexible and efficient manner. This paper presents Conditioned Language Policy (CLP), a general framework for finetuning language models on multiple objectives. Building on techniques from multi-task training and parameter-efficient finetuning, CLP can learn steerable models that effectively trade-off conflicting objectives at inference time. Notably, this does not require training or maintaining multiple models to achieve different trade-offs between the objectives. Through an extensive set of experiments and ablations, we show that the CLP framework learns steerable models that outperform and Pareto-dominate the current state-of-the-art approaches for multi-objective finetuning.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Diversifying AI: Towards Creative Chess with AlphaZero
Aug 29, 2023



In recent years, Artificial Intelligence (AI) systems have surpassed human intelligence in a variety of computational tasks. However, AI systems, like humans, make mistakes, have blind spots, hallucinate, and struggle to generalize to new situations. This work explores whether AI can benefit from creative decision-making mechanisms when pushed to the limits of its computational rationality. In particular, we investigate whether a team of diverse AI systems can outperform a single AI in challenging tasks by generating more ideas as a group and then selecting the best ones. We study this question in the game of chess, the so-called drosophila of AI. We build on AlphaZero (AZ) and extend it to represent a league of agents via a latent-conditioned architecture, which we call AZ_db. We train AZ_db to generate a wider range of ideas using behavioral diversity techniques and select the most promising ones with sub-additive planning. Our experiments suggest that AZ_db plays chess in diverse ways, solves more puzzles as a group and outperforms a more homogeneous team. Notably, AZ_db solves twice as many challenging puzzles as AZ, including the challenging Penrose positions. When playing chess from different openings, we notice that players in AZ_db specialize in different openings, and that selecting a player for each opening using sub-additive planning results in a 50 Elo improvement over AZ. Our findings suggest that diversity bonuses emerge in teams of AI agents, just as they do in teams of humans and that diversity is a valuable asset in solving computationally hard problems.
Optimizing Memory Mapping Using Deep Reinforcement Learning
May 11, 2023



Resource scheduling and allocation is a critical component of many high impact systems ranging from congestion control to cloud computing. Finding more optimal solutions to these problems often has significant impact on resource and time savings, reducing device wear-and-tear, and even potentially improving carbon emissions. In this paper, we focus on a specific instance of a scheduling problem, namely the memory mapping problem that occurs during compilation of machine learning programs: That is, mapping tensors to different memory layers to optimize execution time. We introduce an approach for solving the memory mapping problem using Reinforcement Learning. RL is a solution paradigm well-suited for sequential decision making problems that are amenable to planning, and combinatorial search spaces with high-dimensional data inputs. We formulate the problem as a single-player game, which we call the mallocGame, such that high-reward trajectories of the game correspond to efficient memory mappings on the target hardware. We also introduce a Reinforcement Learning agent, mallocMuZero, and show that it is capable of playing this game to discover new and improved memory mapping solutions that lead to faster execution times on real ML workloads on ML accelerators. We compare the performance of mallocMuZero to the default solver used by the Accelerated Linear Algebra (XLA) compiler on a benchmark of realistic ML workloads. In addition, we show that mallocMuZero is capable of improving the execution time of the recently published AlphaTensor matrix multiplication model.
Fast active learning for pure exploration in reinforcement learning
Jul 27, 2020
Realistic environments often provide agents with very limited feedback. When the environment is initially unknown, the feedback, in the beginning, can be completely absent, and the agents may first choose to devote all their effort on exploring efficiently. The exploration remains a challenge while it has been addressed with many hand-tuned heuristics with different levels of generality on one side, and a few theoretically-backed exploration strategies on the other. Many of them are incarnated by intrinsic motivation and in particular explorations bonuses. A common rule of thumb for exploration bonuses is to use $1/\sqrt{n}$ bonus that is added to the empirical estimates of the reward, where $n$ is a number of times this particular state (or a state-action pair) was visited. We show that, surprisingly, for a pure-exploration objective of reward-free exploration, bonuses that scale with $1/n$ bring faster learning rates, improving the known upper bounds with respect to the dependence on the horizon $H$. Furthermore, we show that with an improved analysis of the stopping time, we can improve by a factor $H$ the sample complexity in the best-policy identification setting, which is another pure-exploration objective, where the environment provides rewards but the agent is not penalized for its behavior during the exploration phase.
Adaptive Reward-Free Exploration
Jun 11, 2020
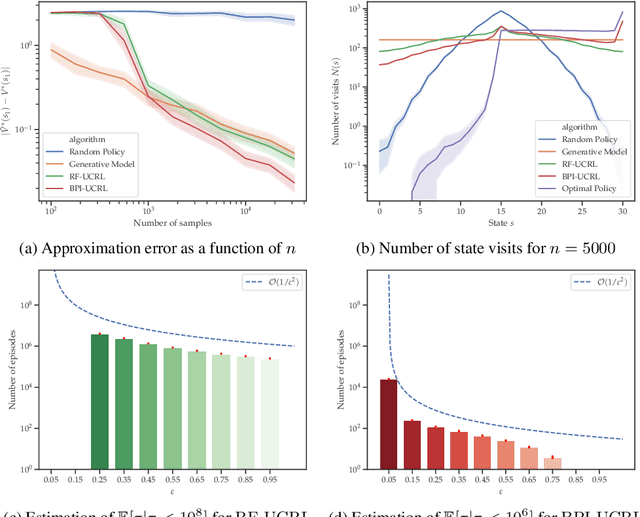
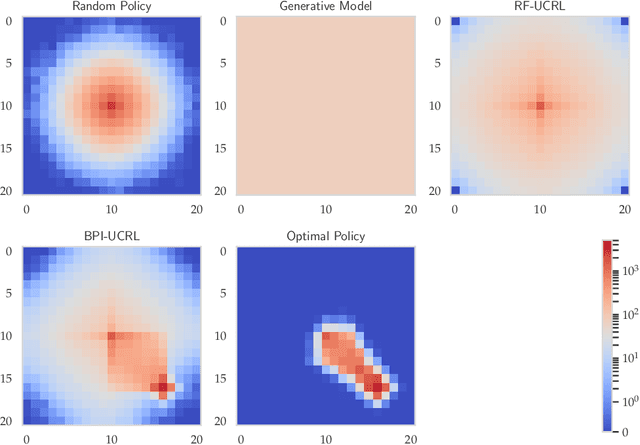
Reward-free exploration is a reinforcement learning setting recently studied by Jin et al., who address it by running several algorithms with regret guarantees in parallel. In our work, we instead propose a more adaptive approach for reward-free exploration which directly reduces upper bounds on the maximum MDP estimation error. We show that, interestingly, our reward-free UCRL algorithm can be seen as a variant of an algorithm of Fiechter from 1994, originally proposed for a different objective that we call best-policy identification. We prove that RF-UCRL needs $\mathcal{O}\left(({SAH^4}/{\varepsilon^2})\ln(1/\delta)\right)$ episodes to output, with probability $1-\delta$, an $\varepsilon$-approximation of the optimal policy for any reward function. We empirically compare it to oracle strategies using a generative model.
Planning in Markov Decision Processes with Gap-Dependent Sample Complexity
Jun 10, 2020
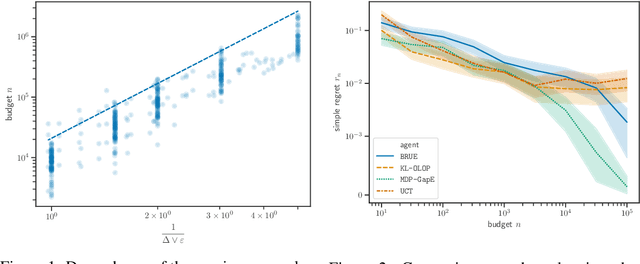


We propose MDP-GapE, a new trajectory-based Monte-Carlo Tree Search algorithm for planning in a Markov Decision Process in which transitions have a finite support. We prove an upper bound on the number of calls to the generative models needed for MDP-GapE to identify a near-optimal action with high probability. This problem-dependent sample complexity result is expressed in terms of the sub-optimality gaps of the state-action pairs that are visited during exploration. Our experiments reveal that MDP-GapE is also effective in practice, in contrast with other algorithms with sample complexity guarantees in the fixed-confidence setting, that are mostly theoretical.
Robust Estimation, Prediction and Control with Linear Dynamics and Generic Costs
Feb 25, 2020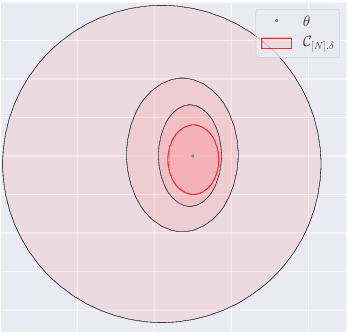
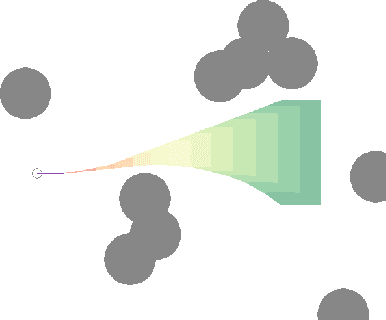

We develop a framework for the adaptive model predictive control of a linear system with unknown parameters and arbitrary bounded costs, in a critical setting where failures are costly and should be prevented at all time. Our approach builds on two ideas: first, we incorporate prior knowledge of the dynamics in the form of a known structure that shapes uncertainty, which can be tightened as we collect interaction data by building high-confidence regions through least-square regression. Second, in order to handle this uncertainty we formulate a robust control objective. Leveraging tools from the interval prediction literature, we convert the confidence regions on parameters into confidence sets on trajectories induced by the controls. These controls are then optimised resorting to tree-based planning methods. We eventually relax our modeling assumptions with a multi-model extension based on a data-driven robust model selection mechanism. The full procedure is designed to produce reasonable and safe behaviours at deployment while recovering an asymptotic optimality. We illustrate it on a practical case of autonomous driving at a crossroads intersection among vehicles with uncertain behaviours.
Social Attention for Autonomous Decision-Making in Dense Traffic
Nov 27, 2019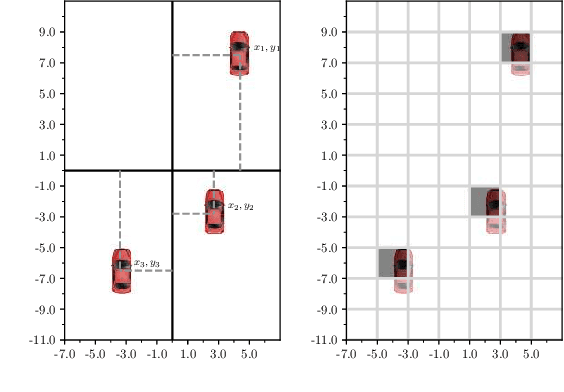


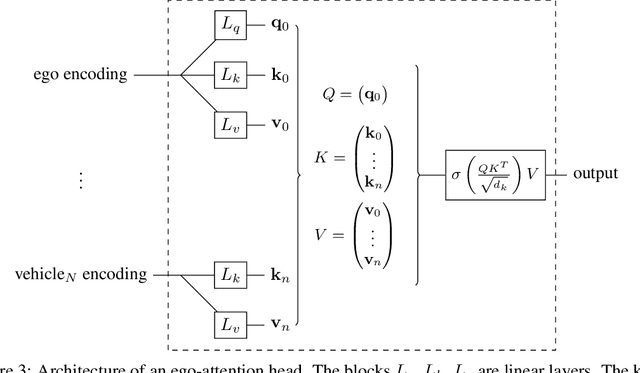
We study the design of learning architectures for behavioural planning in a dense traffic setting. Such architectures should deal with a varying number of nearby vehicles, be invariant to the ordering chosen to describe them, while staying accurate and compact. We observe that the two most popular representations in the literature do not fit these criteria, and perform badly on an complex negotiation task. We propose an attention-based architecture that satisfies all these properties and explicitly accounts for the existing interactions between the traffic participants. We show that this architecture leads to significant performance gains, and is able to capture interactions patterns that can be visualised and qualitatively interpreted. Videos and code are available at https://eleurent.github.io/social-attention/.
Practical Open-Loop Optimistic Planning
Apr 09, 2019


We consider the problem of online planning in a Markov Decision Process when given only access to a generative model, restricted to open-loop policies - i.e. sequences of actions - and under budget constraint. In this setting, the Open-Loop Optimistic Planning (OLOP) algorithm enjoys good theoretical guarantees but is overly conservative in practice, as we show in numerical experiments. We propose a modified version of the algorithm with tighter upper-confidence bounds, KLOLOP, that leads to better practical performances while retaining the sample complexity bound. Finally, we propose an efficient implementation that significantly improves the time complexity of both algorithms.